
原文链接:https://zhuanlan.zhihu.com/p/2002337659834623053
在计算机视觉的世界里,YOLO 家族一直是“快、准、稳”的代名词。然而,传统的 YOLO 模型大多被困在“闭词汇(Closed-vocabulary)”的围城里——训练时见过什么,推理时才能认出什么。如果想让它识别一个从未见过的特殊零件、罕见的农作物病害,或者是特定品牌的产品,往往需要重新标注数据并经历漫长的重训练过程。
近日,来自康奈尔大学(Cornell University)的研究团队推出了全新的 YOLOE-26 框架,试图打破这一僵局。该模型被命名为 “YOLOE-26”,其中 “26” 代表它继承了 2025 年发布的 YOLO26 那种极致的推理效率和无 NMS(非极大值抑制)的端到端设计;而 “E” 则取自 “Everything”,源于 YOLOE(You Only Look Once – Everything) 范式(国内清华团队ICCV 2025作品),意在强调其“万物皆可识别”的开放词汇(Open-Vocabulary)能力。它不仅能听懂你的文字指令,还能根据你给出的参考图片,在复杂的场景中实时勾勒出目标物体的轮廓。
注意:本质上,本文是 YOLOv26 架构与 YOLOE 范式的一次“嫁接”。论文中的核心理念主要继承自 YOLOE,其主要贡献在于将这些先进范式高效地迁移到了最新的 YOLO26 端到端框架上。
关于性能对比:由于训练数据配置不同(YOLOE-26 引入了更复杂的伪掩码和多源数据),论文中并未直接与原版 YOLOE 进行同台竞技。唯一可以查到的对比数据,如下图:
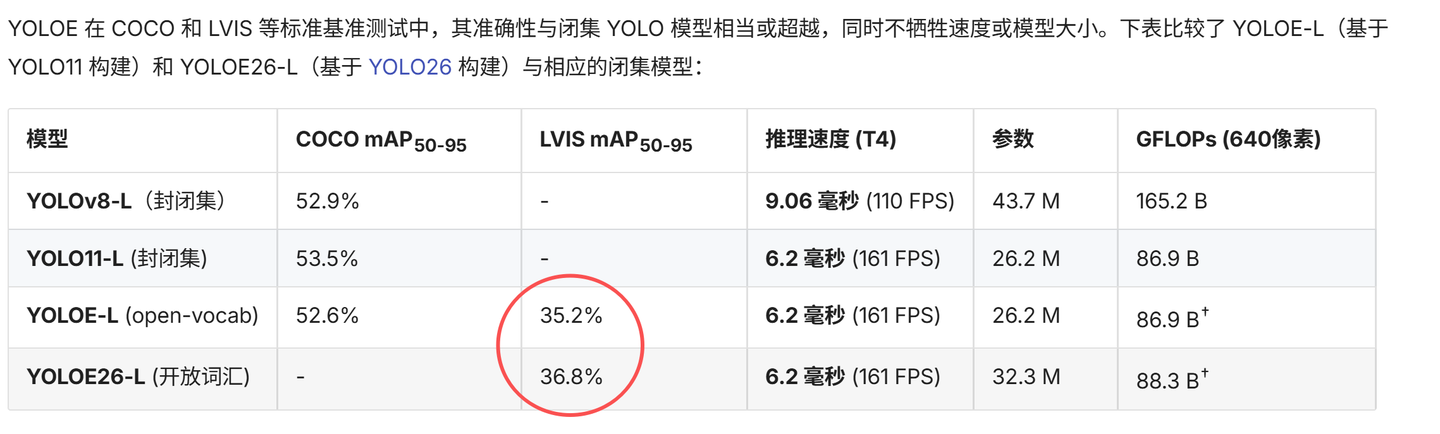
我们可以将其视为 YOLOE 在工业界的一次版本升级(能直接使用的那种),而非学术创新。

- 论文地址: YOLOE-26: Integrating YOLO26 with YOLOE for Real-Time Open-Vocabulary Instance Segmentation
- 论文地址:YOLOE-26: Integrating YOLO26 with YOLOE for Real-Time Open-Vocabulary Instance Segmentation
- 项目主页:https://docs.ultralytics.com/models/yolo26/
- 代码仓库:https://github.com/ultralytics/ultralytics(已集成至 Ultralytics 生态,开源状态:已开源)
从“认得全”到“认得活”:YOLOE-26 的诞生背景
回顾 YOLO 的发展史,核心逻辑一直在优化推理速度和部署效率。特别是 YOLO26,通过引入原生无 NMS 的端到端预测器,彻底解决了后处理带来的延迟抖动和计算开销。但在开放世界中,物体的类别是无穷无尽的,固定的分类头(Classification Head)限制了模型的灵活性。
现有的开放词汇模型(如 Grounding DINO 或 SAM)虽然强大,但往往依赖沉重的 Transformer 架构,很难在边缘设备上跑出实时速度。YOLOE-26 的初衷非常明确:能不能在保留 YOLO26 极致速度的同时,给它装上一个“语义大脑”?
