
原文连接:https://zhuanlan.zhihu.com/p/1996517812504650805
如果你和我一样,一直在关注视频对象分割(VOS)领域,那你一定对 SAM(Segment Anything Model)家族的威力不陌生,尤其是它的视频版本SAM2。这类模型在连续帧中追踪物体的能力很强,但它们有一个共同的“软肋”:一旦摄像机视角变化太大,或者物体消失后再次出现,它们就很容易“脸盲”,跟丢目标。
这背后的原因是,它们主要依赖2D的外观特征来识别物体。想象一下,你从正面看一个杯子和从顶上看一个杯子,它的样子完全不同,单纯靠“长相”来认,确实难免会出错。
而3AM这篇工作,正是为了解决这个痛点而来。它巧妙地为以SAM2为代表的2D分割模型注入了“3D几何感知”的能力,让模型不仅认识“皮相”,更能理解“骨相”。最关键的是,它在实现这种强大能力的同时,推理时依然只需要普通的RGB视频,无需相机位姿、深度图等额外信息,真正做到了既强大又实用。

- 论文标题: 3AM: Segment Anything with Geometric Consistency in Videos
- 论文地址: https://arxiv.org/abs/2601.08831
- 项目主页: https://jayisaking.github.io/3AM-Page/
- 代码仓库:Code Coming Soon
- 机构: 台湾阳明交通大学,英伟达研究院
3AM可理解为“具备3D感知能力的 SAM 模型”(3D-aware SAM)。
背景与动机:2D与3D的“两难困境”
在VOS领域,一直存在着两条平行的技术路线,但都未能完美解决大视角下的目标跟踪问题。
- 2D VOS方法 (如SAM2) :这类方法基于记忆网络架构,通过时空注意力机制来关联不同帧中的物体。它们速度快、效率高,但在处理外观变化剧烈的场景时,由于缺乏几何层面的理解,常常会发生错误。如下图(a)所示,当视角从沙发正面切换到侧面时,SAM2的分割结果就出现了明显的漂移和丢失。
- 3D实例分割方法:这类方法直接在3D空间(如点云)中进行操作,天然具有几何一致性。但它们的代价是需要精确的相机位姿、深度图,并且需要进行昂贵的预处理(如三维重建),计算成本高昂,且难以应用于在线或流式场景。如下图(b)所示,如果3D重建本身不完整或有噪声,分割错误反而会被放大。

正是看到了这种“两难困境”,研究者们提出了3AM,旨在融合两者的优点:既要SAM2的效率和灵活性,也要3D方法的几何鲁棒性,但又不要它对额外输入的依赖。 如上图(c)所示,3AM在同样的大视角变化下,能够持续稳定地跟踪目标,展现了强大的跨视角对应能力。
方法详解:3AM如何炼成?
