
原文链接:https://zhuanlan.zhihu.com/p/1933458904249012984
TUM最新的综述!全面梳理并汇总了自动驾驶中LLM/VLM/MLLM/扩散模型和世界模型最优秀的工作,系统的梳理了相关的数据集、BenchMark等等,非常棒的工作,推荐大家仔细看看~
对于自动驾驶车辆而言,在复杂环境中实现安全导航的关键在于处理各种多样且罕见的驾驶场景。基于仿真和场景的测试已成为自动驾驶系统开发与验证的关键方法。传统的场景生成依赖于基于规则的系统、知识驱动模型和数据驱动合成方法,但往往产生的场景多样性有限,且难以生成真实的、安全关键的案例。随着基础模型(Foundation Models)的出现——这类模型代表了一种新一代的、经过预训练的通用人工智能模型——开发者能够处理异构输入(例如,自然语言、传感器数据、高精地图和控制动作),从而实现对复杂驾驶场景的合成与解读。本文对基础模型在自动驾驶领域中用于场景生成与场景分析的应用进行了综述。本综述提出了一个统一的分类体系,涵盖了大语言模型(LLMs)、视觉-语言模型(VLMs)、多模态大语言模型
(MLLMs)、扩散模型(DMs)和世界模型(WMs)在自动驾驶场景生成与分析中的应用。此外,我们回顾了相关方法论、开源数据集、仿真平台和基准挑战,并考察了专门针对场景生成与分析的评估指标。最后,本文总结了当前面临的开放性挑战和研究问题,并展望了未来有前景的研究方向。
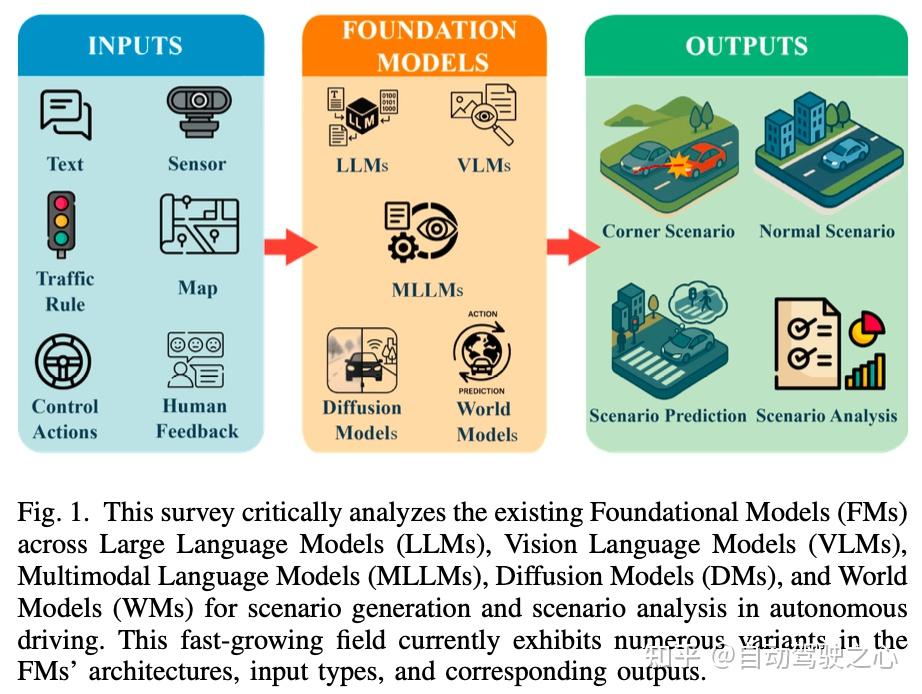
简介
近年来,自动驾驶(Autonomous Driving, AD)技术取得了快速进展,已达到在特定运行设计域(Operational Design Domains, ODDs)内,人类干预极少甚至完全不需要的阶段。自2018年以来,Waymo等公司已成功部署了完全自动驾驶的机器人出租车服务,这些服务运行于SAE四级,证明了在特定城市环境中实现无人驾驶出行的可行性。截至2025年,Waymo每周可提供25万次商业载客服务。这些进步得益于对高可靠性模块化自动驾驶软件功能(包括感知、预测、规划和控制)的开发与严格验证。除了传统的模块化架构,基于端到端学习的方法也已兴起,该方法利用深度学习处理原始传感器数据,并直接生成轨迹或控制指令。