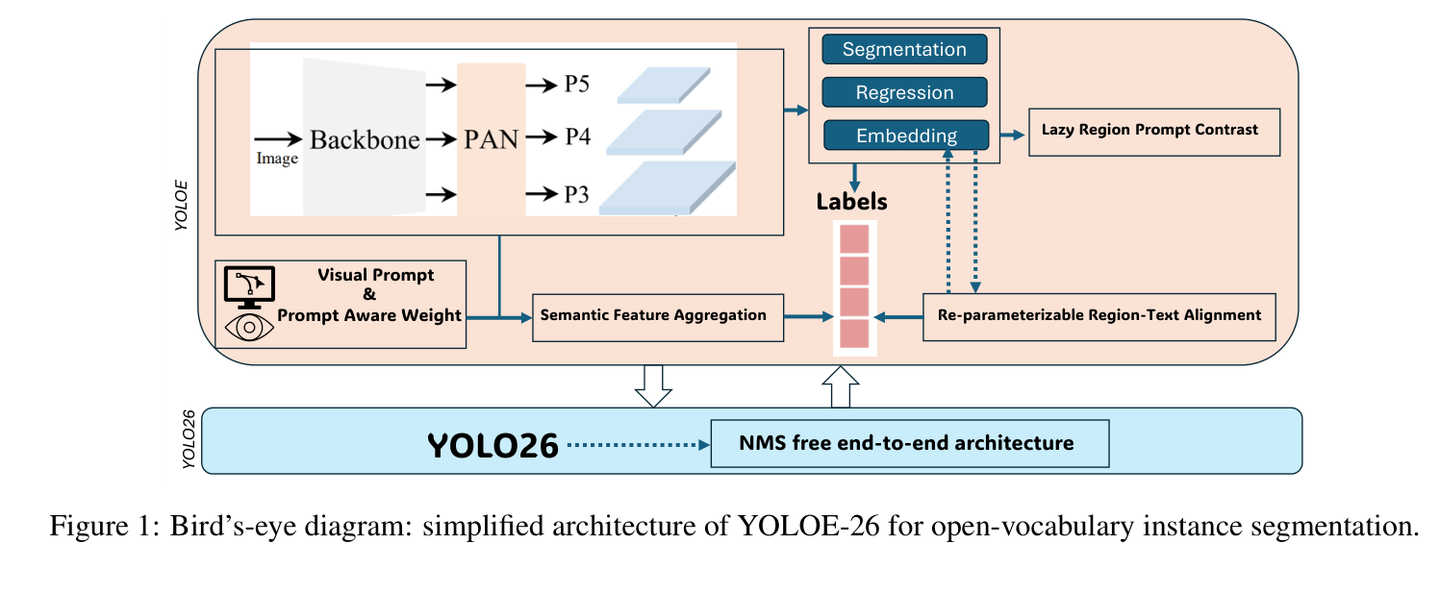
图 1:YOLOE-26 鸟瞰图,展示了其简化的开放词汇实例分割架构。
如上图所示,YOLOE-26 并没有增加架构的复杂度,而是通过一种“嵌入(Embedding)”的思路,将视觉特征与语义信息进行深度融合。
