
原文连接:https://zhuanlan.zhihu.com/p/1992526098139992212
这是YOLO系列的最新工作,来自腾讯优图实验室、新加坡管理大学的研究团队,他们提出了一个名为 YOLO-Master 的新框架。
这名字听起来就挺霸气的,而它的核心思想也确实够“Master(大师)”。简单来说,它不再像传统的YOLO那样,对所有图片都“一视同仁”地进行密集计算,而是引入了最近在AIGC领域大火的 混合专家(Mixture-of-Experts
, MOE) 思想,让模型学会了“看菜下碟”:遇到简单的场景就少用点力,遇到复杂的场景就派更多的“专家”上场,实现了计算资源的动态分配。这种实例级的自适应计算,不仅减少了冗余,还在关键时刻(比如复杂场景)提供了更强的表征能力。最终,YOLO-Master在精度和速度上都取得了非常亮眼的表现。

- 论文标题: YOLO-Master: MOE-Accelerated with Specialized Transformers for Enhanced Real-time Detection
- 机构: 腾讯优图实验室, 新加坡管理大学
- 论文地址: https://arxiv.org/abs/2512.23273
- 代码仓库: https://github.com/isLinXu/YOLO-Master
背景:静态计算的瓶颈
实时目标检测(Real-Time Object Detection, RTOD)领域,以YOLO为代表的架构一直是速度与精度权衡的典范。从YOLOv1到如今层出不穷的各种变体,它们大多遵循一个共同的范式:静态密集计算。
这意味着,无论输入是一张空无一物的白纸,还是一张布满行人和车辆的繁华街景,模型都会调用同样规模的计算资源来处理。这种“一刀切”的方式存在明显的弊端:
- 资源浪费:在处理简单、背景干净的图像时,大量计算单元被“空转”,造成了不必要的算力消耗和延迟。
- 性能瓶颈:在处理包含大量小目标、遮挡严重的复杂图像时,固定的计算容量又可能“力不从心”,导致检测性能下降。
正是为了打破这种不匹配,研究者们开始探索 动态计算 的可能性,即让模型能够根据输入实例的复杂度,自适应地调整其计算路径或深度。YOLO-Master正是这一探索方向上的最新成果。
方法:YOLO-Master 的动态计算之道
YOLO-Master的整体框架依然是我们熟悉的YOLO-like结构,包含主干网络(Backbone)、颈部(Neck)和检测头(Head)。它的革命性创新,在于将一个名为 高效稀疏混合专家(Efficient Sparse Mixture-of-Experts, ES-MoE
) 的模块巧妙地融入了主干和颈部网络中。
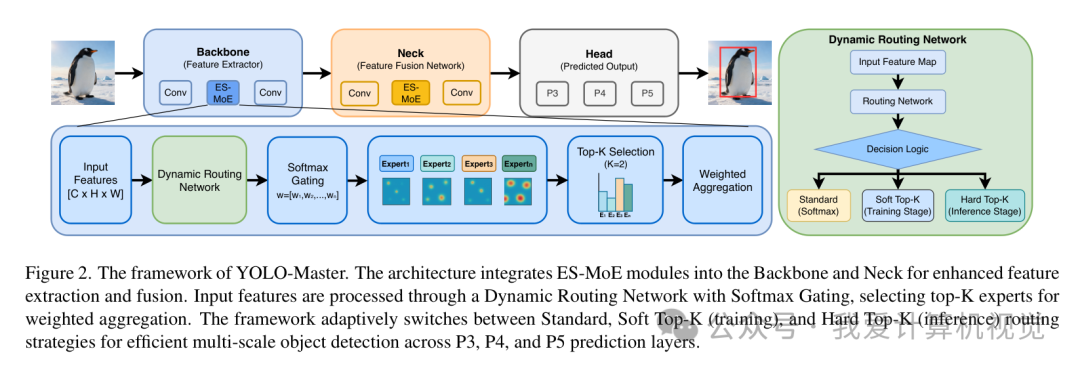
上图清晰地展示了YOLO-Master的架构。当特征图流经网络时,ES-MoE模块会像一个智能的“调度中心”,决定激活哪些“专家”来处理这些特征。
核心模块:ES-MoE 与动态路由
每个ES-MoE模块由两部分构成:一组“专家”子网络和一个“动态路由网络
”。
- 专家(Experts):可以理解为一些并行的、轻量化的专业处理单元(比如几个卷积层或Transformer块)。论文中,为了在保持实时性的同时获取多尺度感受野,每个专家实际上是由不同卷积核大小(如 3, 5, 7…)的深度可分离卷积(DWConv) 构成的轻量化模块,而非计算量较大的 Transformer 块。它们各自学习,逐渐形成对不同类型特征的“专长”。