基于场景的仿真测试是评估和验证自动驾驶系统安全性与性能的关键环节。作为一种比实车测试更具成本效益的替代方案,它能够仿真出逼真、可复现且可控的驾驶环境,尤其擅长复现安全关键场景,特别是那些在真实世界数据集中往往缺失的罕见或难以捕捉的边缘案例(corner cases)。因此,系统性地生成和分析驾驶场景的能力对于基于场景的测试至关重要,它是推动感知、规划、控制等自动驾驶功能开发、验证与确认的关键使能技术。
机器学习领域的最新进展,特别是大规模基础模型(Foundation Models, FMs)的出现,为增强自动驾驶领域基于场景测试的真实性、多样性和可扩展性提供了新的机遇。基础模型由斯坦福大学以人为本的人工智能研究院(Stanford Institute for Human-Centered Artificial Intelligence, HAI)于2021年8月提出,用于描述一类在大规模、多样化数据集上通常通过自监督学习进行训练的模型。与传统机器学习模型(通常为特定、狭义的任务而训练)不同,基础模型可以通过提示(prompting)或微调(fine-tuning)等技术,适应广泛的下游任务。这些模型在自然语言处理(NLP)、视觉理解和代码生成等多个领域均展现出强大的性能。在自动驾驶领域,基础模型因其将大规模预训练所获得的通用知识与对特定AD任务的高效适应能力相结合,而受到广泛关注。
A. 所考虑文献的范围
在本综述中,我们聚焦于使用基础模型解决自动驾驶场景生成与场景分析的文献(见图1)。我们的调研基于在Google Scholar上的关键词搜索。完整的关键词列表可在论文的GitHub仓库中获取。
为确保调研的广度与相关性,我们纳入了经过同行评审的会议和期刊论文,以及来自arXiv的预印本。尽管arXiv上的出版物未经正式同行评审,但它们通常能及时呈现具有影响力的研究成果,尤其是在基础模型应用等快速发展的领域。我们的调研涵盖了2022年10月至2025年5月期间发表的论文,主要关注自动驾驶、计算机视觉、机器学习/人工智能(AI)和机器人学领域的会议与期刊。图2展示了论文发表数量的月度趋势及其在不同主题(如会议、期刊或预印本平台)上的分布情况。每篇论文对应的完整出版物列表及可用的开源代码(如有)均包含在论文的GitHub仓库中。
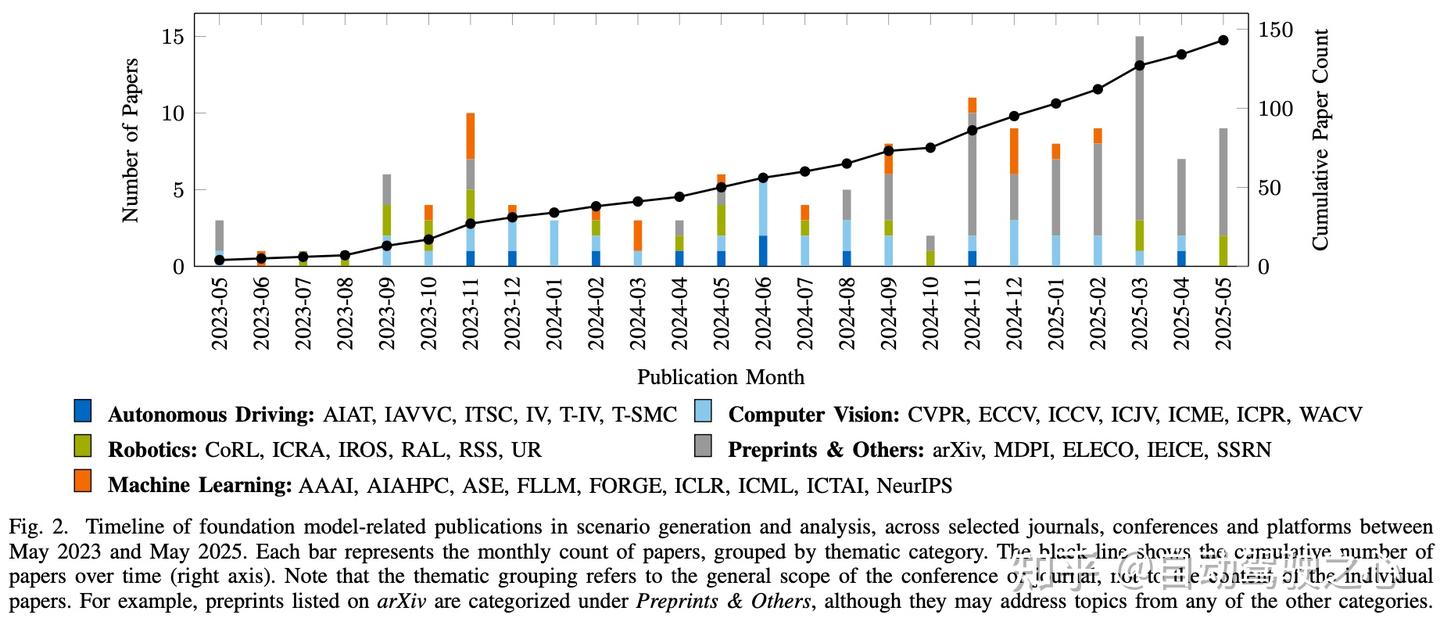