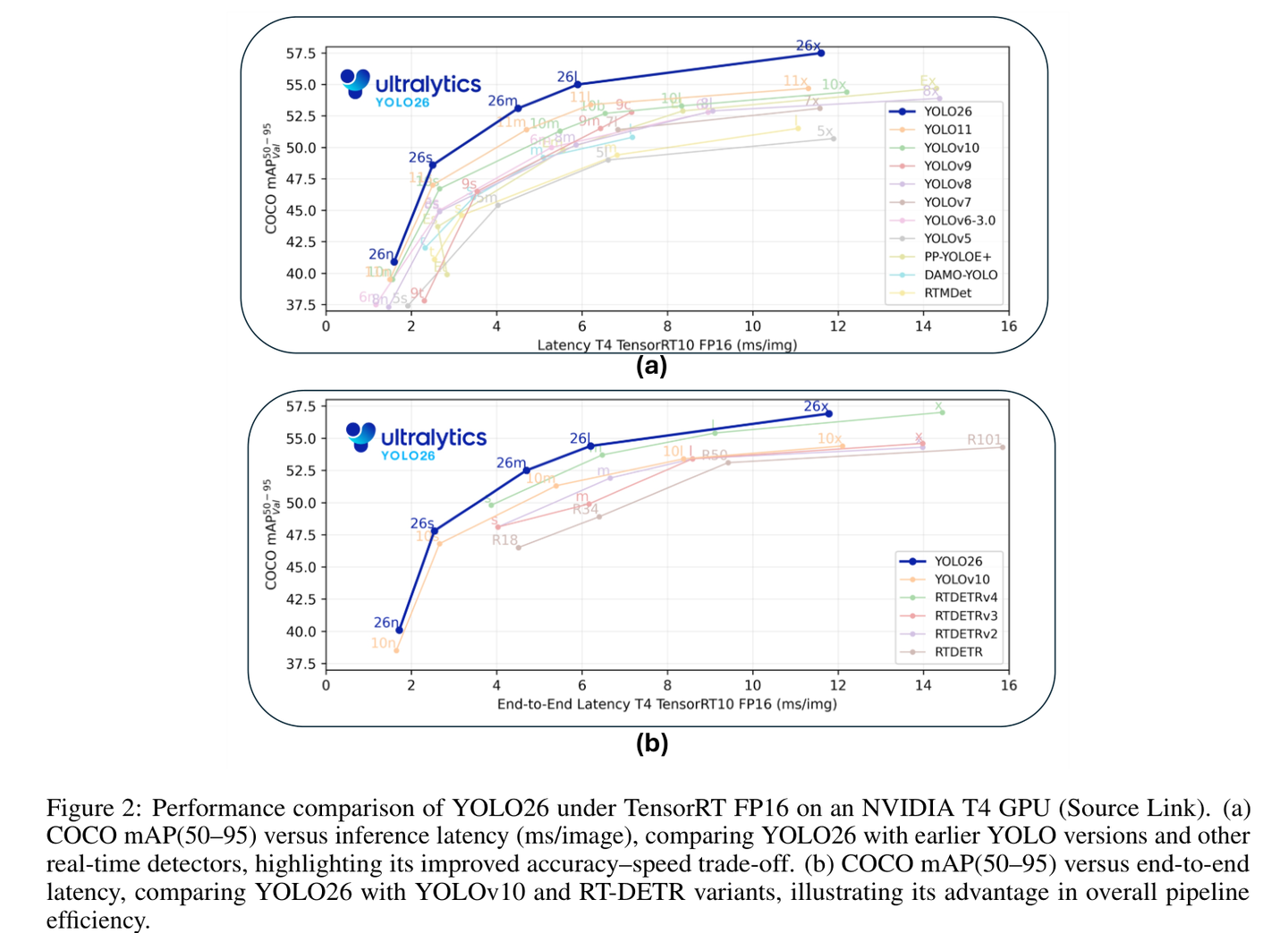
图 2:YOLO26 在精度与速度的平衡上已经达到了极高的水准,为 YOLOE-26 奠定了坚实的底座。
核心技术:如何实现“零开销”的语义对齐?
