
原文链接:https://zhuanlan.zhihu.com/p/2010819320008184239
北京交通大学与小米汽车联合团队提出的 DriveWorld-VLA,直击当前自动驾驶决策规划中VLA(视觉-语言-动作模型)与世界模型融合的两大核心困局:
- 解耦交互(Disentangled Interaction)的知识壁垒:传统方案常将世界模型视为外部模拟器,导致VLA无法真正内化物理规律(如惯性、碰撞逻辑),决策时往往缺乏对环境本质的理解;
- 特征共享(Feature-Sharing)的因果缺失:部分方案虽共享表征,却缺乏基于动作的“What-if”推演能力,只能进行反应式规划,难以预判长时域风险(如路口会车)。
针对上述瓶颈,DriveWorld-VLA通过在潜在空间实现VLA与世界模型的深度绑定,首次将场景演化建模与动作规划纳入统一框架。
这一突破既解决了潜态共享不足的问题,又实现了可控的前瞻性想象,在多个权威基准上刷新SOTA性能,为端到端自动驾驶的决策优化提供了全新思路。
01 从“松散协同”到“潜空间统一”
DriveWorld-VLA的核心创新,在于打破了VLA与世界模型的结构边界,构建了“表征共享-推理联动-决策闭环”的一体化框架,其突破点集中在三个维度:
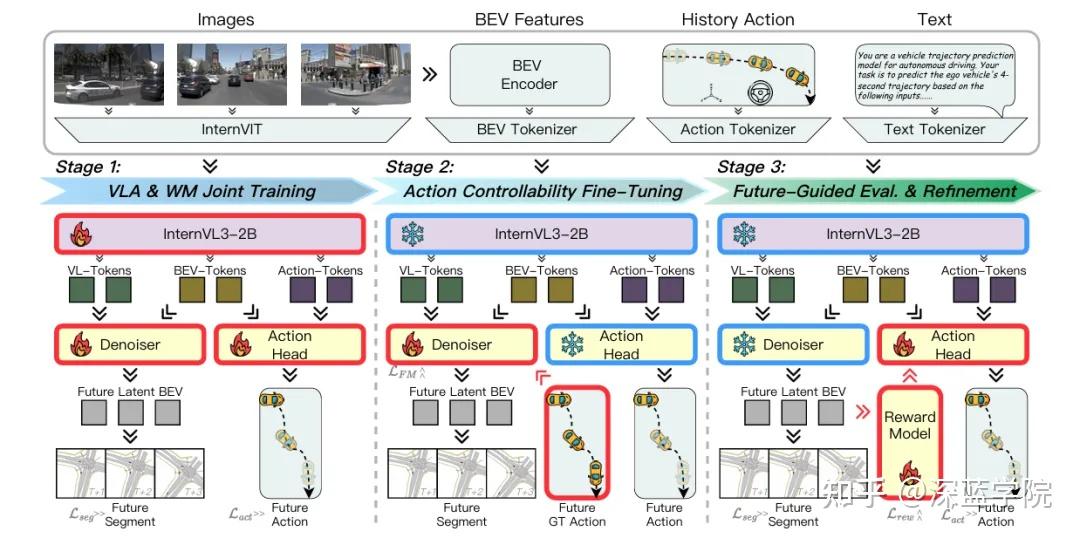
1. 特征级共享:用LLM潜态打通感知与想象
不同于传统的特征拼接或表层共享,DriveWorld-VLA将大型语言模型(LLM)的隐藏状态作为统一潜在空间,同时承载未来场景想象与动作预测两大核心任务。
多模态输入(多视图图像、BEV特征、文本指令、历史动作)经过专属Tokenizer编码后,共同送入VLM模型聚合为统一潜态表示:

这个公式的核心价值,是让物理规律(如车辆制动距离)、环境动力学(如行人行走轨迹)等底层知识,通过潜态空间直接融入VLA的决策过程,无需额外的跨模块适配,从根源上解决了知识传递效率低的问题。
2. 动作条件的“What-If”推理:从反应式到主动式规划
