
原文链接:https://zhuanlan.zhihu.com/p/1992036976216524281
导读
现在越来越多“能动”的 AI 开始想做一件更难的事:把真实世界变成可复用的数字世界。不管是内容创作、自动驾驶,还是具身智能,大家都希望模型不仅能看懂一段视频,还能“在脑子里搭出一个会动的 3D 世界”,并且从没拍过的视角、没走过的轨迹里继续生成一致的画面。问题是,很多 4D 世界模型
要么依赖昂贵的多视角动态采集,要么训练前得做一堆离线重建与预处理,规模一大就很难推。NeoVerse 盯住的就是这个瓶颈:能不能用最便宜、最常见的野外单目视频,把 4D 重建和新轨迹视频生成都做成“可扩展、能泛化”的一套框架?
先“快建世界”,再“补出高质量”,把单目视频也变成 4D 训练燃料
作者的关键创新在于:如果想吃下海量单目视频,第一步必须把“建世界”这件事变轻。NeoVerse 先用一个前馈式的重建模型,从单目视频里直接预测出动态的 4D 高斯表示(4DGS),你可以把它理解成一团会随时间移动的“高斯点云”,既能渲染新视角,也能带时间变化。为了让动态更可信,他们还加入了双向运动建模:同一个点既学“往前一帧怎么动”,也学“往后一帧怎么动”,方便在不同时间点之间插值补齐。
第二步更巧:他们把重建出的 4DGS 渲染成新视角的低质量条件输入(包括渲染 RGB、深度、遮罩、以及表示相机运动的 Plücker 表达等),再交给生成模型去“补成高质量视频”,同时要求时空一致、相机轨迹可控。为了让训练能规模化,NeoVerse 还专门设计了“在线退化模拟
”:在训练时人为制造遮挡、飞边深度像素、畸变等问题,让生成模型学会在这些糟糕条件下仍能补出稳定画面。这样一来,单目野外视频就能不断变成可用的训练对。
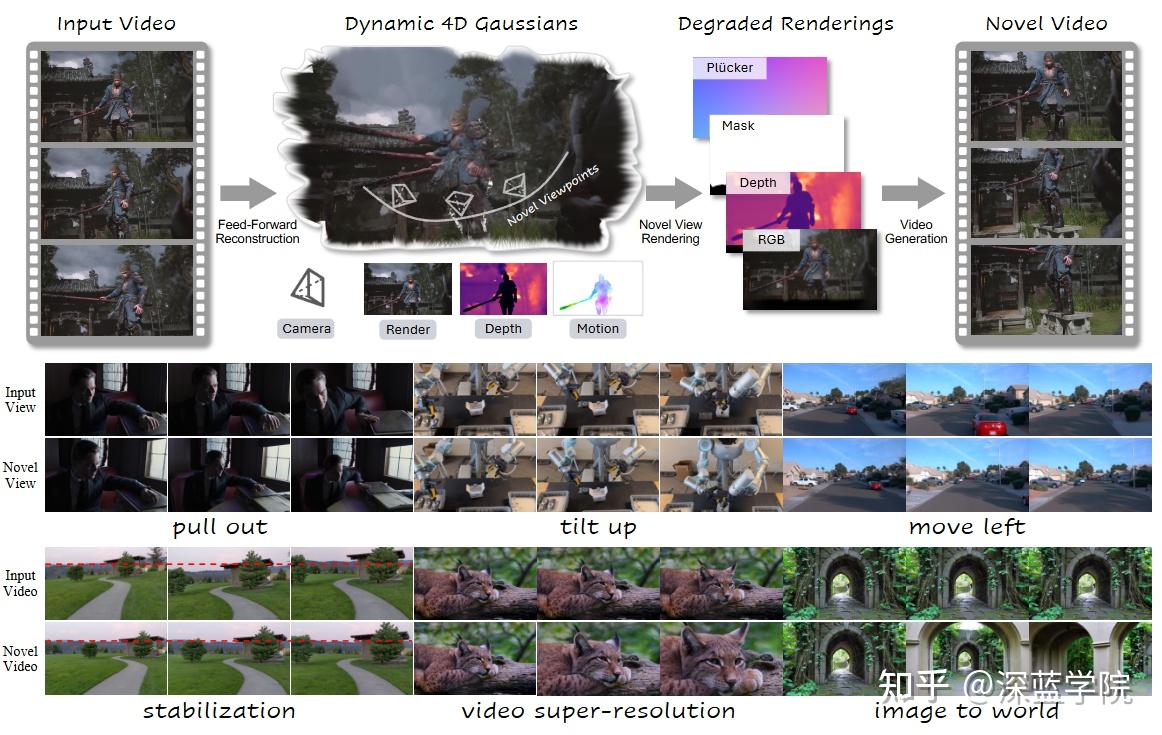
技术亮点
无需外参 + 4DGS一遍过,把“重建”从重工程变成轻入口
