
原文链接:https://zhuanlan.zhihu.com/p/1938167958015815767
任意视角图像生成在自动驾驶领域具有重要潜力,但由于缺乏外推视角的真实数据,这阻碍了高保真生成模型的训练,因此仍然是一个具有挑战性的任务。
在本工作中,我们提出了ArbiViewGen,一个基于扩散的新框架,用于从任意视角点生成可控的相机图像。为了解决未见视角中缺乏真实数据的问题,我们引入了两个关键组件:特征感知自适应视角拼接
(FAVS)和跨视角一致性自监督学习(CVC-SSL)。
FAVS采用分层匹配策略,首先使用相机姿态建立粗略几何对应关系,然后通过改进的特征匹配算法进行细粒度对齐,并通过聚类分析识别高置信度匹配区域。在此基础上,CVC-SSL采用自监督训练范式,其中模型使用扩散模型从合成的拼接图像重建原始相机视角,在不要求外推数据监督的情况下强制执行跨视角一致性。我们的框架仅需要多相机图像及其相关姿态进行训练,无需额外的传感器或深度图。
据我们所知,ArbiViewGen是第一个能够在多种车辆异构配置中进行可控任意视角相机图像生成的方法。
研究动机与贡献
自动驾驶行业见证了端到端自动驾驶技术作为主要发展方向的出现。然而,多源传感器系统的异构配置带来了耦合挑战。使用不同传感器组合训练的模型难以在平台间转移和重用。当前自动驾驶系统存在相机配置差异,严重影响跨平台的数据复用,导致高开发成本和长周期。
为了解决这个问题,任意视角相机图像生成技术应运而生。通过使用有限的现有相机视角集从任意姿态生成高质量图像,可以实现不同车辆类型间的数据重用,并降低新模型的开发成本。然而,与一般场景重建不同,自动驾驶场景中的数据收集通常仅限于单一驾驶轨迹,导致3D空间中观察数据的稀疏性和同质性。这对于新颖视角合成特别成问题,在外推视角中严重缺乏真实数据:当渲染的视角偏离记录的轨迹时,无法获得直接监督训练的真实图像,这已成为限制该技术发展的核心瓶颈。
尽管进展迅速,现有的多视角图像生成方法仍然从根本上受到对目标视角真实监督的依赖的限制,这种资源在自动驾驶场景中本质上很稀缺。现有方法主要包括基于扩散的端到端方法和基于3D重建的两阶段方法。前者在稀疏或不完整视角下性能有限,后者对几何稀疏性高度敏感,易引发外推失真和伪影。这些方法都依赖目标视角的真实监督,难以适应自动驾驶场景中常见的非结构化数据分布。这些限制突出了核心挑战:缺乏新颖视角的真实数据阻止了大多数现有方法在此类场景中有效训练,特别是在真实世界的自动驾驶设置中。
