
原文链接:https://zhuanlan.zhihu.com/p/2012118521371455986
在计算机视觉领域,脉冲神经网络(Spiking Neural Networks, SNNs)一直被寄予厚望。由于其模拟生物神经元的脉冲发射机制,具有极高的能效比,被认为是实现边缘侧智能视觉的理想选择。然而,在 RGB 目标跟踪这一任务上,SNN 却长期面临“精度与效率不可兼得”的尴尬境地。
近日,来自同济大学、斯德哥尔摩大学、上海大学以及日本富山大学等机构的研究团队提出了一种名为 SpikeTrack 的新型脉冲驱动跟踪框架。该模型被命名为 “SpikeTrack”,意在强调其完全基于脉冲驱动(Spike-driven)的计算范式,并专为视觉跟踪(Tracking)任务优化。它通过非对称的脉冲暹罗(Siamese)架构和受大脑启发的记忆检索模块,第一次在 RGB 跟踪任务中实现了高精度与超低能耗的平衡。

- 论文地址: https://arxiv.org/abs/2602.23963
- 代码仓库: https://github.com/faicaiwawa/SpikeTrack (已开源)
- 录用会议: CVPR 2026
背景与动机:SNN 跟踪的“两难”困境
传统的类神经网络(Artificial Neural Networks, ANNs)虽然精度高,但在嵌入式或边缘设备上运行时,巨大的功耗一直是痛点。SNN 通过离散的脉冲信号进行计算,只有在有脉冲时才触发运算,且复杂的乘法可以转换为稀疏的加法,理论上能节省大量能源。
但在 RGB 跟踪领域,现有的 SNN 方案存在两个主要问题:
- “脉冲”不纯粹:一些方法在计算过程中将脉冲信号解码回连续值,破坏了脉冲驱动的特性,导致能效下降。
- 架构冗余:直接模仿 ANN 的“单流(One-stream)”架构在 SNN 中会产生巨大的计算开销。正如论文中提到的,单流架构将模板和搜索区域拼接在一起处理,虽然交互充分,但忽略了 SNN 擅长的时空动态建模能力。
为了解决这些问题,SpikeTrack 团队从生物视觉感知中汲取灵感,设计了一套全新的非对称交互机制,试图在保持脉冲驱动纯粹性的同时,榨干 SNN 的性能潜力。
方法详解:非对称架构与记忆检索
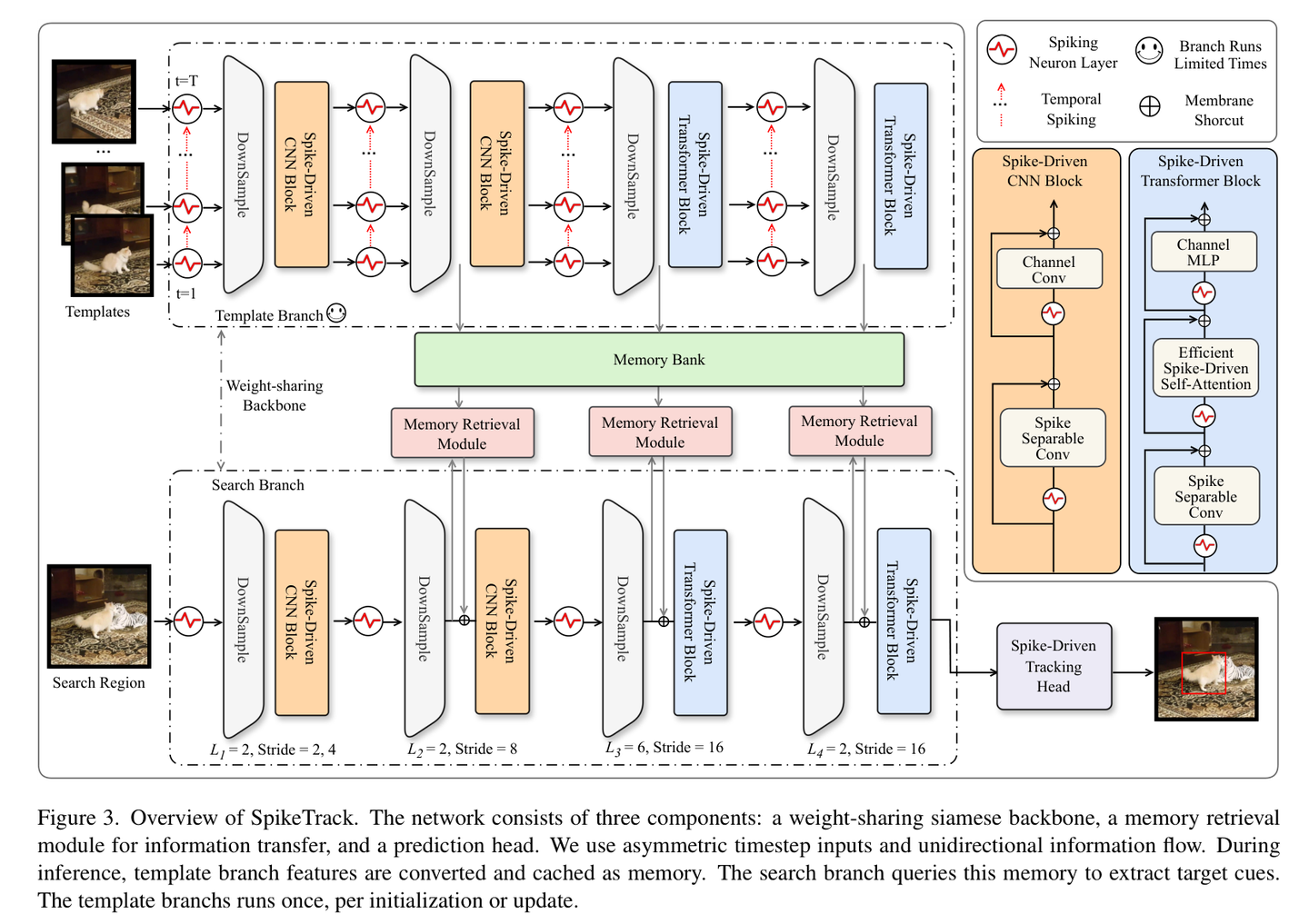
SpikeTrack 的核心由三个部分组成:共享权重的脉冲骨干网络(Spiking Backbone)、记忆检索模块(Memory Retrieval Module, MRM)以及预测头。
1. 骨干网络:从 CNN 到 Transformer 的脉冲演变