- 动态路由网络(Dynamic Routing Network):这是ES-MoE的“大脑”。它负责检查输入的特征图,然后生成一组权重,决定将“任务”分配给哪些专家,以及每个被选中专家的“发言权”有多大。
为了实现效率和性能的平衡,YOLO-Master的路由策略在训练和推理阶段是不同的:
- 训练阶段 (Soft Top-K) :路由网络会计算出所有专家的概率分布,然后选择概率最高的K个专家。这K个专家的输出会根据它们的概率进行加权求和。这样做的好处是,整个过程是可微的,梯度可以平滑地回传给所有被选中的专家,让它们都能得到有效训练。
- 推理阶段 (Hard Top-K) :为了追求极致的速度,路由策略变得更加“果断”。模型会执行 Hard Top-K 策略,仅计算选中的 K 个专家。这些专家的输出会根据路由网络生成的概率(重新归一化后)进行加权聚合(Weighted Aggregation)。这就实现了所谓的“稀疏激活”,虽然模型总参数量因为多个专家的存在而增加了,但单次前向传播的实际计算量(FLOPs)却得到了有效控制,甚至可能更低。
训练目标:鼓励“术业有专攻”

实验与结果
YOLO-Master的性能表现相当出色。
与SOTA模型的性能对比
首先来看最重要的COCO数据集
上的表现。
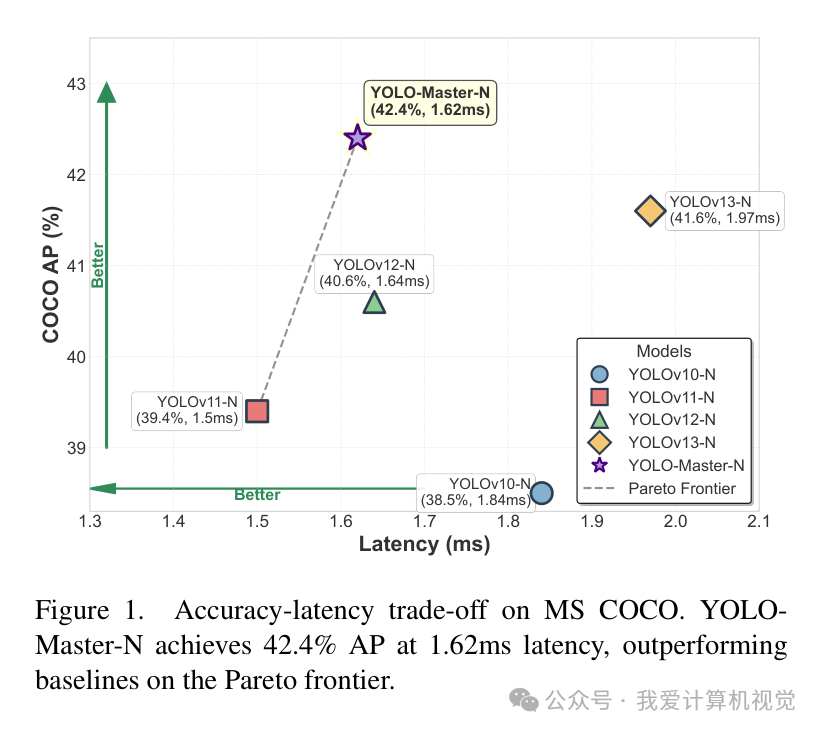
从上方的帕累托前沿图可以看出,在Nano级别的模型中,YOLO-Master-N在精度和延迟方面都达到了新的SOTA水准。
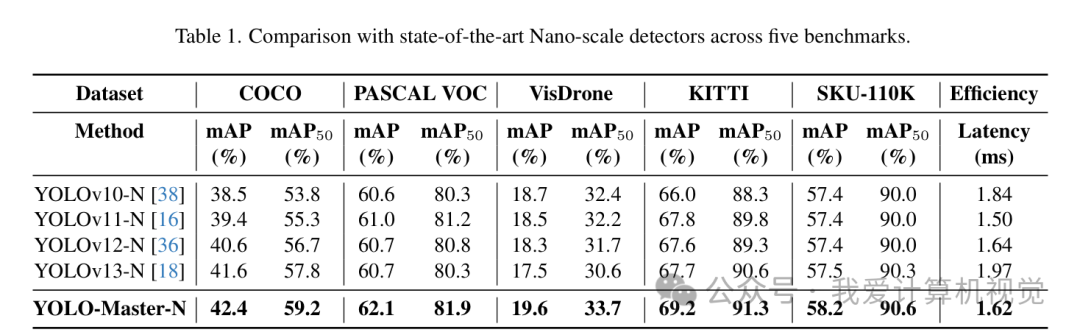
再来看这张横跨五个主流数据集的详细对比表。YOLO-Master-N在COCO数据集上以 1.62ms 的极低延迟,实现了 42.4% 的mAP,相较于YOLOv13-N,mAP提升0.8个点,速度快17.8%。在VisDrone、KITTI
等更具挑战性的场景中,它的优势更加明显。