本研究的主要贡献如下:
- 开发了一种纯视觉图像拼接算法,结合几何变换与分层特征匹配。它通过精确对齐和纹理融合实现外推视角高质量伪真实数据的自动构建,为训练提供可靠监督。
- 引入了基于循环重建的自监督学习范式,建立跨视角的双向映射。这种设计有效克服了新颖视角中缺乏真实监督的问题,并显著提高了生成质量。
- 为了启用定量评估,提出了一种新颖的图像质量评估策略,将从真实图像采样的彩色点云投影到目标视角。这建立了第一个用于跨不同车辆架构的可控任意视角生成的端到端评估框架。
方法总览
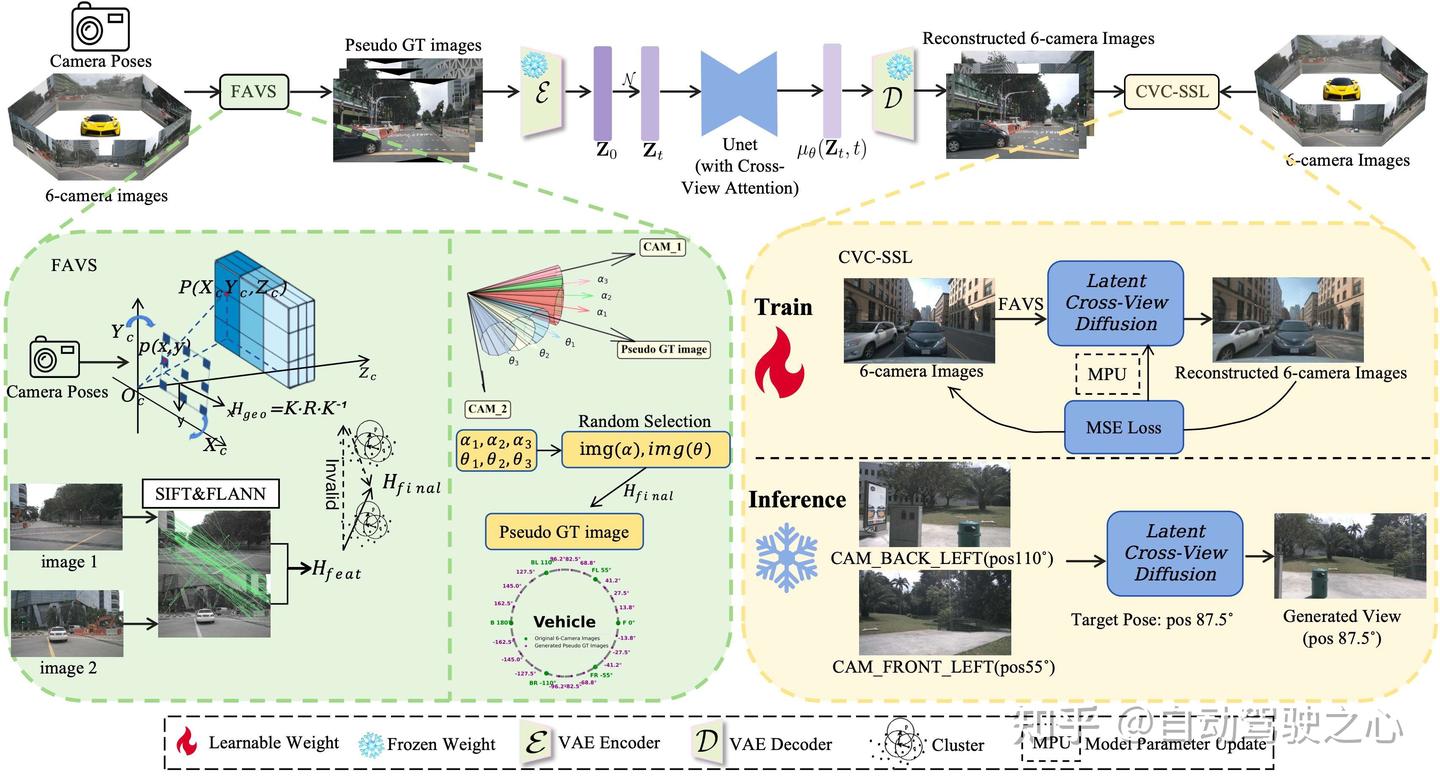
ArbiViewGen解决了多车辆自动驾驶场景中任意视角图像生成的挑战性问题,其中外推视角缺乏真实数据带来了重大困难。我们的方法可以基于有限的相机视角从任意目标视角合成高质量相机图像。提出的方法包含两个核心模块:特征感知自适应视角合成(FAVS)和跨视角一致性自监督学习(CVC-SSL)。
FAVS 模块仅凭借视觉输入,就能为新颖视角生成高质量的伪真实数据。其核心思路是通过分层优化策略,实现六个相机图像到任意目标视角的高质量拼接,具体包含几个递进的优化阶段:建立几何变换;特征匹配优化;目标对齐微调;自适应融合生成。
CVC-SSL模块建立在潜在扩散模型上,具有跨视角一致性注意力机制。在训练过程中,对于每个训练样本,先利用六张真实相机图像、对应的位姿信息以及目标位姿信息,再应用 FAVS 算法合成这些采样位姿下的伪图像,随后将两侧伪图像输入到配备几何引导跨视角注意力的扩散模型中,让模型学习重建原始真实图像作为预测目标。此外,几何引导跨视角注意力机制通过考虑不同相机视角观察同一平面场景时的单应性矩阵投影关系,进行几何引导的特征对齐,采用分层注意力机制处理不同深度层次的几何关系,并设计基于相对位姿的位置编码将几何信息融入注意力计算,以此建模不同视角间的对应关系。凭借这种基于注意力的模型所具备的生成能力,该框架能够通过参考有限数量的真实图像,有效外推生成高质量的新颖视角图像。
数据集
我们在nuScenes数据集
