
原文链接:https://zhuanlan.zhihu.com/p/1996906884289032497
在自动驾驶领域,视觉-语言模型(Vision Language Models, VLMs) 擅长高层语义理解与推理,而语义占据(Semantic Occupancy) 则能够提供精细、结构化的空间细节。尽管这两个方向各自取得了显著进展,但目前仍缺乏一种能够有效融合二者的统一方法。
一方面,传统 VLM 在自动驾驶场景中面临 token 数量爆炸 以及 时空推理能力受限 等问题;另一方面,语义占据通过统一且显式的空间表示建模环境,但其表示过于稠密,难以高效地与 VLM 进行集成。
为了解决上述挑战并弥合 VLM 与占据表示之间的鸿沟,华科、小米和清华AIR的团队提出了 SparseOccVLA,一种新的 视觉-语言-动作(Vision-Language-Action, VLA)模型,通过 稀疏占据查询(Sparse Occupancy Queries) 实现了场景理解、占据预测与轨迹规划的统一建模。
具体而言,SparseOccVLA 首先采用一个轻量级的 稀疏占据编码器(Sparse Occupancy Encoder),生成 紧凑但信息量极高的稀疏占据查询,并将其作为连接视觉与语言的唯一桥梁。这些查询被对齐至语言空间,并由大语言模型(LLM)进行推理,从而实现统一的场景理解与未来占据预测。
此外,本文提出了一种 LLM 引导的 Anchor-Diffusion 规划器,其特点包括 解耦的锚点打分与去噪过程,以及 跨模型的轨迹条件融合机制,从而显著提升规划性能与稳定性。
在多个基准测试中,SparseOccVLA 展现出强大的综合能力: 在 OmniDrive-nuScenes 上,相较于当前最优方法,其 CIDEr 指标提升 7%(相对提升);在 Occ3D-nuScenes 上,mIoU 提升 0.5;并且在nuScenes基准上取得了当前最优的开环规划性能。
- 论文链接:https://arxiv.org/abs/2601.06474
- 代码仓库:https://github.com/MSunDYY/SparseOccVLA
- 项目主页:https://msundyy.github.io/SparseOccVLA/
🔥 背景回顾