NeoVerse 的重建部分强调“pose-free”,也就是不强依赖外部提供的相机位姿输入,直接从单目视频估出可用于渲染的动态表示与相机参数。更关键的是“前馈式”:不走那种一段视频反复优化的慢流程,而是更像“一遍过”把动态 4DGS吐出来。这个过程大大降低了世界场景重建的工程量,轻量化的设计让重建出来的环境可以更好的服务于训练智能体。
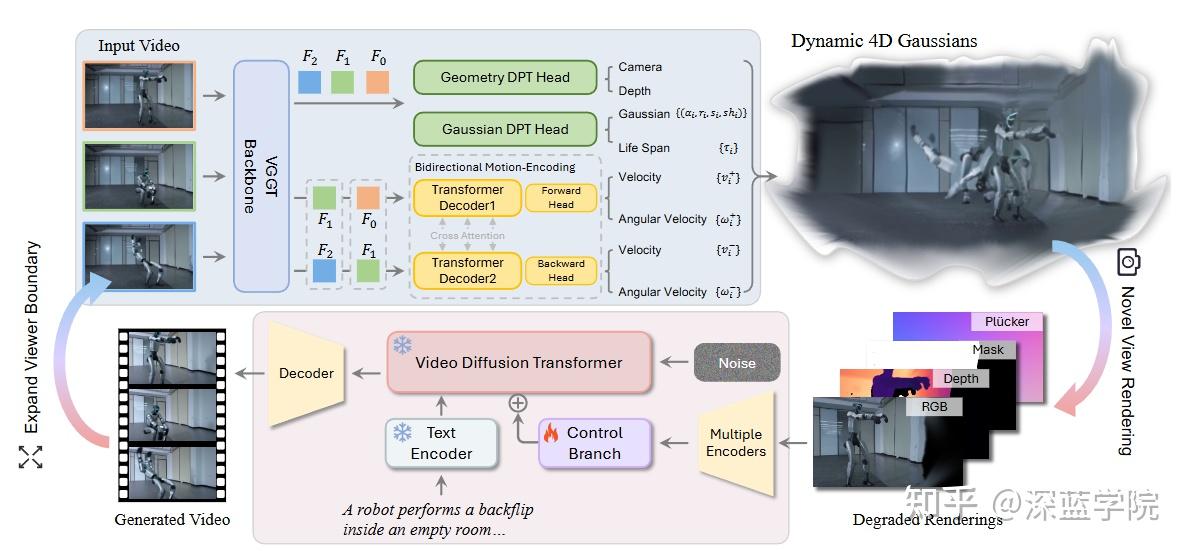
图2|NeoVerse 框架:先重建,再生成,两阶段把单目视频变成可控的 4D 世界模型。
第一阶段是无位姿依赖的 4DGS 重建,并引入双向运动建模来描述动态变化;第二阶段将 4DGS 在新视角下的退化渲染结果作为条件输入,训练生成模型输出更清晰、更一致的新视角视频。训练时,退化条件由单目视频在线模拟,而原始视频作为监督目标
双向运动建模,让动态插值和稀疏关键帧训练都能站得住
单目视频里动态物体的运动很容易“糊”,尤其当你只选稀疏关键帧做重建时,中间帧怎么补是个大坑。NeoVerse 用双向速度与角速度去描述点的运动,把“向前”和“向后”区分开,能更自然地在相邻时间点之间做插值。这样他们就能用稀疏关键帧重建来提升训练效率,同时不至于让动态一致性掉太多。

在线退化模拟,把“单目野外视频难训练”变成“可控的训练信号”
论文里把单目新视角渲染的常见问题讲得很具体:遮挡带来的缺失、深度边缘的飞边像素、以及由深度误差引起的空间畸变。NeoVerse 不是回避这些问题,而是把它们做成训练时的“故意刁难”:用可见性高斯裁剪模拟遮挡,用平均几何滤波制造飞边与更大范围畸变,让生成模型在坏条件下学会补全并保持时空一致。对具身系统来说,这相当于提前在训练里“见过最差的现实”,部署时就更不容易被噪声一脚绊倒。

实验与验证
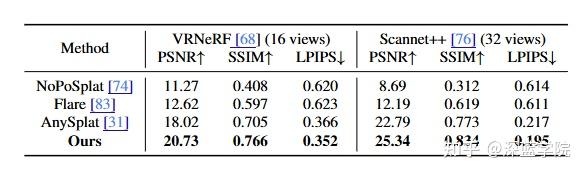