B. 综述结构
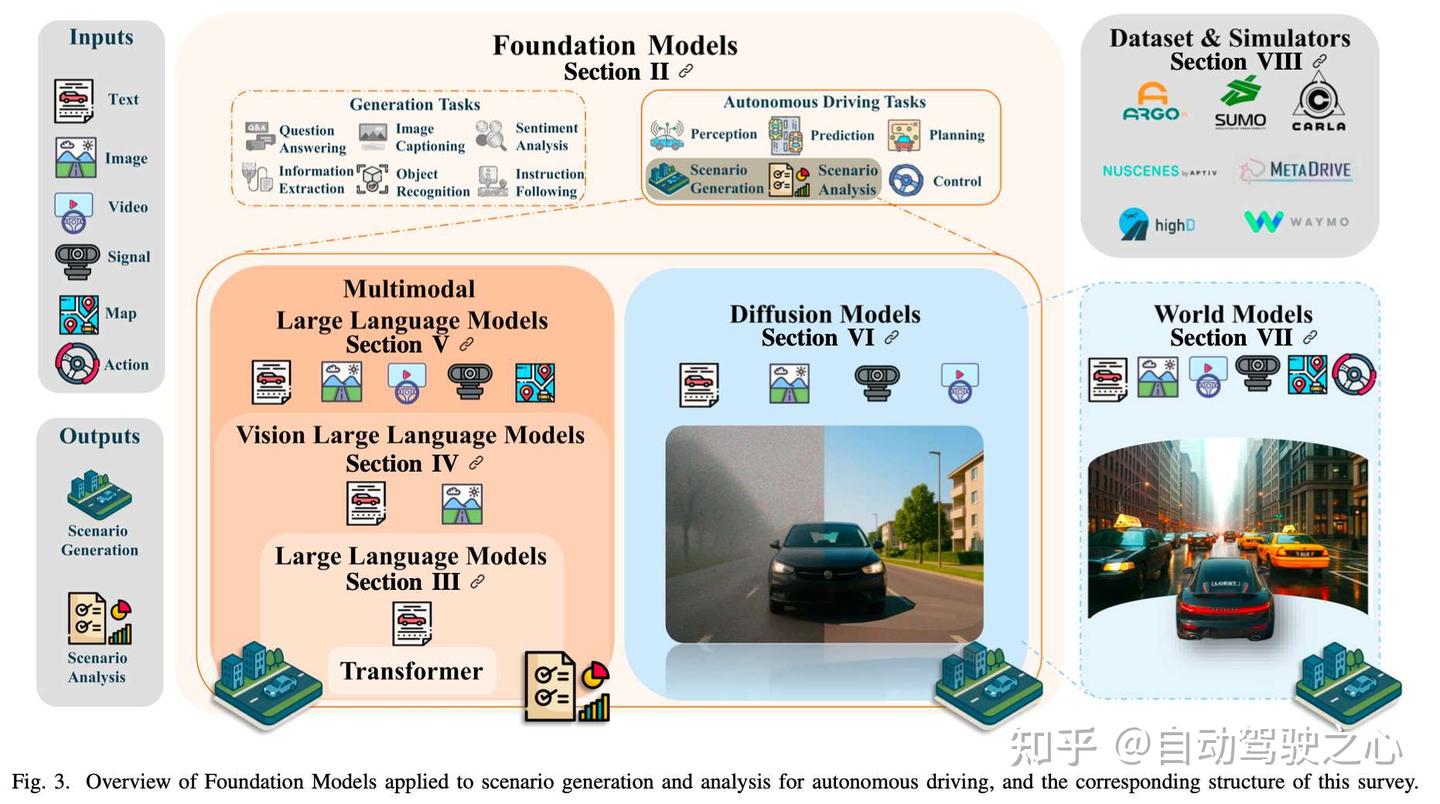
本综述的结构如图3所示。第二部分介绍了基础模型,并对场景生成与分析相关的综述文献进行了批判性回顾,内容涵盖经典方法和基于基础模型的最新进展。第三、四、五部分系统地探讨了基于语言的基础模型,首先介绍基本概念,然后深入讨论大语言模型(LLMs)、视觉语言模型
(VLMs)和多模态大语言模型(MLLMs)在场景生成与分析中的最新应用。第六和第七部分则聚焦于以视觉为中心的基础模型,详细阐述了扩散模型(DMs)和世界模型(WMs)的原理及其在场景生成中的相关性。第八部分调研了与自动驾驶场景生成和分析相关的公开数据集和仿真基准,并重点介绍了该领域的主要竞赛挑战。最后,第九和第十部分识别了开放的研究问题并概述了未来的研究方向,第十一部分总结了本综述的主要发现。
相关工作回顾
A. 基础模型的发展
基础模型(Foundation Models, FMs)在各种生成任务中展现出了极强的通用性。FMs这一术语由斯坦福大学以人为本的人工智能研究所(HAI)于2021年提出,指代一类在大规模、广泛的无标签数据集上进行训练,并可适应多种下游任务的模型。如图3所示,它们支持问答(QA)、图像描述、情感分析、信息提取、目标识别和指令跟随等多种能力。其核心在于FMs的跨模态适应性,这使得模型具备了生成能力,并能深刻理解给定的上下文。因此,基础模型与“生成式AI”(generative AI)这一术语有部分重叠,但代表了不同的概念:前者指代通用的、可适应的模型;后者则指代内容生成功能。
FMs得以广泛普及的关键时刻是OpenAI于2021年发布GPT-3,它将大语言模型(LLMs)带入了更广泛的AI社区。这一发展建立在开创性工作“Attention Is All You Need”之上,该工作引入了Transformer架构和自注意力机制。与早期的序列模型不同,Transformer能够利用GPU和TPU高效地对长输入序列进行并行训练。在Vaswani等人的工作基础上,涌现出了一系列模型,包括:BERT,一种专为掩码语言建模优化的编码器(encoder-only)模型;GPT,一种用于自回归生成的解码器(decoder-only)模型;以及T5,一种专为文本到文本转换设计的编码器-解码器(encoder-decoder)架构。这些模型都利用海量无标签文本语料库进行自监督学习,并通过提示(prompting)或微调(fine-tuning)作为预训练的骨干网络,服务于各种下游任务。