YOLOE-26 的架构设计在保持卷积神经网络(CNN)高效性的同时,引入了多模态交互机制。
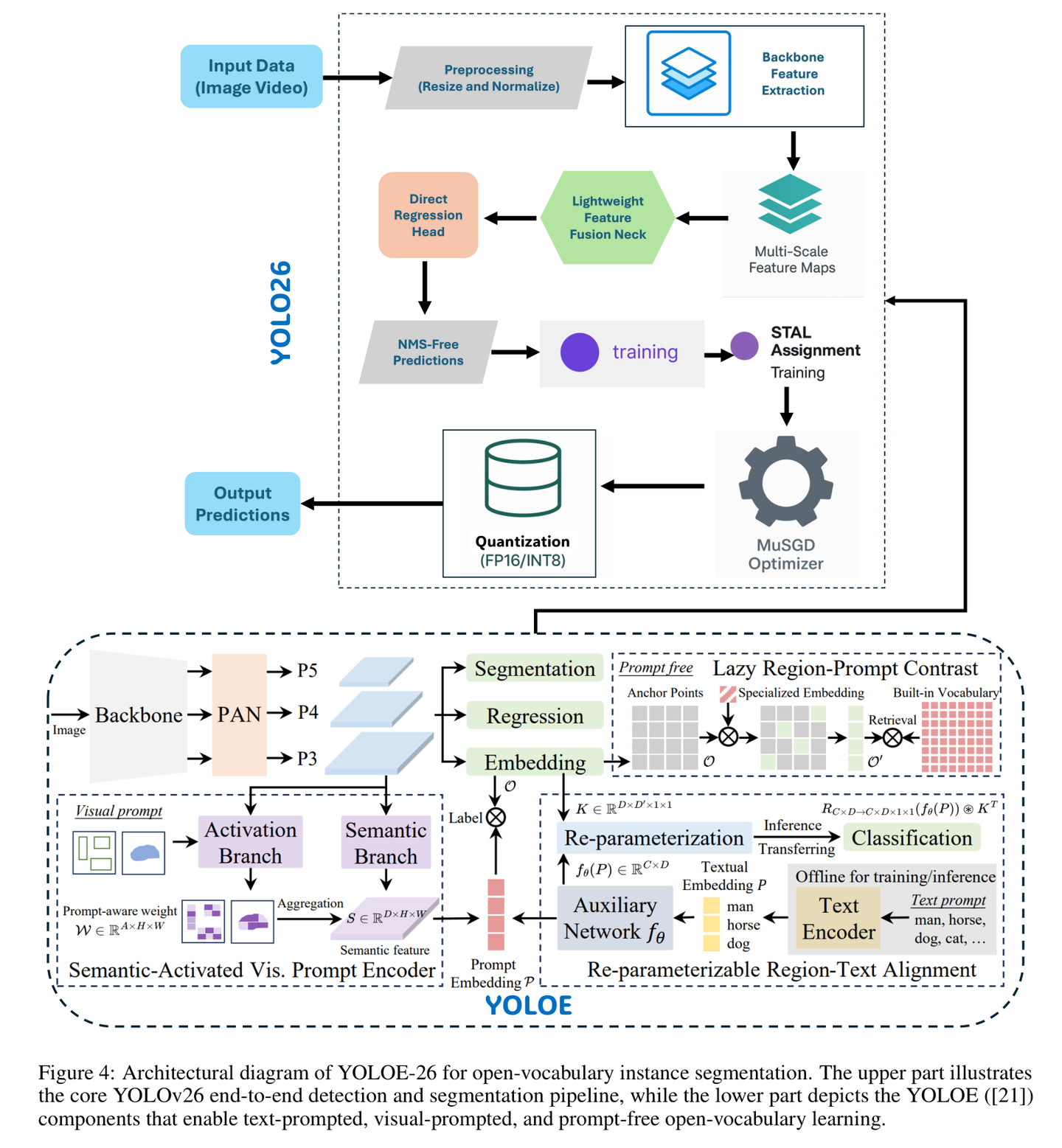
图 4:YOLOE-26 架构图。上半部分是核心的 YOLO26 端到端流水线,下半部分是实现开放词汇能力的关键组件。
其核心改进主要体现在以下三个方面:
1. 统一对象嵌入空间(Unified Object Embedding Space)

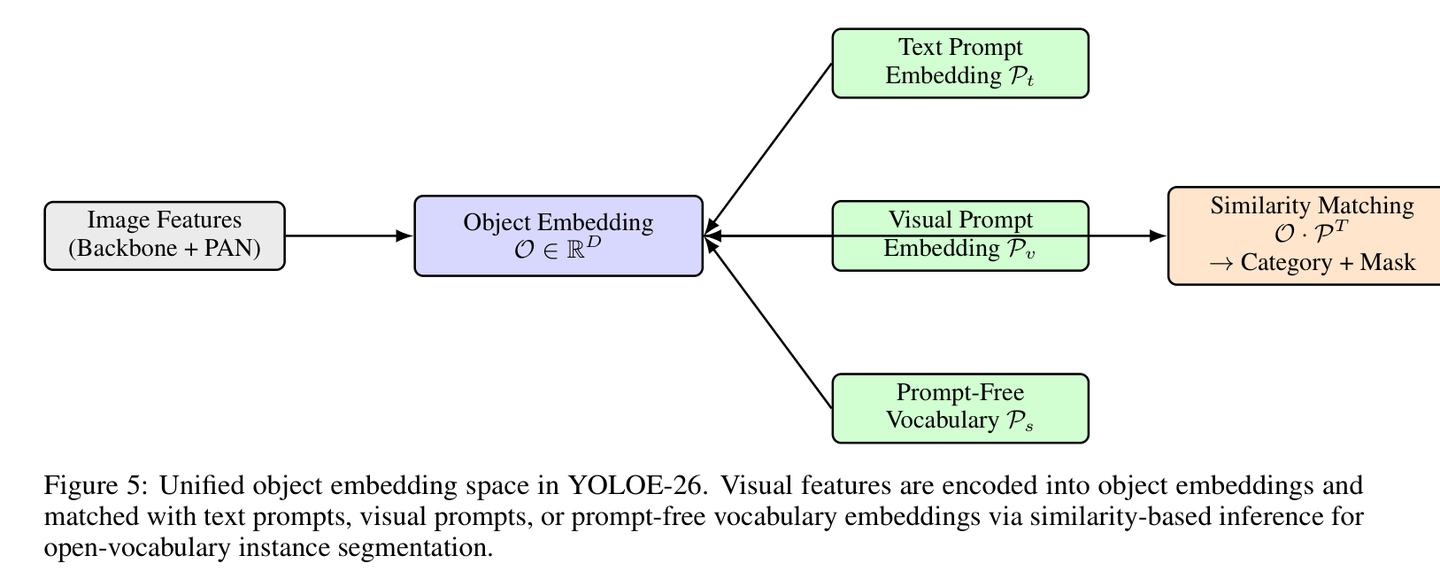
图 5:统一对象嵌入空间示意图。视觉特征与多种提示模式在同一空间内进行匹配。
2. 重参数化区域-文本对齐(Re-Parameterizable Region-Text Alignment, RepRTA)
为了让模型能听懂文字,通常需要复杂的交叉注意力机制,但这会拖慢速度。YOLOE-26 采用了 RepRTA 技术。在训练阶段,它使用一个轻量级辅助网络来对齐文本和图像;但在推理阶段,这个辅助网络会被“折叠”进卷积核中。 这意味着,当你给模型下达文字指令时,推理开销几乎为零。它依然运行着纯粹的卷积指令,却实现了跨模态的理解。