实验主要传达两个趋势:重建质量更好,以及生成在大幅相机运动下更稳、更快。在动态重建基准上,NeoVerse 的量化指标(PSNR/SSIM/LPIPS
)整体优于多种对比方法,并且论文也强调有的方法还需要相机位姿作为输入,而他们主打的是更易规模化的设定。
在新轨迹视频生成上,论文用 VBench 做了系统评估,同时给了非常直观的“工程信号”:对比 TrajectoryCrafter、ReCamMaster 等方法,NeoVerse 在保持相机轨迹可控的前提下,能用稀疏关键帧把重建阶段压到很短,并把总推理时间从“分钟级”拉到更接近“几十秒级”的量级(表中总时间对比非常醒目)。
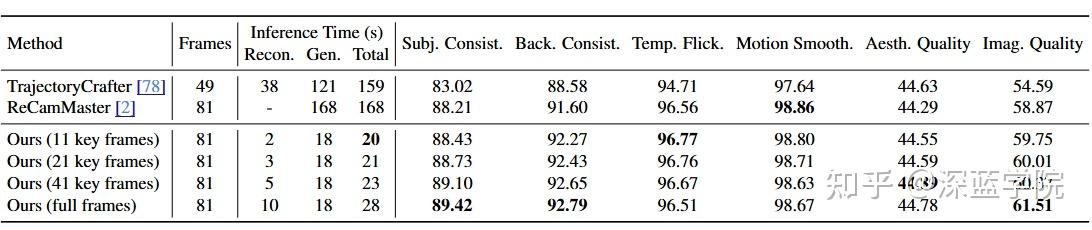
定性结果里,他们专门展示了大幅相机运动(例如左右平移、转向)时的画面稳定性,并指出某些对比方法会出现明显伪影,而 NeoVerse 视觉质量更干净。

总结
NeoVerse 的价值不只是在某个指标上更高,而在于它把“4D 世界模型如何吃下野外单目视频”这件事讲清楚并做成了:用更轻的前馈式 4DGS 把世界先搭起来,再用退化条件驱动的生成去补出高质量,同时用在线退化模拟把单目场景的坑变成训练信号。
对General的AI来说,这类方法更像在铺一条路:当世界模型能用便宜数据越练越广,AI智能体未来的“世界理解”就可能不再局限于少量精心采集的场景。
如果 4D 世界模型真的可以从互联网视频里持续生长,AI智能体会不会第一次拥有“见得越多,世界越完整”的长期学习体验?
论文出处:arXiv2026
论文标题:NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
论文作者:Yuxue Yang, Lue Fan, Ziqi Shi, Junran Peng, Feng Wang, Zhaoxiang Zhang
发表回复