在过去的几年,视觉语言模型(VLM)和语义占用网络(Occupancy)作为自动驾驶领域的两大分支,各自蓬勃发展,均取得了极大的成功。其中视觉语言模型擅长宏观层面的理解和推理,但是常规的视觉-语言对齐策略(如MLP,Q-Former)天然难以处理自动驾驶系统的多视角视频流,其存在显著的跨视角偏差。一些方法尝试将多视角图片投影到鸟瞰图(BEV)空间,但是稠密的表征依然存在token数量爆炸,且token有效利用率较低,细粒度感知能力较弱。相较于BEV,语义占用(Occupancy)提供更全面和精细的空间表征,近年来已经发展较为成熟。然而,VLMs和Occupancy在自动驾驶中长期独立发展,还没有方法能有效结合和利用两者的优势。
尽管早期的一些工作尝试将Occ真值重编码后被LLM理解,但因存在非几何视觉信号丢失的天然缺陷,并未被广泛采用。
归根结底,限制VLM和Occupancy结合的瓶颈在于以下几个方面。
- ❌ 模态差异:Occupancy天然低水平的表征难以对齐到高水平的语言空间。
- ❌ 计算负担:Occupancy天然密集的性质会产生海量的token,远超过LLM的处理能力。
为了解决上述问题,本文提出的SparseOccVLA,其核心思想在于:
- ✅ 利用稀疏的占用查询量(sparse occupancy query)表征时空场景,在不丢失视觉元素的前提下实现高效的token压缩。
- ✅ 将occupancy query作为连接视觉输入和语言唯一的桥梁送入LLM中,实现统一的理解和预测。
📚 相关工作回顾
自动驾驶的视觉语言模型
早期的端到端方法如UniAD,VAD等通常被认为是黑盒,近年来,视觉语言大模型被广泛应用于自动驾驶中做理解,COT推理和规划。在视觉输入和语言空间的对齐策略上,主流方法采用直接MLP投影,但这会产生爆炸数量的token,天然不适合于需要处理多视角视频流的自动驾驶系统。
一些方法采用Q-Former来压缩token,但其无差别的全局交叉注意力会丢失大量局部细节,导致其普遍性能不佳。最近的工作首先将多视角图片投影到统一BEV空间,然后送入LLM中理解。但BEV密集的性质使其token利用率极低,且难以处理不均匀空间。
自动驾驶的语义模型
语义占用模型能提供更详细和细粒度的空间表征,特别擅长建模不规则元素。依据建模思想,当前主流的占用模型可分为:
- 密集建模:输出每一个体素标签。代表工作:FlashOcc,COTR
- 稀疏建模:仅关注占用体素。代表工作:SparseOcc,OPUS
近年来,研究者们探索了基于Occupancy的世界模型,以OccWorld为代表的大量优秀工作被提出。