3. 语义激活视觉提示编码器(Semantic-Activated Visual Prompt Encoder, SAVPE)
如果你不想打字,只是想让模型找“长得像这个”的东西,SAVPE 就派上用场了。它是一个轻量级的编码器,能迅速将你点击或框选的示例转化为视觉提示嵌入。相比于动辄数亿参数的视觉 Transformer,SAVPE 极大地节省了显存和计算资源,实现了高效的示例引导分割。
训练策略:大规模数据与伪掩码的艺术
要让模型具备“万物识别”的能力,海量的数据必不可少。YOLOE-26 的训练过程充分利用了多源异构数据:
- 多源监督:模型在 Objects365(大规模检测)、GQA(视觉问答/定位)和 Flickr30k(短语定位)等数据集上进行联合训练。这保证了模型既有扎实的定位能力,又有丰富的语义常识。
- 伪掩码生成(Pseudo-mask Generation):由于并非所有大型数据集都自带高质量的分割掩码,研究团队利用 SAM 等强力模型为检测框生成伪掩码,并经过精细过滤和平滑处理,从而在没有人工标注的情况下训练出了强大的分割头。
- 多任务损失优化:系统同时优化分类损失(基于嵌入的 BCE)、边界框回归损失(IoU 家族)以及掩码分割损失。这种平衡确保了模型在识别“是什么”的同时,能精准地画出“在哪里”。
性能表现:不仅快,而且全
在实验中,YOLOE-26 展示了极强的扩展性。研究团队提供了从 Nano 到 Extra Large 五种尺寸的模型,以适应从手机到服务器的不同算力需求。
- 文本提示性能:最强的 YOLOE-26x-seg 在 640 像素分辨率下,文本提示的 mAP 达到了 39.5。
- 视觉提示性能:在给定参考图的情况下,其 mAP 也能达到 36.2,展现了极佳的一致性。
- 无提示自主发现:在没有任何输入的情况下,依靠内置的 4585 个类别词汇表(采用延迟区域-提示对比(Lazy Region Prompt Contrast, LRPC)策略),模型依然能实现 29.9 的 mAP。这对于自动化场景(如无人机巡检)极具价值。