SpikeTrack 采用了 Spike-Driven Transformer v3 作为骨干网络。这是一个典型的元架构(Meta-Transformer),它将网络分为四个阶段:
- 前两个阶段:采用基于卷积的脉冲块(CNN-based SNN blocks),利用脉冲深度可分离卷积(Spike Separable Convolution)提取局部特征。
- 后两个阶段:引入了高效脉冲自注意力( E-SDSA),在长程建模上发挥优势。
Input/Output 流程:
- 输入:模板图像 (多时间步扩展)和搜索图像 (单时间步)。
- 输出:经过多层特征提取和 MRM 增强后的搜索区域特征,用于最终的边界框预测。
2. 归一化整数 LIF 神经元
为了在训练中保持稳定并在推理时实现纯脉冲计算,模型采用了归一化整数漏电整合发放(Normalized Integer Leaky Integrate-and-Fire, NI-LIF)神经元。其核心动力学方程如下:
其中, 是膜电位, 是空间输入,而 是一个可学习的漏电因子。通过让 可学习,网络可以自适应地调节不同时间步之间的关联,这比传统的固定漏电因子更能捕捉目标在时间维度上的细微变化。
3. 非对称 Siamese 设计
这是 SpikeTrack 提升效率的神来之笔。
- 模板分支:采用多时间步()输入,利用神经元的时空动态特性来联合建模目标的特征表示。
- 搜索分支:仅进行单时间步推理。
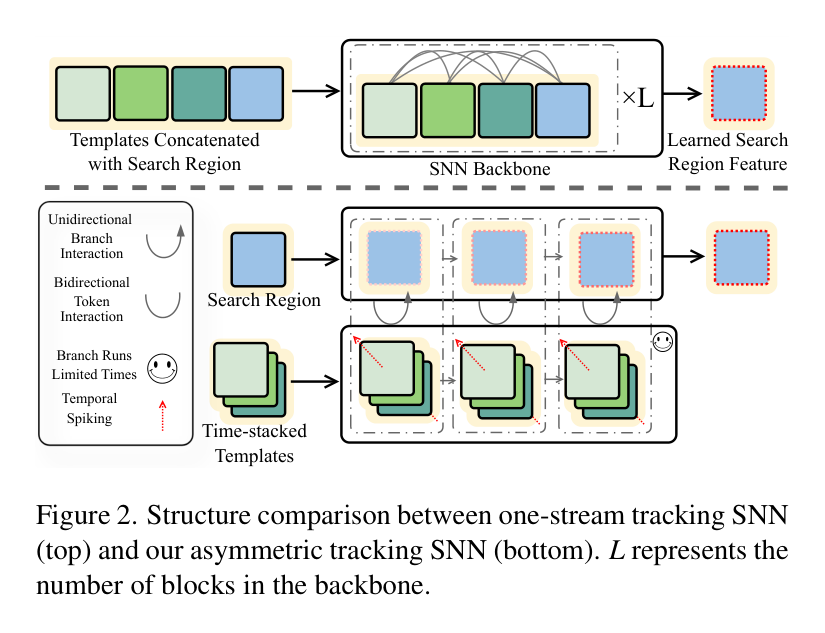
这种设计的精妙之处在于,计算量较大的模板分支只在初始化或模板更新时运行一次,其特征会被缓存。而每帧都在运行的搜索分支保持轻量化,从而大幅削减了整体功耗。
4. 大脑启发的记忆检索模块 (MRM)
研究者参考了大脑皮层 V1 区域 L2/3 层的循环连接机制,设计了 MRM 模块。该机制认为,人类在观察遮挡物体时,会通过反馈连接不断细化感知。
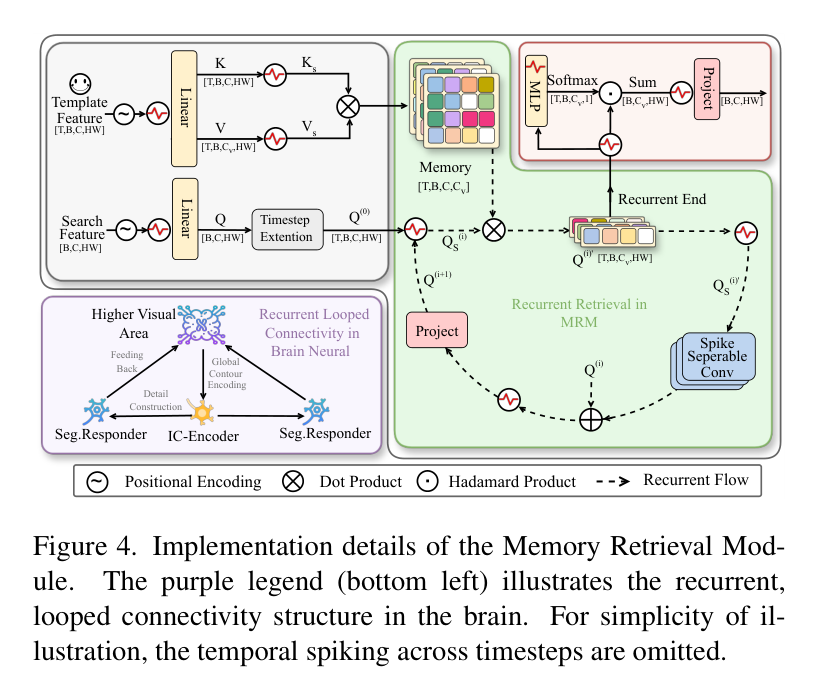
MRM 的工作流程分为三个阶段:
- 全局轮廓编码:搜索分支的 Query 张量 通过与预计算的记忆矩阵 进行线性检索,快速获取目标的大致方位。
- 细节构建:利用时间维度上独立的脉冲卷积(SSConv)处理检索到的信号,增强对局部细节的敏感度。
- 反馈细化:通过残差连接模拟大脑的高级反馈,经过循环迭代(Loop),使目标特征“越看越清晰”。
由于去除了 Softmax 函数,这种检索机制具有线性复杂度 ,在处理高分辨率特征时比传统 Transformer 快得多。