Transformer的成功迅速扩展到自然语言处理(NLP)之外。基于Transformer的设计已成功应用于视觉理解、语音处理、表格数据和多模态学习。这些努力进而催生了视觉语言模型(VLMs),如CLIP,以及多模态大语言模型(MLLMs),如LLaVA,它们支持联合的文本-图像处理,并具备跨模态能力,展现出类似推理的功能。
与此同时,扩散模型(DMs)的引入也极大地推动了视觉和音频领域的生成式建模。去噪扩散概率模型(DDPMs)的提出为生成任务建立了一个稳健的框架,它通过一个前向加噪过程和一个学习到的反向去噪过程来合成高质量的样本。DDPMs通常使用U-Net架构进行训练,能够很好地扩展到大规模无标签数据集,并在各种图像领域表现出色。后续的改进包括:去噪扩散隐式模型(DDIM),它加速了采样过程;潜在扩散模型(LDMs),它在压缩的潜在空间中运行,提高了效率;以及视频扩散模型(VDM),它结合了时空结构,确保了帧间的一致性。
此外,世界模型(WMs)被提出用于学习交互式环境的紧凑表示。这些模型通常由三个组件构成:一个视觉编码器(例如,变分自编码器(VAE))、一个记忆模块(例如,循环神经网络(RNN))和一个控制器(例如,进化策略)。最近的进展将基础模型集成到这些模块中,例如,用扩散模型(DMs)或大语言模型(LLMs)来替换视觉或记忆模块,以增强其推理能力和现实感。这些集成模型可以从多模态输入(例如,文本、视频、传感器数据)中学习环境的动态,并为下游任务(如场景生成、规划和控制)生成可操作的表示。
基础模型在自动驾驶中的应用
近期的研究探索了将基础模型(FMs)集成到自动驾驶(AD)系统中,利用其适应性和多模态能力,适用于模块化和端到端两种架构。综述文献对当前的研究格局提供了全面的概述,涵盖了LLMs、VLMs、MLLMs、DMs和WMs。尽管这些工作涵盖了感知、规划、决策、仿真和测试,但并未明确阐述FMs在场景生成与分析中的具体作用。