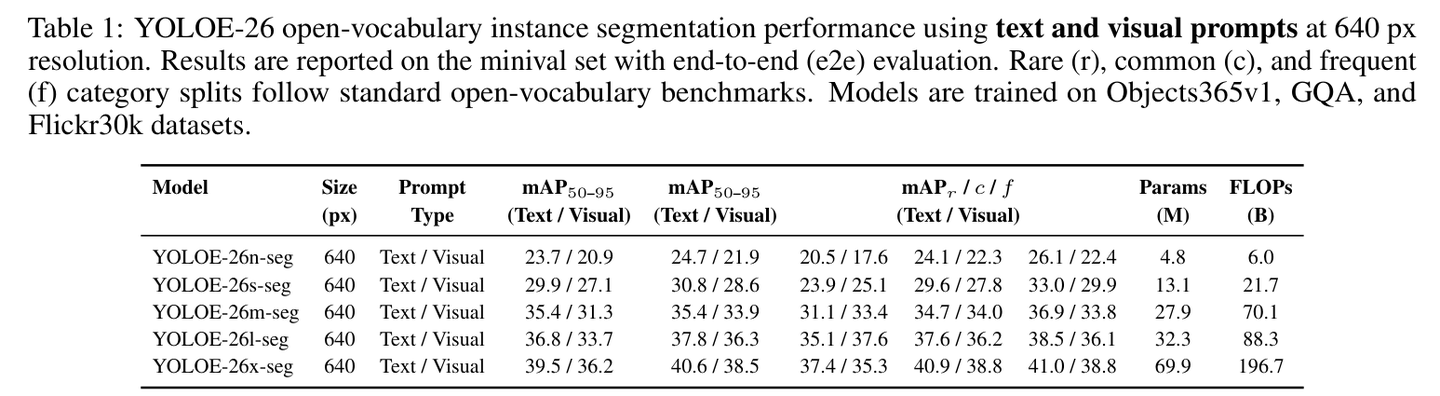
表 1:YOLOE-26 在文本和视觉提示下的性能表现。
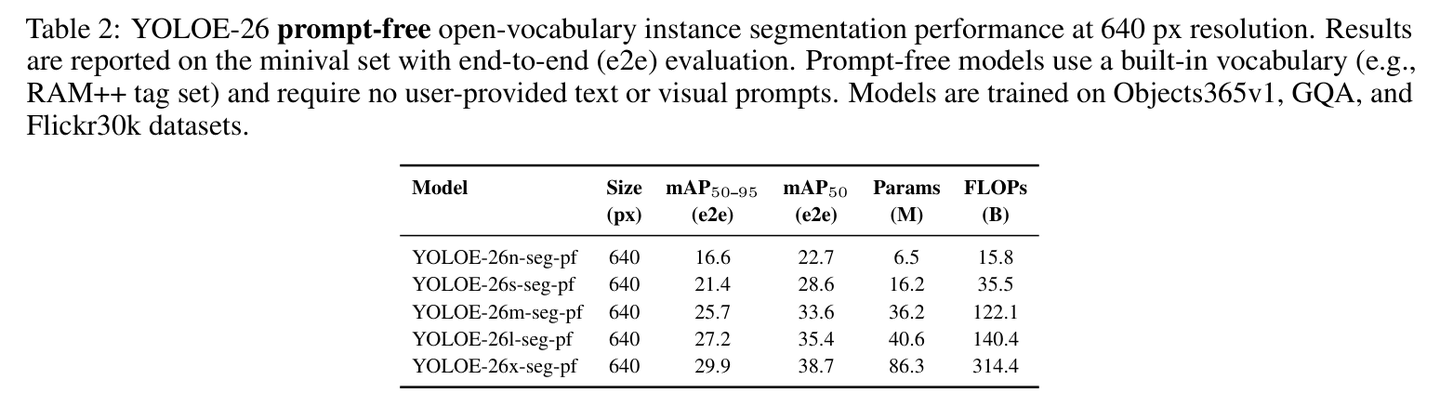
表 2:YOLOE-26 在无提示(Prompt-free)模式下的性能,展示了强大的自主发现能力。
开源实践:几行代码即可上手
YOLOE-26 深度集成了 Ultralytics 生态,这意味着它的易用性极高。如果你熟悉 YOLOv8 或 YOLO11,那么上手 YOLOE-26 几乎没有门槛。
以下是一个简单的视觉提示推理示例:
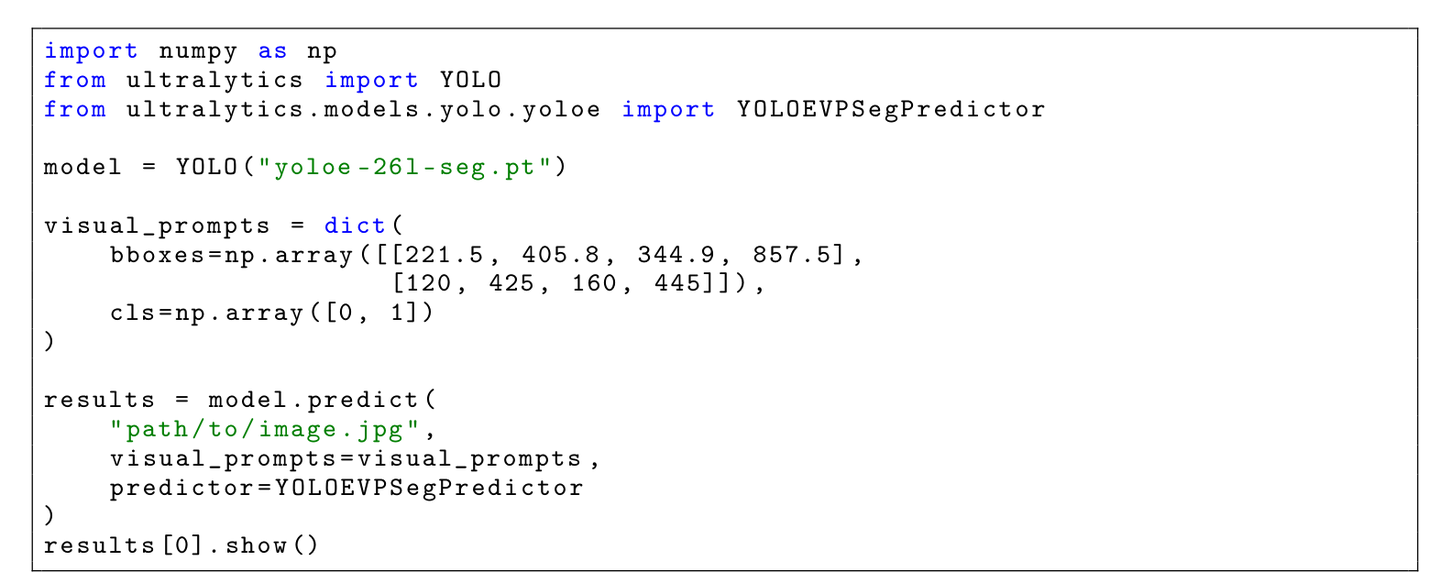
通过这种方式,你可以轻松地在自己的应用中集成。
写在最后
如果你正在寻找一个既能部署在边缘设备上,又能灵活应对未知物体的分割方案,YOLOE-26 绝对是值得关注的候选之一。
发表回复