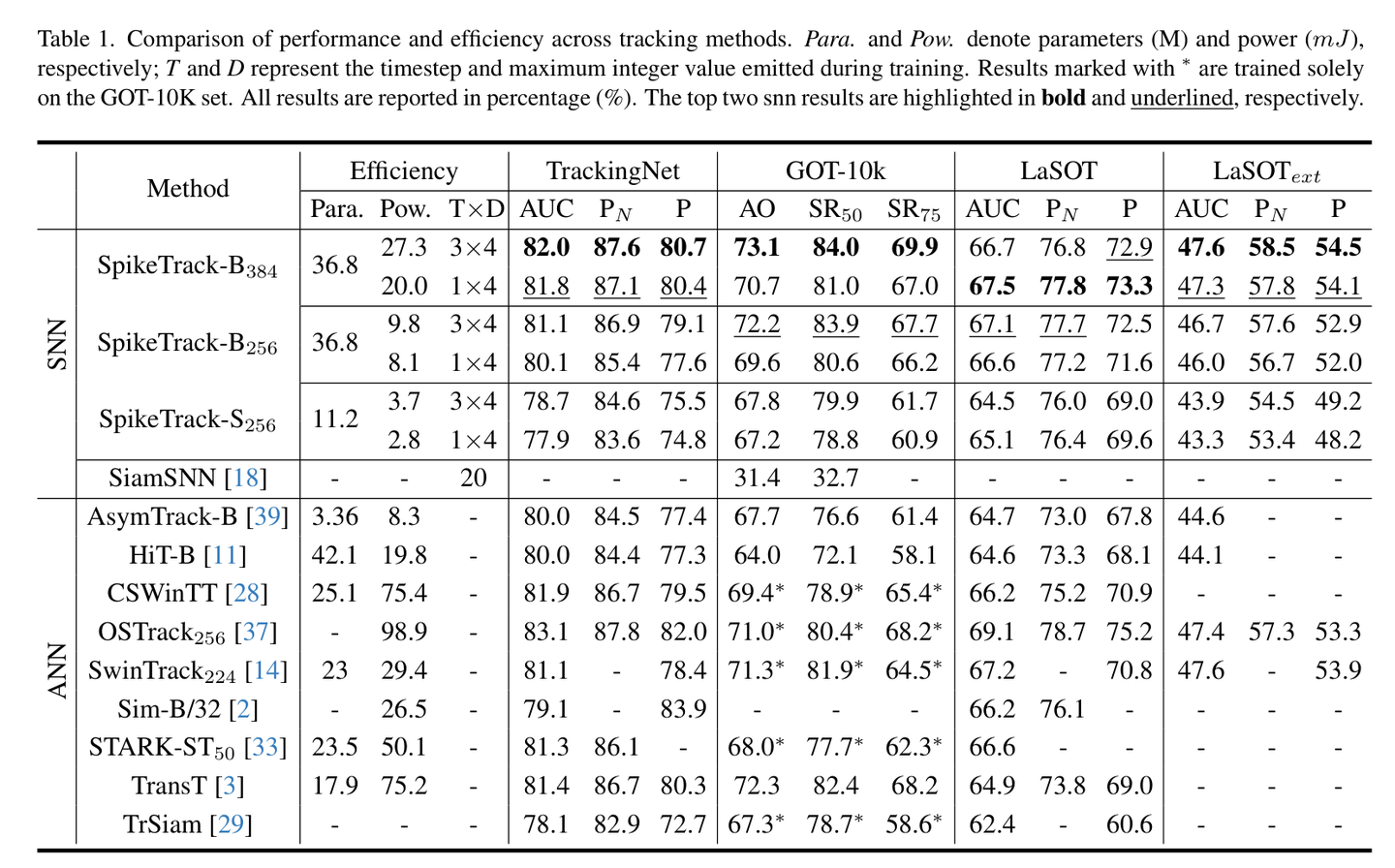
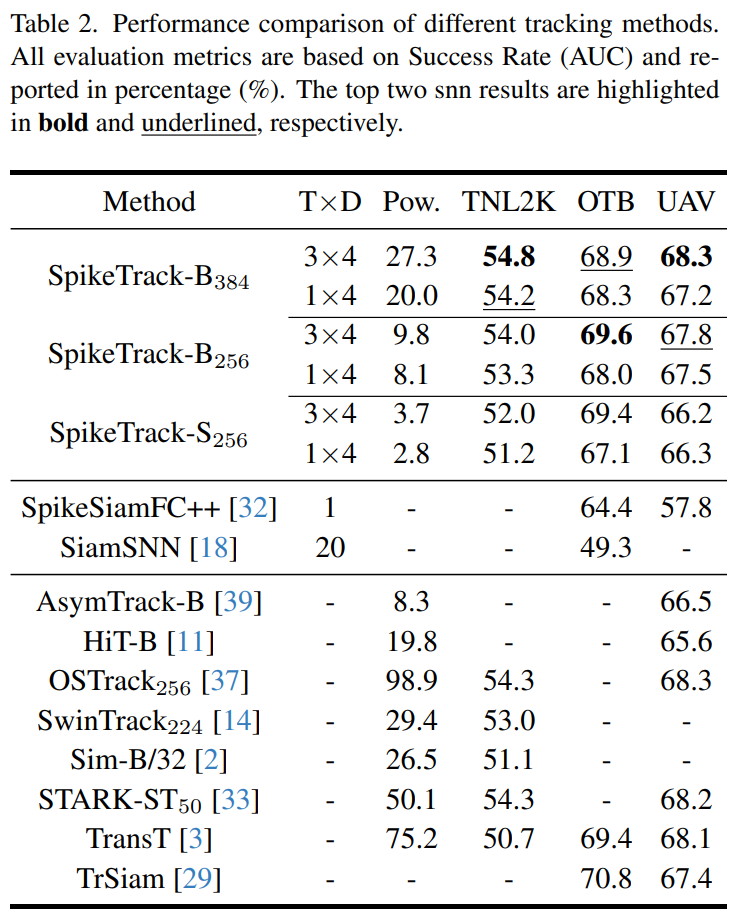
实验结果:以 1/26 的能耗实现性能反超
研究团队在 LaSOT、GOT-10k、TrackingNet 等多个主流基准数据集上进行了详尽的测试,并使用了 8 张 NVIDIA 4090 GPU 进行训练。
1. 惊人的能效比
在 LaSOT 数据集上,SpikeTrack-B256 的 AUC 达到了 67.1%,不仅超过了经典的 Transformer 跟踪器 TransT(64.9%),其功耗更是低得惊人。
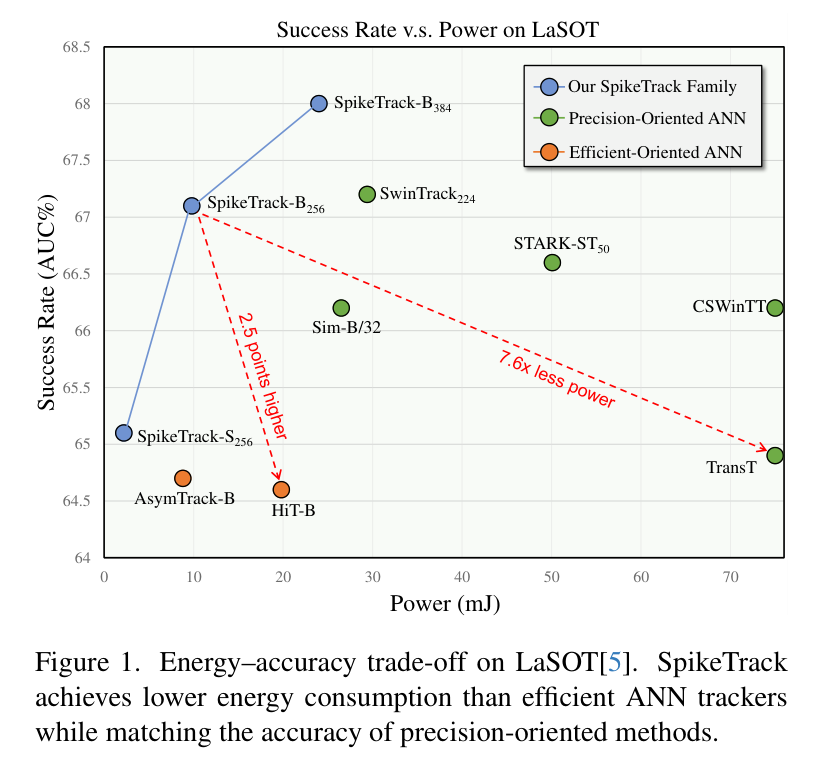
从图 1 可以直观看到,SpikeTrack 家族(红色星号)位于图表的左上方。具体数据上,SpikeTrack-B256 的能耗仅为 TransT 的 1/26。这意味着在相同的电池容量下,搭载 SpikeTrack 的设备续航时间可以延长数十倍。
2. 广泛的性能领先
在与其他 SNN 跟踪器的对比中,SpikeTrack 展现了压制性的优势:
- GOT-10k:SpikeTrack-B256 的 AO 指标达到了 72.2%,相比之前的 SpikeSiamFC++ 提升了 8.5%。