上进行实验,该数据集包含1,000个场景,通过使用原始六个相机为激光雷达点云着色并将其投影到目标视角以生成稀疏参考点,我们为外推视角构建了定量评估基准。
新视角评估
由于ArbiViewGen针对跨不同车辆平台的可控任意视角生成,没有先前方法提供直接可比性。我们采用应用基于旋转增强的DriveSuprim
作为baseline。
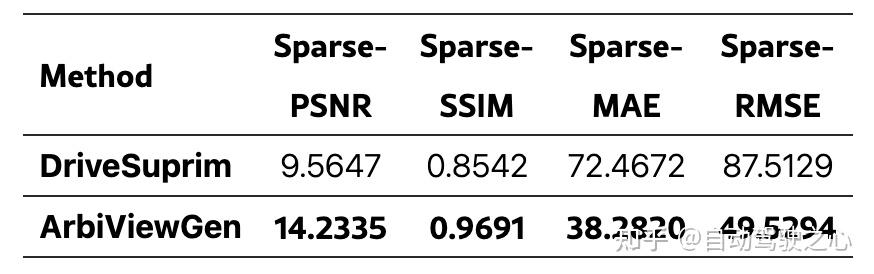
四个稀疏指标(PSNR、SSIM、MAE、RMSE)从投影到新颖视角的彩色激光雷达点云计算。ArbiViewGen在所有指标上一致优于基线,表明在稀疏监督下具有优越的保真度和结构一致性。
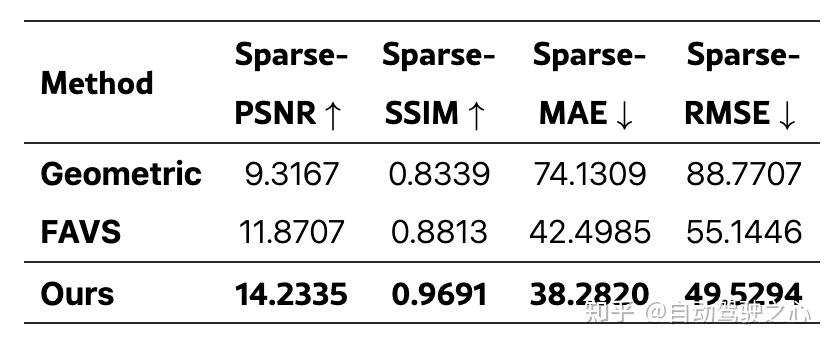
消融实验:特征感知拼接模块(FAVS)和跨视角一致性学习(CVC-SSL)都产生了明显的性能提升。完整模型在所有指标上达到最佳结果,确认了我们设计的有效性。
可视化
如图所示,我们在多角度相机旋转下可视化新颖视角合成结果。
使用简单基于旋转增强训练的DriveSuprim遭受几何失真和对象错位。
几何投影基线保持刚性对齐但在原始相机视角不为目标视角提供信息的区域引入撕裂和黑边。
FAVS通过利用相机姿态和特征对应关系改善对齐,但由于在那些外推方向缺乏源视角内容,仍然表现出不连续性和缺失区域。虽然不逼真,但FAVS提供了促进学习的粗略几何先验。
通过完整的ArbiViewGen流程,模型生成更结构一致和空间完整的图像,展示了对未见视角的更好泛化。





结论
在本工作中,我们介绍了ArbiViewGen:一个用于自动驾驶场景中任意视角图像生成的可控基于扩散的框架。通过集成特征感知拼接模块(FAVS)和跨视角一致性自监督学习策略(CVC-SSL),我们的方法有效缓解了外推视角缺乏真实监督的挑战,仅使用多相机图像和姿态信息即可实现任意视角合成。提出的框架增强了自动驾驶系统在各种传感器配置中的适应性和鲁棒性,促进跨平台部署和可扩展数据重用。尽管实验结果有希望,但该框架在高度动态环境中捕获细粒度结构细节方面仍面临限制,特别是在稀疏几何约束下。未来工作将专注于整合稀疏到密集监督信号,如基于激光雷达的深度先验和语义一致性约束,以进一步增强新颖视角生成的质量。
发表回复