语义占用与视觉语言模型的结合
早期的工作将occupancy真值离散化,通过VAE编码,让语言模型理解。但这将LLM和感知模型隔离,完全丢失了非几何的视觉信号(如红绿灯,车道线和指示牌等)。最近的OccVLA引入occupancy监督来提升VLM的性能,但它依然依赖视觉token的输入,继承了传统VLM所有的缺陷。
🧩 方法概览(Overview)
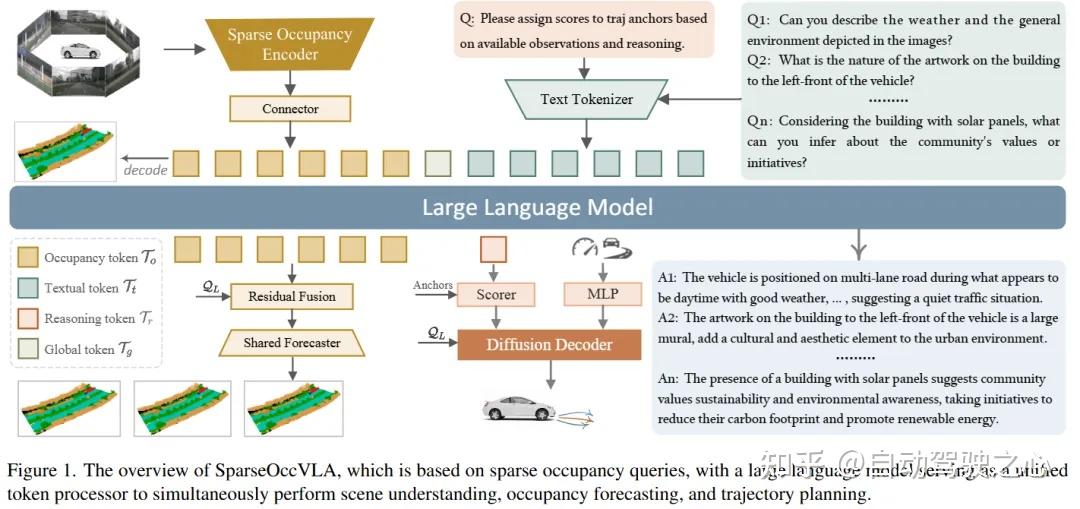
本文提出了SparseOccVLA,首先通过稀疏占用编码器将多帧多视角视觉输入编码进高度轻量化的occupancy query,通过连接器将其对齐到语言空间,经过统一的大语言模型推理后执行理解、预测和规划等下游任务。
稀疏占用编码器
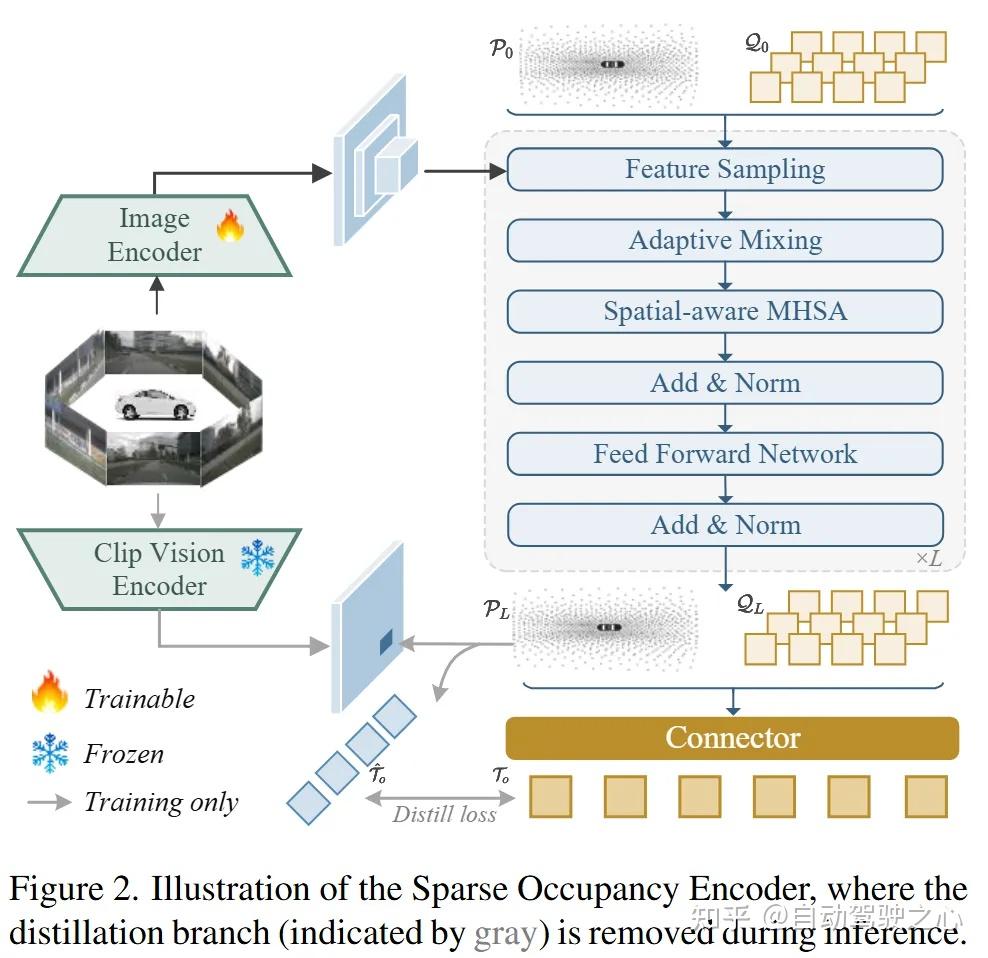
此模块以多视角视频流为输入,用轻量的图片编码器提取多尺度特征。随机初始化一组带有显式3D坐标的稀疏占用查询嵌入(query embedding),通过多层叠加的编码层与图片特征作交互,并在每一层之后接一个语义占用头,对每个query预测其周围的语义占用点,相应地调整query坐标。通过逐层增加输出占用点数,此模块实现由粗到细的占用预测和编码,同时保持信息流的高效性。每一层的输出用Chamfer Distance(CD)来监督:
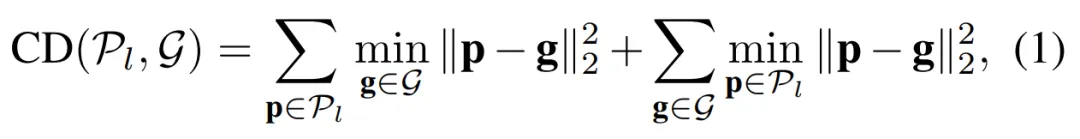
最后一层编码器得到的query embedding被用一个连接器(MLP)对齐到语言空间,充当视觉输入和LLM的唯一桥梁,用于下游任务,因此摆脱了对视觉token的依赖。基于稀疏占用查询量的建模策略相比较常规的视觉-语言对齐策略具有如下核心优势:
- 轻量高效:仅关注真实空间中的实体,信息密度和token利用率极高,仅需要数百token即可有效地表征完整场景,这在训练和推理是非常高效。
- 时空建模友好:通过显式的3D位置编码建模空间信息,通过适应性采样及融合机制捕捉时序信息,occupancy query天然具备强大的时空表达能力。
此模块同时引入了可选的基于Clip的特征级蒸馏损失来辅助对齐,加速模型收敛。
统一的大语言模型
大语言模型(LLM)是SparseOccVLA的支柱,统一执行场景理解、未来帧占用预测和规划等任务。考虑到occupancy query用局部loss来监督,缺乏全局信息,为了加强LLM对场景的整体理解,本文用少量全局查询量与occupancy query交互,然后和occupancy query合并为感知token。来自用户的问题提示被文本分词器编码成文本token,与感知级token一起送入大语言模型执行自回归地文本推理,没有其他操作。