- TrackingNet:AUC 达到 81.1%,性能追平了高性能 ANN 跟踪器 SwinTrack,但能耗仅为其 1/3。
- TNL2K:在这一极具挑战性的长视频数据集上,SpikeTrack-B384 取得了 54.8% 的成功率,甚至超越了强大的单流跟踪器 OSTrack。
3. 可视化分析:循环的力量
通过可视化 MRM 产生的脉冲张量,我们可以清晰地看到循环检索的效果。在面对遮挡或背景干扰时,第一次检索可能还存在噪声,但随着循环次数增加,脉冲发放逐渐集中在目标中心。

此外,论文还分析了 SpikeTrack 与精度导向型跟踪器(如 OSTrack)的差距。发现在“快速运动”和“变形”场景下,SNN 仍有提升空间。作者认为,这主要是因为脉冲信号的二值化特性在传递极细粒度的语义信息时存在天然挑战。
写在最后
SpikeTrack 的出现,为 RGB 视觉跟踪提供了一个极具竞争力的“脉冲驱动”新基准。它最核心的价值在于证明了:通过合理的非对称架构设计,SNN 完全可以在不牺牲精度的情况下,释放出其理论上的超低功耗潜力。
这种研究思路,不仅在学术指标上刷新了记录,更在实用性上迈出了一大步。对于希望在低功耗嵌入式设备(如无人机、智能穿戴)上实现实时跟踪的开发者来说,SpikeTrack 提供了一个现成的、高性能的开源方案。
发表回复