3AM的核心思想是在训练阶段,将一个强大的3D重建模型(MUSt3R)所提取的几何感知特征,与SAM2的2D外观特征进行深度融合。下面我们来看看它的两大“法宝”:特征融合器 (Feature Merger) 和 视场感知采样 (Field-of-View Aware Sampling) 。
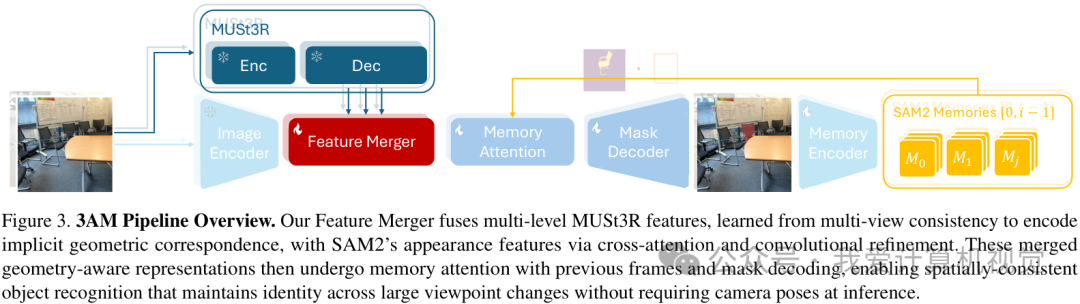
上图就是3AM的整体流程。可以看到,它的主体依然是SAM2的架构,但其关键的特征处理环节被一个新设计的“Feature Merger”模块所增强。
- Input: 一段RGB视频和一个初始提示(如第一帧的掩码、点或框)。
- Process:
- 视频的每一帧都会并行送入两个分支:SAM2的图像编码器提取2D外观特征,一个冻结的MUSt3R模型提取蕴含3D几何信息的特征。
- 这两个特征被送入Feature Merger模块,生成一个兼具2D纹理和3D结构的融合特征。
- 这个融合特征将替代SAM2原有的特征,参与后续的记忆读写和掩码解码过程。
- Output: 在整个视频中对目标物体的持续、一致的分割掩码。
法宝一:Feature Merger (特征融合器)
为什么需要融合?看下图就明白了。研究者做了一个实验,在一个点上查询它在另一视角下的对应位置。
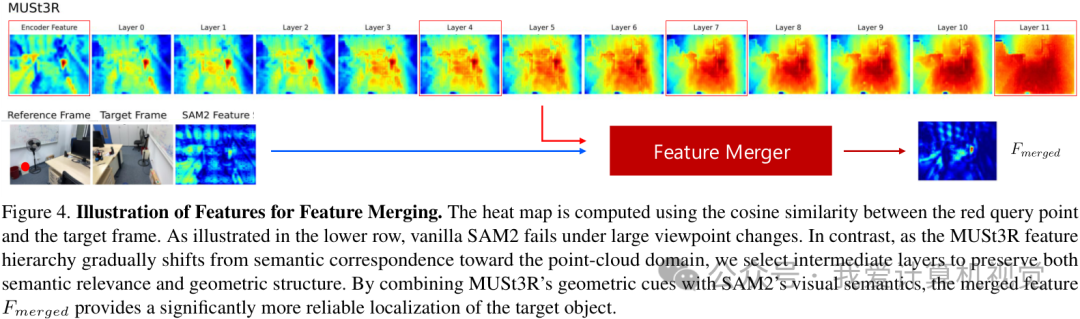
如图下半部分所示,SAM2的特征(基于外观)在视角变化后,完全找不到正确的对应区域,其相似度热图变得非常混乱。而MUSt3R的特征(基于几何)则不同,它的不同层级包含了从语义对应到点云空间的过渡信息。浅层特征语义信息更强,深层特征几何结构更明确。
3AM的Feature Merger正是要博采众长。它通过交叉注意力和卷积操作,将MUSt3R多个层级的特征与SAM2的特征进行有机结合,最终得到的融合特征F_merged,既保留了物体的视觉语义,又理解了它在3D空间中的位置,因此能够实现更可靠的定位。
法宝二:Field-of-View–Aware Sampling (视场感知采样)
这是3AM在训练阶段使用的一个“聪明”策略。为了让模型学会3D对应关系,我们需要给它看来自不同视角的同一物体。但怎么“看”是个学问。
- **连续采样 (a):**这种策略通过采集时间上连续的视频帧来提供密集的样本,但其致命缺点是视点多样性(Viewpoint Diversity)有限。模型在短时间内看到的图像高度雷同,难以学习到物体在不同视角下的泛化特征。
- 朴素随机采样 (b):为了增加视角变化,我们可能会在视频中随机抽帧,但这会导致模型观察到空间不相交(Spatially Disjoint) 的区域。例如:第 0 帧拍的是沙发的左侧,第 1 帧拍的是沙发的右侧。由于这两个区域在 3D 空间中相距甚远,强行让模型将它们视为同一组监督信号进行对齐,会迫使模型去匹配不一致的几何结构,从而导致学习信号的混乱(Ambiguous Learning)。