关于与生成式AI的交叉领域,Wang等人回顾了自动驾驶堆栈中的生成模型。虽然其范围广泛,但该综述采用了以模型为中心的视角,缺乏对场景生成的聚焦讨论。其中,扩散模型(DMs)的讨论并未与世界模型(WMs)区分开来,而语言模型的应用仅局限于问答(QA)任务。因此,该综述在基础模型驱动的场景生成与分析方面缺乏深度,而这正是本文旨在解决的问题。
- 自动驾驶中的大语言模型(LLMs):Zhu等人的综述回顾了LLMs在模块化自动驾驶系统中的集成,重点讨论了感知、决策、控制和端到端方法。类似地,Wu等人研究了LLMs在多智能体感知、决策和仿真中的应用。然而,这两篇综述主要关注自动驾驶任务的更广泛范畴,对场景生成的覆盖非常有限。例如,Zhu等人仅简要提及了数据集生成,而Wu等人仅在车辆-助手交互的背景下讨论了场景生成。最后,Li等人回顾了LLMs在模块化和端到端自动驾驶系统中实现类人推理的作用,并强调了训练和集成策略,这些内容与我们的主题(场景生成与分析)无关。
- 自动驾驶中的视觉语言模型(VLMs):综述探讨了VLMs在一系列自动驾驶任务中的应用,包括场景理解、视觉推理以及涉及扩散模型和世界模型的数据集生成。尽管提到了一些与场景生成相关的研究,但其讨论缺乏分类和深度,没有对所涉及的数据集、模型架构或生成技术进行详细分析。
- 自动驾驶中的多模态大语言模型(MLLMs):Cui等人的综述聚焦于MLLMs的架构、模态融合及其在AD任务中的应用。Fourati等人的综述将XLMs定义为LLMs、VLMs和MLLMs的结合,回顾了它们在AD中的应用,涵盖了概念、工作流程和技术。最后,Li等人的综述探讨了LLM和MLLM在不同AD模块中的应用,涵盖了集成和训练技术。然而,在这三篇综述中,场景生成仅被简要提及,并非其主要关注范围。
- 自动驾驶中的扩散模型(DMs)和世界模型(WMs):Guan等人概述了世界模型在AD中的应用,重点关注其在场景生成、运动预测和控制中的作用。Tu等人进一步探讨了驾驶世界模型,将其分为2D场景演化、3D占用预测和无场景范式。然而,这两篇综述都缺乏对场景生成实际应用的清晰分类,未能区分DMs和WMs,也没有对底层方法进行深入的技术分析。
自动驾驶中的场景生成
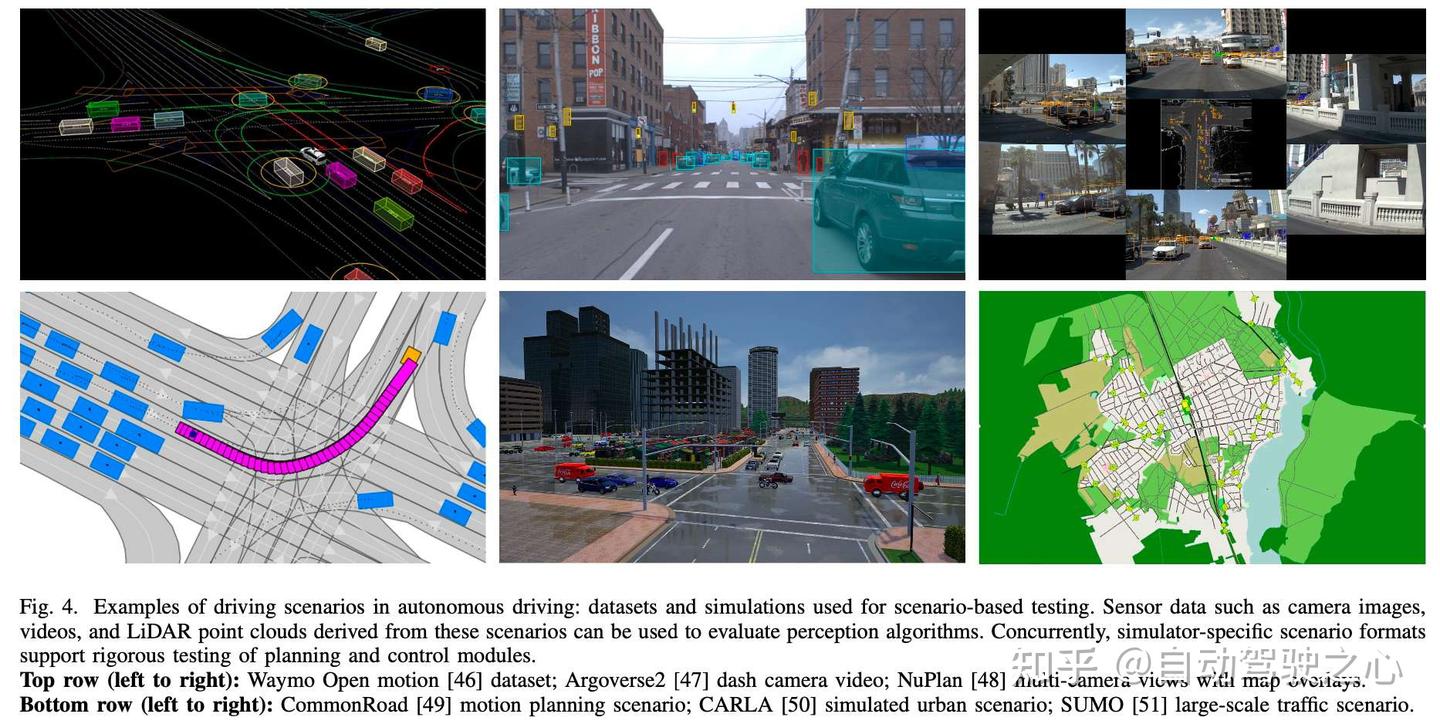
自动驾驶中的场景格式多种多样,从带注释的传感器数据、多摄像头视频流,到基于地图的布局、模拟的城市场景,再到交通级别的环境(例如OpenScenario2)。图4展示了不同格式的驾驶场景示例。