基于扩散Transformer(DiT)架构,DriveWorld-VLA实现了动作条件下的多轨迹前瞻性推演。模型不再局限于预测单一未来状态,而是针对多个候选动作生成对应的未来场景演化,通过评估不同动作的长期后果选择最优方案——比如面对前方慢车时,会同时推演“减速跟车”“安全变道”“紧急制动”三种动作对应的场景变化,最终选择兼顾安全与效率的轨迹。
这种设计的关键在于动作条件的流匹配去噪机制,通过将未来动作作为约束条件注入场景生成过程,让想象变得“可控可评估”,彻底摆脱了传统模型“见招拆招”的被动局面。
3. 三阶段渐进式训练:稳定联合优化的工程方案
VLA与世界模型的联合训练容易出现收敛困难、模态失衡等问题。DriveWorld-VLA设计了循序渐进的三阶段训练范式,既保证了各模块的专项优化,又实现了全局协同:
- 第一阶段(VLA & WM联合训练):同步学习未来BEV场景想象与动作预测,夯实多模态感知与潜态表征基础;
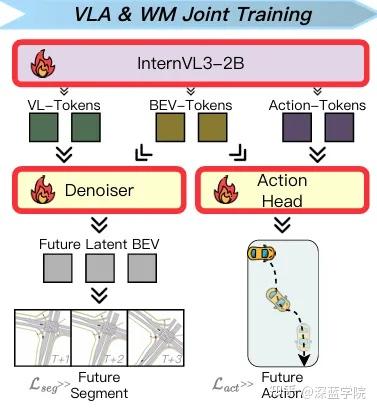
- 第二阶段(动作可控性微调):通过流匹配损失训练DiT架构,让模型学会“动作-场景”的映射关系,实现可控的未来想象;
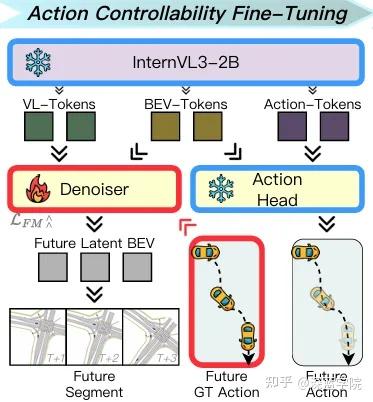
- 第三阶段(未来引导的评估与精修):构建闭环反馈机制,用预测动作生成未来场景,再通过奖励函数评估动作质量,反向优化决策模块。
这种“先基础、再可控、后闭环”的训练逻辑,有效避免了联合训练中的梯度震荡,让模型在感知精度、想象合理性与决策安全性之间找到平衡。
02 核心设计拆解
DriveWorld-VLA的性能优势,源于其在表征设计、推理架构和训练策略上的精细化打磨,三个核心设计共同构成了其技术护城河:
1. 多模态Tokenization:让输入适配统一潜态空间
为了让异质多模态数据(图像、BEV、文本、动作)能高效融入LLM潜态空间,模型为不同输入设计了专属Tokenizer:
- 图像与文本:遵循InternVL的编码逻辑,通过自适应分块将图像转化为文本域视觉占位符令牌,确保视觉信息与文本指令的语义对齐;
- BEV特征:经BEVFormer提取后,通过空间扁平化投影至VLM嵌入空间,保留鸟瞰视角的全局环境信息;