为了充分利用occupancy token的语义信息和occupancy query的局部细节,本文在LLM推理之后设计了一个残差融合层,后接共享的占用预测器逐帧预测未来帧的占用状态。
语言模型引导的锚点-扩散规划器
为了进一步验证稀疏占用查询对模型规划能力的影响,挖掘其泛化潜力,本文提出用语言模型来引导锚点选择,用sparse occupancy query代替常见的BEV、object、map等,作为唯一的感知表征,用基于多模态条件输入的扩散解码器输出预测轨迹。
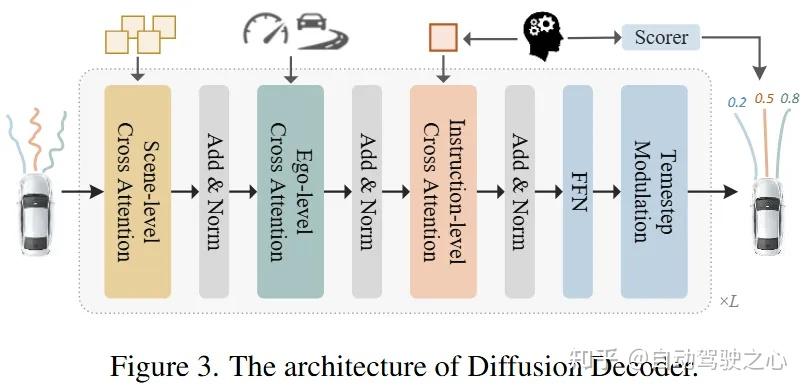
此模块将加噪的锚点轨迹分别与occupancy query,自车状态以及LLM输出的文本token交互,实现了有效的跨模态融合。
📦 实验结果分析
理解与预测结果
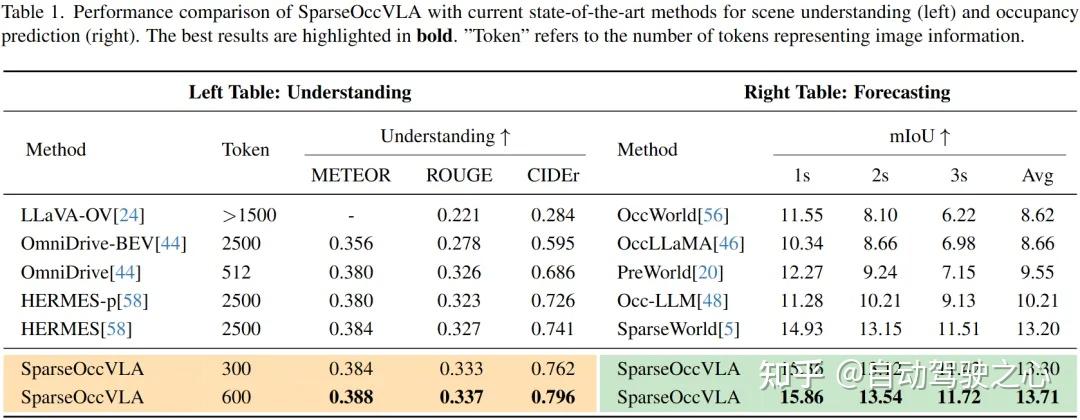
表1左给出了在OmniDrive-nuScenes上场景理解任务的语言指标评测结果,可以看到,SparseOccVLA的CIDEr指标相比较sota的HERMES实现了7%的相对提升。且相较于基于BEV的HERMES需要2500个token,SparseOccVLA最低仅需要300个token,即可实现相当有竞争力的性能,保证了推理效率。
表1右给出了在Occ3d-nuScenes上的未来3s内语义占用预测结果。SparseOccVLA也实现了超越sota的性能。
开环规划结果
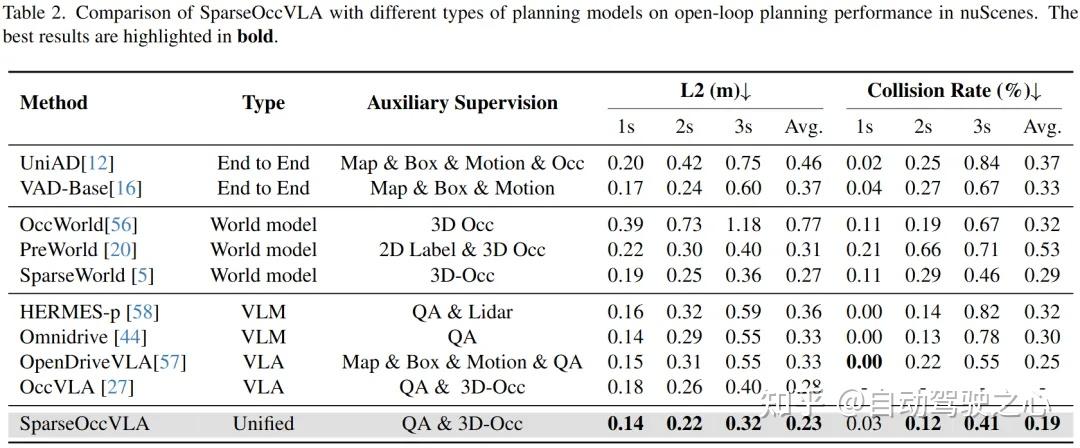
表2给出了SparseOccVLA在nuScenes数据集上的开环规划指标,并与不同类型的规划器做了比较。显然,仅将sparse occupancy query作为感知输入,规划器已经能有效地感知周围环境,并做出合理的驾驶决策,证明了occupancy query具备充足的应用和泛化潜力,有被进一步研究的价值。
🏗️ 消融实验与可视化
关键消融模块研究
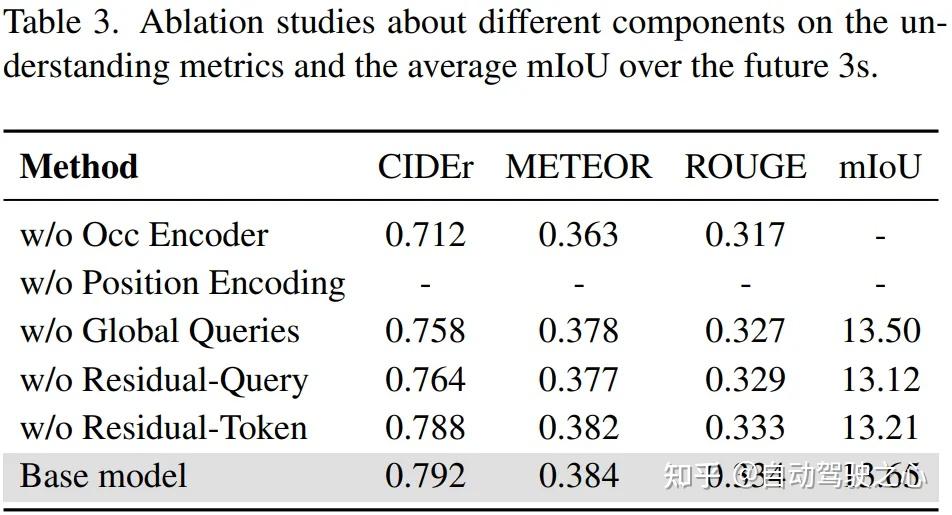
表3依次给出了Occupancy编码器,显式3D位置编码,全局查询量,以及残差融合对SparseOccVLA性能的影响分析,得出如下结论:
- 当移除occupancy监督时,occupancy encoder将退化成一个局部采样的Q-Former模块,此时缺少有效信息正则化,语言指标出现显著的下降,证明了显式的几何和语义引导对了LLM理解场景非常重要
- 当移除3D编码,此时occupancy query将完全无序,LLM难以从中学到空间拓扑结构,此时模型无法收敛
- 全局查询和残差融合分别对场景理解和occupancy预测起到显著作用,同时观察到了两者相互促进的特点。

从可视化结果可以看出,SparseOccVLA不仅能识别远处的行人、车辆等有形状的物体,还能准确地识别出红灯状态,地面上的车道线等非几何元素,这得益于其完全端到端的设计,保留了来自原始图像中的视觉信号。
🧠 结论
本文提出的SparseOccVLA利用sparse occupancy query作为桥梁,将occupancy与VLM做了有效结合,在场景理解、未来预测、路径规划等自动驾驶核心任务中都实现了强大的性能。本文本质上提供了一个超越传统基于MLP,Q-Former和BEV的连接视觉和语言的新范式,这将促进跨领域研究,同时推动自动驾驶社区的发展。
参考
[1]Dang C, Wang J, Li G, et al. SparseOccVLA: Bridging Occupancy and Vision-Language Models via Sparse Queries for Unified 4D Scene Understanding and Planning[J]. arXiv preprint arXiv:2601.06474, 2026.
[2]Wang J, Liu Z, Meng Q, et al. Opus: occupancy prediction using a sparse set[J]. Advances in Neural Information Processing Systems, 2024, 37: 119861-119885.
[3]Dang C, Liu H, Bao J, et al. Sparseworld: A flexible, adaptive, and efficient 4d occupancy world model powered by sparse and dynamic queries[J]. arXiv preprint arXiv:2510.17482, 2025.
发表回复