- 基于经典方法的综述:大多数现有的综述文献都聚焦于经典方法(即非基础模型驱动的方法)进行场景生成。Nalic等人介绍了知识驱动和数据驱动的生成方法,并讨论了用于场景评估的安全性指标。他们还提出了一个六层模型,用以捕捉场景的所有核心组成部分。Ding等人将场景生成方法分为数据驱动、对抗式和基于知识的方法,并对每种方法背后的具体机制提供了深入的见解。他们还强调了深度生成模型在合成基于图像和视频的场景中的作用。与ISO/WD PAS 21448标准3(预期功能安全,SOTIF)保持一致,Schutt等人从功能、逻辑和具体三个抽象层次上考察了场景生成。他们的综述涵盖了基于机器学习的生成、基于优化的场景探索、从驾驶数据中提取场景以及手动场景设计。
- 基于基础模型的综述:
- 基础模型综述:Huang等人概述了各种类型的基础模型,并简要讨论了场景生成。然而,他们的分析仅限于输入模态和模型类型,没有涉及具体的技术或评估策略。
- 视觉语言模型(VLMs)综述:Yang等人探讨了LLMs和VLMs在感知、问答和生成等任务中的应用。他们提到了使用VLMs、DMs和WMs进行场景生成,但并未对这些模型类型进行清晰的区分。尽管引用了多种评估指标,但这些指标并未按任务或应用场景进行组织。Tian等人对自动驾驶中的VLMs进行了更结构化的综述,涵盖了LLMs、VLMs和WMs,特别关注了通过VLM引导的生成进行交通仿真及其与扩散模型的集成。然而,该综述缺乏关于输入模态、场景生成技术以及模型类型区分的信息。
- 扩散模型(DMs)和世界模型(WMs)综述:Fu等人回顾了视频生成和世界模型,涵盖了基于扩散、自回归和强化学习的方法。Feng等人专注于世界模型,将其输出分为图像、鸟瞰图和3D点云,并讨论了语义分割和占用预测等评估指标。然而,这两篇综述都没有将模型输出直接与场景生成任务联系起来。它们也未能区分独立的DMs和WMs,并且缺乏对具体技术和评估策略的讨论。
自动驾驶中的场景分析
场景分析是指对驾驶场景进行的系统性评估,如图4所示。它涵盖了场景评估、场景理解、风险评估、异常检测和事故预测等任务。此外,还包括识别安全关键情况、评估系统鲁棒性,以及在仿真和真实世界环境中支持明智的决策制定。