- 历史动作:序列化为准自然语言提示,与文本导航指令拼接编码,让动作历史具备语义可解释性。
这种统一的Tokenization策略,避免了多模态数据融合时的信息丢失,为潜态空间的知识共享奠定了基础。
2. 双分支去噪器:兼顾历史依赖与动作可控
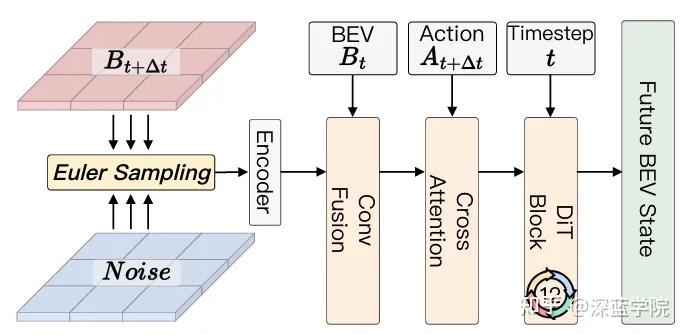
模型的去噪器(Denoiser)包含两个分支,分别承担不同功能:
- 历史条件分支:仅基于历史观测进行未来BEV预测,提供密集的未来监督信号,辅助多模态感知模块的训练;
- 动作条件分支:基于DiT架构的流匹配去噪器,以当前BEV状态和未来动作作为条件,学习“动作-场景”的映射关系。其核心损失函数为:

该公式的核心作用,是让模型学会根据特定动作精准生成对应的未来场景特征,从而实现“输入动作序列→输出场景演化”的可控想象,为后续的动作评估提供可靠依据。
3. 奖励引导的闭环精修:让决策学会“反思”
第三阶段的闭环机制是DriveWorld-VLA决策优化的关键。模型首先基于当前观测预测动作,再通过去噪器生成该动作对应的未来场景,随后由奖励函数R评估“动作-场景”的匹配度——奖励分数不仅考量轨迹的安全性(如是否碰撞、是否偏离车道),还兼顾效率(如行驶进度)与舒适性。
最终,模型将奖励分数作为权重,对动作预测损失进行加权优化:

这种设计让模型学会“反思”:如果某个动作会导致高风险或低效率的未来场景,就会在训练中被重点修正,从而逐步形成“预判-评估-优化”的决策闭环。
03 多基准SOTA
DriveWorld-VLA在closed-loop(NAVSIMv1、NAVSIMv2)和open-loop(nuScenes)三大权威基准上全面突破,其性能表现不仅验证了架构设计的有效性,更体现了实际应用价值:
1. NAVSIMv1:91.3 PDMS刷新闭环规划上限
NAVSIMv1是基于OpenScene数据集构建的闭环规划基准,核心指标PDMS综合考量无碰撞(NC)、可行驶区域合规(DAC)、碰撞时间(TTC)、行驶进度(EP)和舒适性(C)五大维度。DriveWorld-VLA以91.3的PDMS成绩远超所有对比方法:
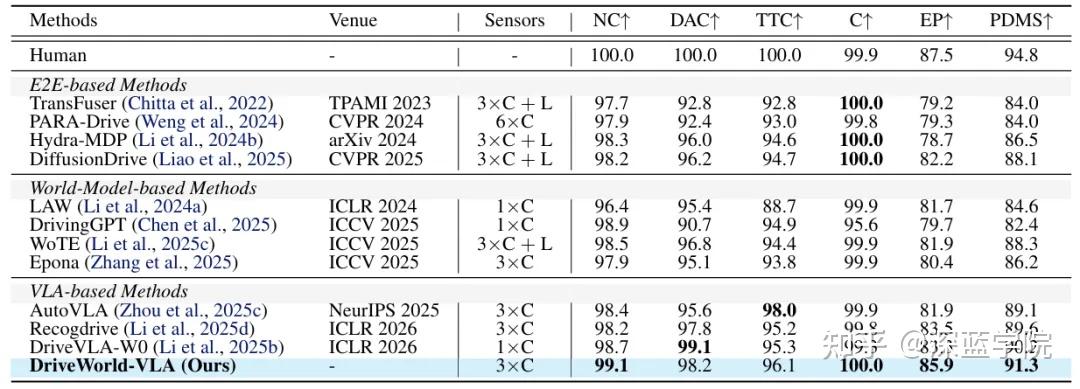
- 无碰撞率(NC)达99.1%,仅略低于人类驾驶(100%),展现了极强的风险规避能力;
- 行驶进度(EP)85.9%,在保障安全的同时兼顾行驶效率,避免了“过度保守”的决策;
- 舒适性(C)满分100%,说明模型能有效避免急加速、急刹车和急转弯,符合人类驾驶习惯。
值得注意的是,DriveWorld-VLA仅使用3个前视摄像头作为输入,而部分对比方法依赖LiDAR点云或多视角环绕摄像头,在硬件成本更低的情况下实现了更优性能,具备更强的工程落地潜力。
2. NAVSIMv2:86.8 EPDMS领跑复杂场景适应
NAVSIMv2在PDMS基础上新增了行驶方向合规(DDC)、交通灯合规(TLC)、车道保持(LK)等更严格的评估维度,更贴近真实道路场景。
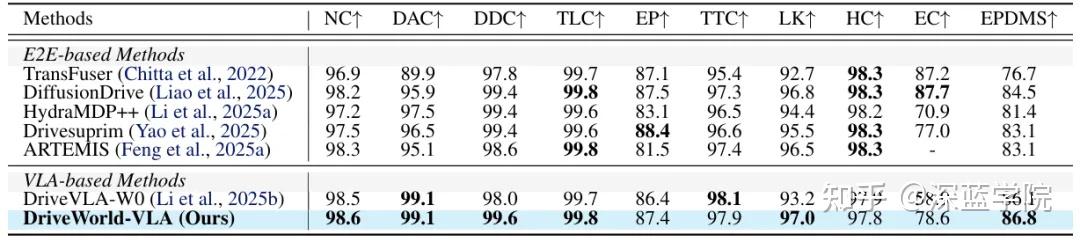
DriveWorld-VLA以86.8的EPDMS持续领跑,其中:
- 行驶方向合规(DDC)99.6%、车道保持(LK)97.0%,说明模型对交通规则的理解与执行能力突出;
- 无过错碰撞率(NC)98.6%、可行驶区域合规(DAC)99.1%,在多约束场景下仍能保持极高的安全性。
3. nuScenes:0.16%碰撞率彰显短时域规划优势
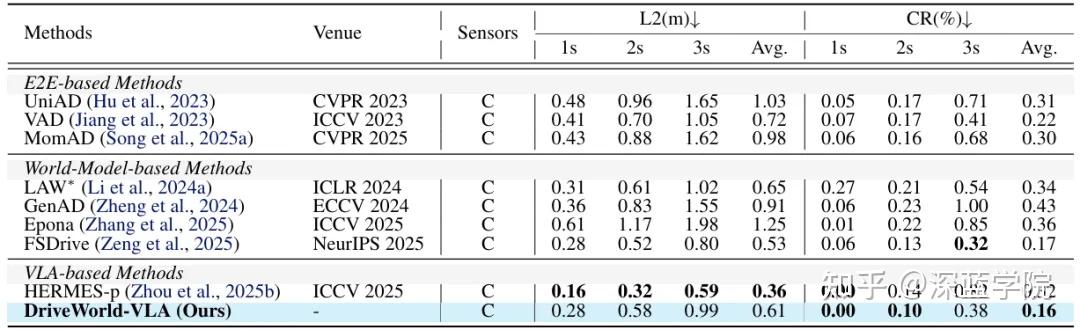
nuScenes是户外自动驾驶的主流open-loop基准,DriveWorld-VLA在禁用 ego-state 信息(车辆自身位置、速度等)的公平对比条件下,实现了0.61m的平均L2轨迹误差和0.16%的3秒平均碰撞率——这一碰撞率不仅大幅低于E2E和世界模型类基准方法,甚至超过了HERMES-p、FSDrive等专门优化短时域规划的SOTA模型,证明其决策策略的安全性具有普适性。
04 消融实验的关键发现
团队通过多组消融实验,验证了核心设计的必要性,其中三个结论尤为值得关注:
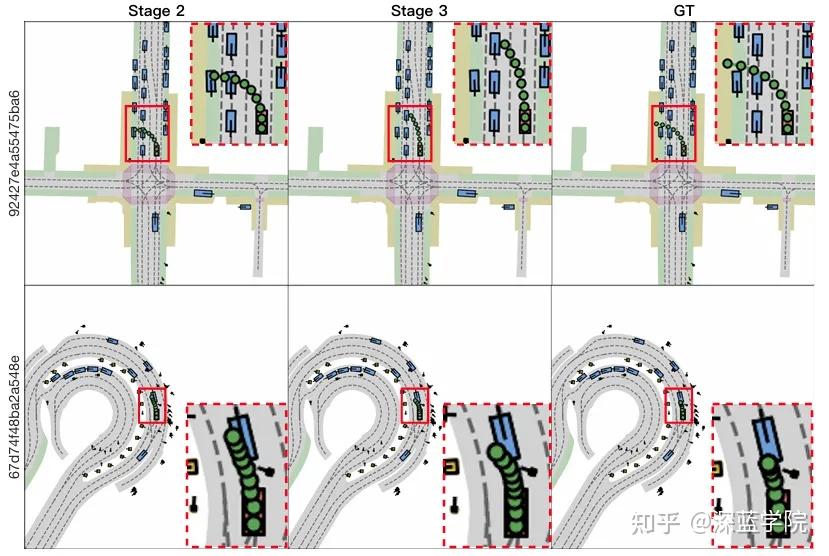
1. 渐进式训练是性能保障

若跳过渐进式流程,在第一阶段后直接同时训练第二、三阶段,模型PDMS会骤降7.7分(从91.3降至83.6)。这说明,模型必须先通过联合训练夯实多模态感知与潜态表征基础,再逐步解锁动作可控与闭环优化能力,否则会出现模态失衡或收敛困难。

2. VLM的动态优化不可少
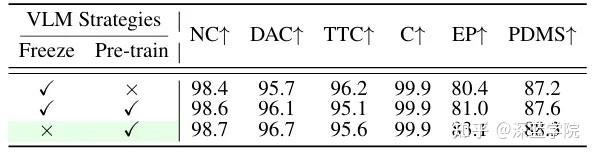
实验表明,仅冻结VLM参数或省略预训练微调,都会导致性能下降。最优策略是在第一阶段允许VLM参数参与优化,并结合3轮监督微调(SFT)——这能让VLM更好地适配自动驾驶场景的多模态数据,精准建模共享潜态空间的特征分布。
3. 特征级监督提升想象精度
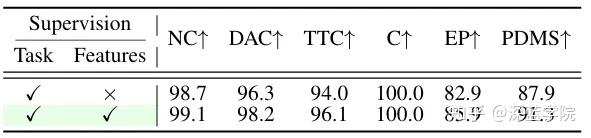
仅依赖任务级监督(如语义BEV解码、动作模仿学习)会导致模型缺乏细粒度特征 guidance,而弱化特征级监督(如去噪过程的流匹配损失)则会降低未来场景想象的准确性。两者的互补,是实现“精准想象-可靠决策”的前提。
05 未来展望

DriveWorld-VLA的核心价值,远不止于刷新各基准的SOTA成绩,更在于其提出了一套VLA与世界模型深度融合的完整方法论。
它以LLM潜态空间打破表征壁垒,依托DiT架构实现动作条件下的可控因果推理,通过三阶段渐进式训练保障联合优化稳定性,推动自动驾驶决策从“反应式”向“前瞻式”升级,也印证了端到端自动驾驶的决策优化,可通过架构创新实现“感知-推理-规划”的深度协同,而非单纯依赖复杂传感器或海量标注数据。
未来,随着动态场景适配、物理先验融入、轻量化技术等方向的技术突破,该模型所打造的“潜空间统一建模”思路,有望成为端到端自动驾驶领域的主流框架,为技术落地奠定核心基础。
Ref:
论文标题:DriveWorld-VLA: Unified Latent-Space World Modeling with Vision–Language–Action for Autonomous Driving
发表回复