定性对比图也直观地展示了YOLO-Master在复杂和密集场景下的检测能力,相比其他YOLO模型,它能更准确地识别出被遮挡或模糊的目标。
全方位的性能展示
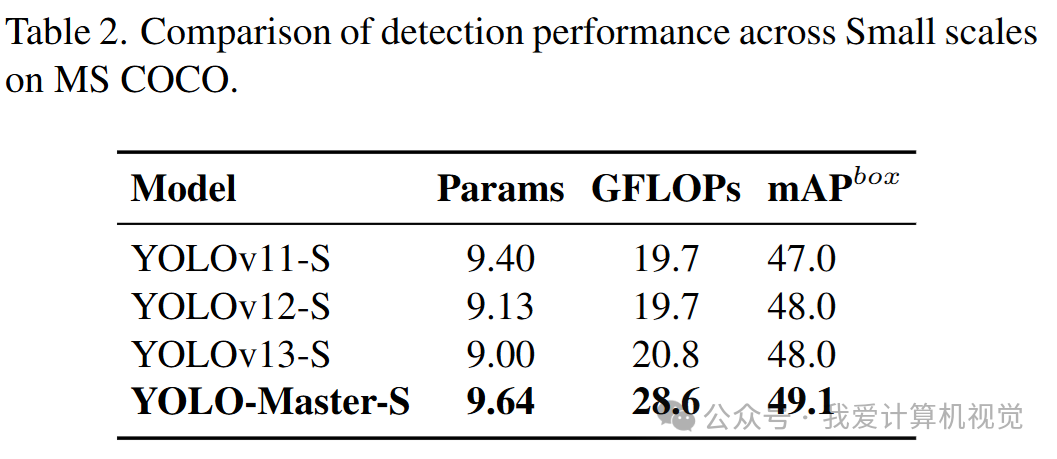
如下表,在小目标检测上,YOLO-Master 取得了明显的优势,证明其尺度自适应专家在挑战场景发挥了优势。
另外,YOLO-Master不仅在目标检测上表现优异,研究者还验证了其在分类和分割任务上的潜力。
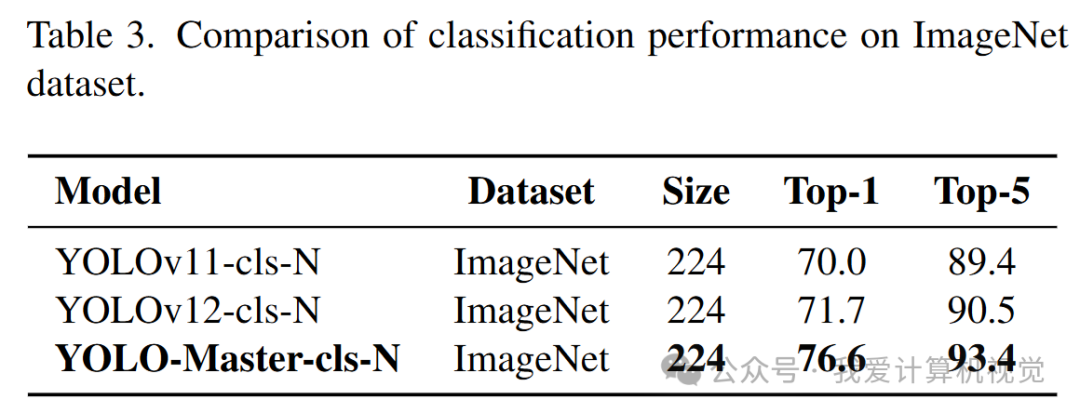
在ImageNet分类任务上,YOLO-Master-cls-N的Top-1准确率达到了76.6%,显著高于同级别的YOLOv11和YOLOv12。
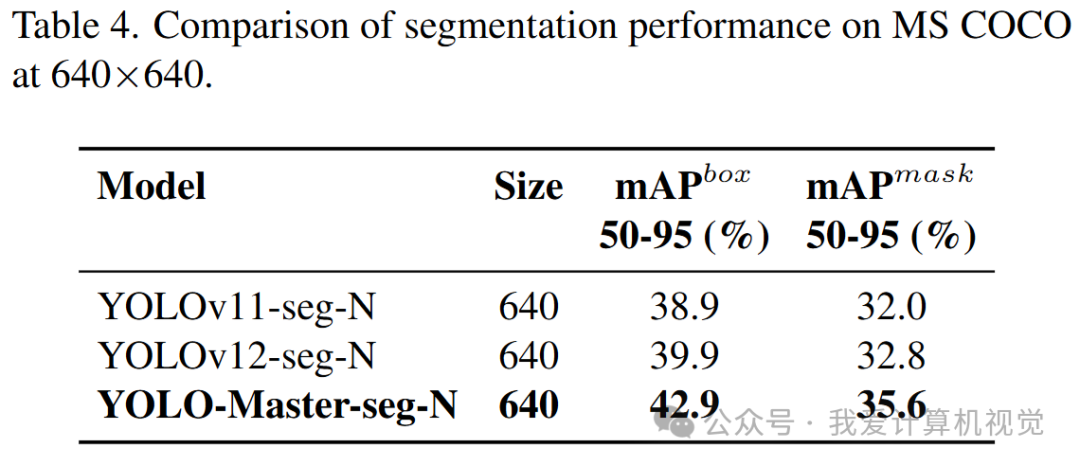
在COCO实例分割任务上,YOLO-Master-seg-N的box mAP和mask mAP也全面超越了对手。
在分类和分割任务中,取得了比检测更加明显的性能提升,这些结果进一步表明,ES-MoE作为一种通用的特征增强模块,其有效性可以迁移到多种视觉任务中。
一点思考
YOLO-Master将混合专家模型(MOE)的思想与YOLO架构相结合,证明了动态计算在平衡精度、速度和效率上的巨大潜力。
值得一提的是,作者已经开源了代码。目前已经开放了nano模型,更大尺寸的模型在训练中(由github得知),可能后续论文会更新。
安装后你可以像以往一样无痛调用它:
from ultralytics import YOLO
model = YOLO("yolo_master_n.pt")
results = model("path/to/image.jpg")
results[0].show()
发表回复