- 基于经典方法的综述:Riedmaier等人提出了基于场景的安全评估方法的分类法,包括基于知识、数据驱动和证伪(falsification-based)的方法。他们强调使用关键性能指标(例如,碰撞时间、所需减速度)作为事故风险的代理,并倡导将形式化方法整合到安全验证中。 Mahmud等人回顾了诸如碰撞时间、后入侵时间(post-encroachment time)和避免碰撞的减速度率等近端替代指标。他们对这些指标进行了分类,并确定了关键的研究挑战,包括指标标准化、真实世界验证以及将其整合到基于仿真的场景分析框架中。
- 基于基础模型的综述:
- 基础模型综述:Huang等人在“感知数据标注”的术语下简要提到了场景分析,但并未根据其目标对任务进行分类。此外,他们既没有将数据集与具体研究关联起来,也没有讨论模态转换;因此,他们的综述并未聚焦于预训练的基础模型。
- 视觉语言模型(VLMs)综述:Yang等人在问答的背景下讨论了场景分析,主要关注数据集的描述。他们的分析较为有限,缺乏对输入模态、方法论、模型分类和性能评估指标的讨论。类似地,Tian等人将视觉问答(VQA)视为使用VLMs进行场景分析的一种形式,但涵盖的资源很少,对模型或方法的讨论也极少。
批判性总结
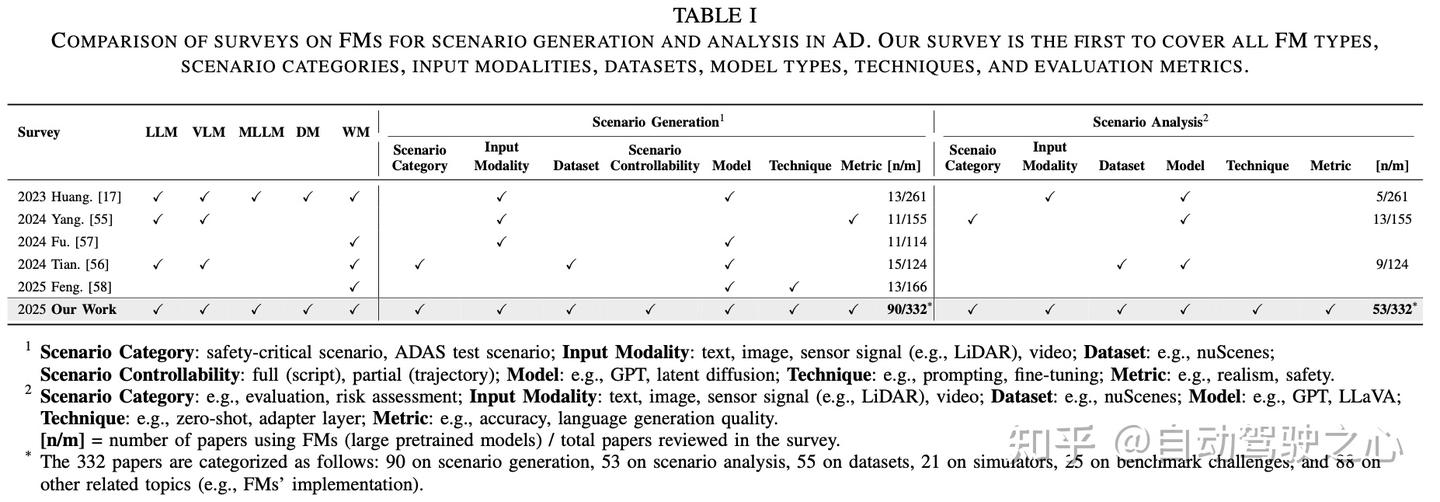
据我们所知,现有的关于自动驾驶和场景生成中基础模型(FMs)的综述(总结见表I)存在以下局限性:
- 缺乏对场景生成的聚焦:所有被回顾的综述均未明确地将基于基础模型的场景生成作为核心主题。即使被提及,场景生成也仅是简要带过,或缺乏对生成技术、场景可控性及评估指标的深入分析。
- 对场景分析的覆盖不完整:诸如场景理解、场景评估和风险评估等任务被忽视。即使被涉及,其分析也通常被简化为问答(question answering),很少关注特定任务的模型、方法或评估策略。
- 模态与任务间关联性有限:尽管一些综述考虑了基础模型的输入模态(例如,文本、图像和车辆传感器数据),但它们并未在这些模态与用于场景生成和分析的技术、模型及数据集之间建立清晰的联系。
- 缺乏结构化分类:此前没有工作提出一个涵盖场景生成与分析的、结构化的基础模型分类体系,该体系应同时考虑预训练模型类型、适应方法(例如,提示、微调)、输入模态、数据集和评估指标。
本文贡献