- 视场感知采样 (c):这是本文提出的优化策略。它在选择训练帧时,会利用位姿信息进行过滤,仅保留那些其 3D 点落在参考帧相机平截头体(Frustum) 内且重叠度超过阈值的帧。这种方法在确保几何一致性(即模型确实在观察同一个局部区域)的同时,保留了自然的姿态变化和遮挡变化,大幅提升了 3D 学习的质量。

通过这种方式,3AM确保了模型在学习跨视角一致性时,接触到的都是几何上一致、可靠的训练样本,从而大大提升了学习效率和效果。
实验与结果:性能大幅超越SOTA
理论说得好,不如数据来得实在。3AM在多个极具挑战性的数据集上都取得了惊人的效果,这些数据集都以包含剧烈的相机运动和物体“消失-重现”为特点。
ScanNet++ 数据集
研究者们在ScanNet++数据集上构建了一个专门用于评估物体再出现(reappearance)场景的子集(Selected Subset)。在这个子集上,3AM的性能可谓一骑绝尘。
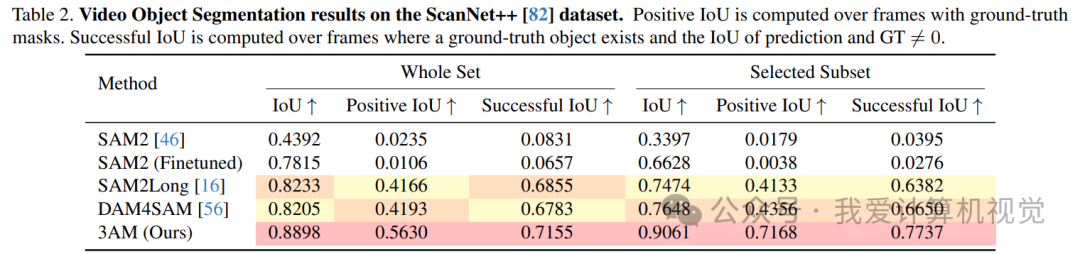
从上表可以看到,在最具挑战性的 Selected Subset 上:
- 3AM的 IoU 达到了 90.6%,而之前的SOTA方法DAM4SAM只有76.5%。
- 更关键的 Positive IoU (只在物体可见的帧上计算IoU,更能反映跟踪质量),3AM达到了 71.7%,相比DAM4SAM的43.6%和SAM2Long的41.3%,分别实现了 +28.1 和 +30.4 个点的巨大性能飞跃!
下面的可视化结果更直观地展示了3AM的强大。无论是椅子、屏幕还是桌子,在经历大幅度的视角偏转甚至完全移出画面再移回后,3AM都能精准地再次识别并分割出来,而其他方法则早已“跟丢”了。

Replica 数据集
在同样以3D场景和自由视角为特点的Replica数据集上,3AM同样表现出色。
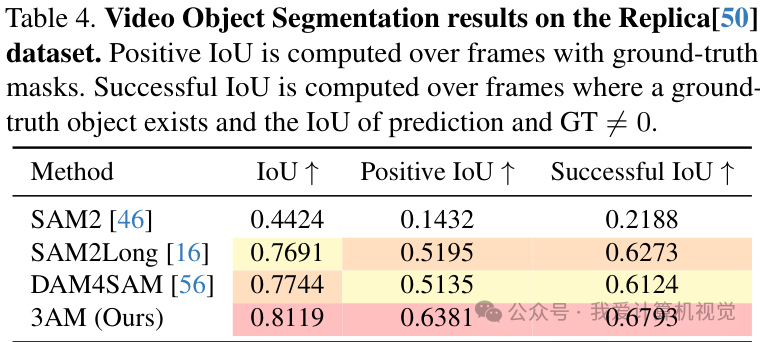
它的IoU达到了 81.19% ,Positive IoU达到了 63.81% ,全面超越了包括SAM2Long和DAM4SAM在内的所有对比方法。
一点思考
3AM的成功,为我们揭示了一个非常重要的方向:将隐式的3D几何先验知识“蒸馏”到高效的2D模型中,是提升模型在复杂三维世界中感知鲁棒性的关键钥匙。
它没有粗暴地将3D重建作为后处理,也没有强行改变成熟的2D模型架构,而是通过一个即插即用的特征融合模块,在训练阶段让模型“学会”理解3D空间,在推理阶段则“忘记”对3D输入的依赖。这种“训练时复杂,推理时简单”的哲学,对于推动前沿算法的实际落地,具有非常重要的借鉴意义。
未来,我们或许可以看到更多类似的工作,将不同模态的知识(如物理、因果、几何等)以更优雅、更高效的方式融入到基础模型中,让AI真正地“理解”我们所处的三维世界。
发表回复