为解决现有文献综述的局限性,本综述对基础模型在场景生成与分析领域的研究格局进行了全面的评估(见表I)。综上所述,本工作提供了以下关键贡献:
- 基于基础模型的场景生成与分析综述:我们提出了首个针对自动驾驶中场景生成与分析的综述,涵盖了143篇使用基础模型的论文,涉及大语言模型(LLMs)、视觉语言模型(VLMs)、多模态大语言模型(MLLMs)、扩散模型(DMs)和世界模型(WMs)。
- 现有方法的结构化分类:我们的工作提供了一个结构化的分类体系,涵盖了所有基础模型类型(即LLMs、VLMs、MLLMs、DMs、WMs)、场景类别、输入模态、模型类型、数据集、技术方法和评估指标。
- 对数据集、仿真平台和现有基准竞赛的回顾:我们回顾了用于场景生成与分析的公开可用数据集和仿真器。同时,我们首次对自动驾驶领域基础模型的基准竞赛进行了系统性回顾。
- 识别开放性挑战与未来方向:我们识别了将基础模型应用于基于场景的测试中的关键开放性研究挑战。基于我们的分析,我们提出了未来的研究方向,以提升基础模型驱动方法在场景生成与分析中的适应性、鲁棒性和评估能力。
大语言模型LLM
大模型相关工作总结:
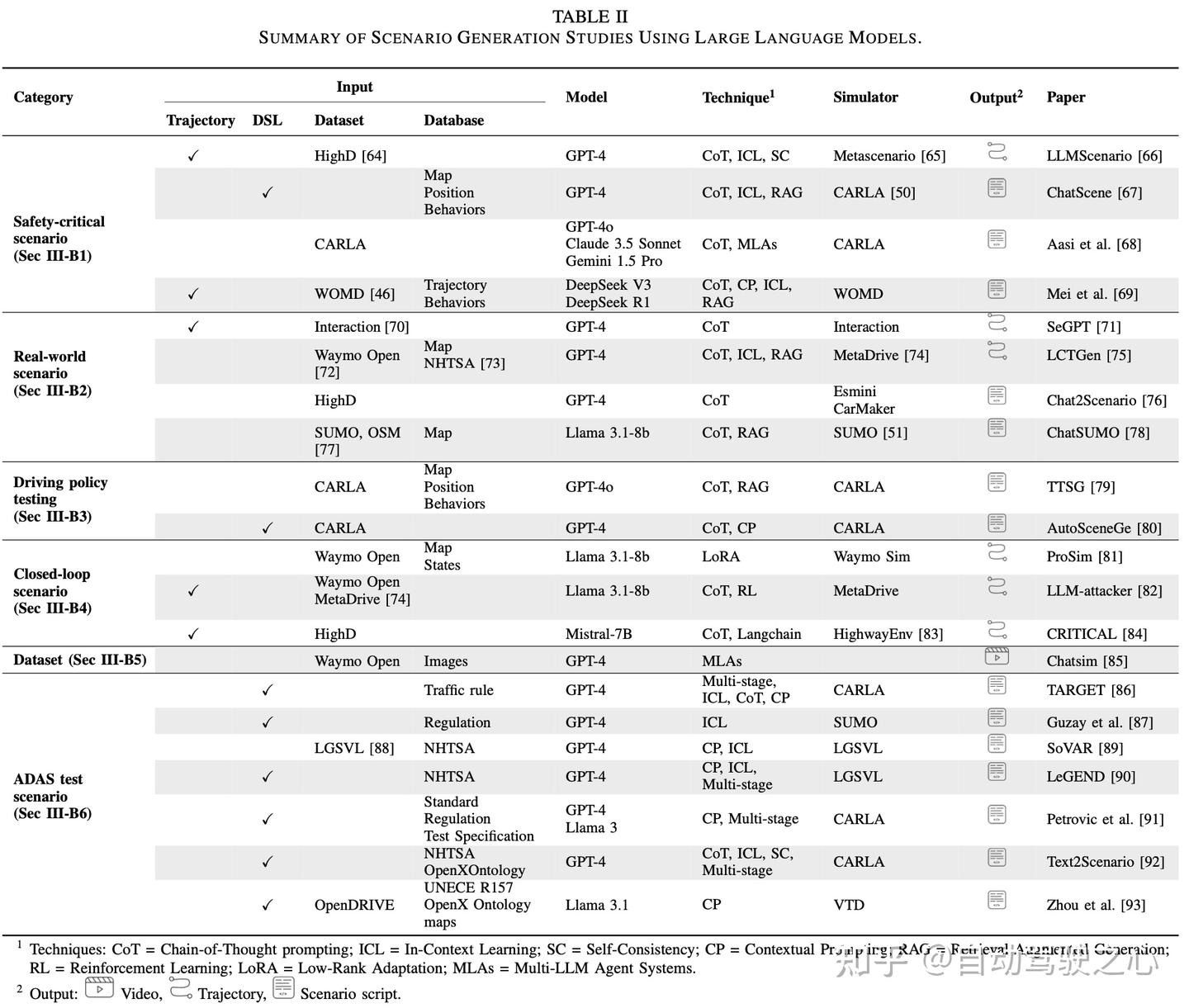
总体而言,基于大语言模型(LLM)的场景评估仍然依赖于高消耗的提示词(token-heavy prompting)和人工设计的提示(handcrafted prompts)。新兴的推理模型,如OpenAI o1和DeepSeek-R1
,可能会实现更高效、零样本(zero-shot)的评估方法。
评估指标:场景评估采用任务特定的准确性指标:
- 真实性(Realism):通过鲁棒性分数来衡量,该分数评估当同一场景受到扰动时(例如,智能体行为发生变化),LLM表现的一致性。更高的鲁棒性表明模型能更好地泛化到现实世界的变化中。
- 关键性(Criticality):通过识别高风险智能体的准确率来衡量,这些智能体很可能会导致碰撞。
- 行为分类(Behavior classification):通过评估LLM将驾驶行为分类为预定义风格(如激进、谨慎)或预定义性能水平的准确性来衡量。
视觉大语言模型VLM
VLM相关工作的回顾:
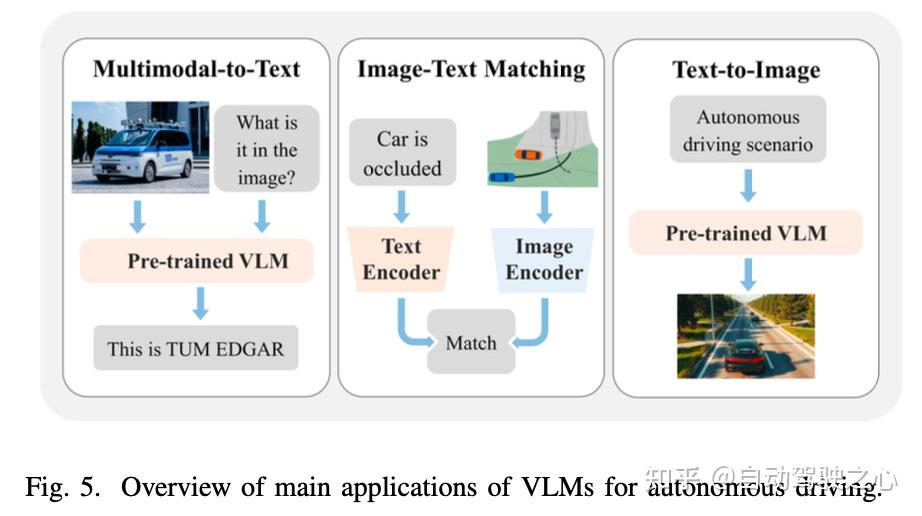
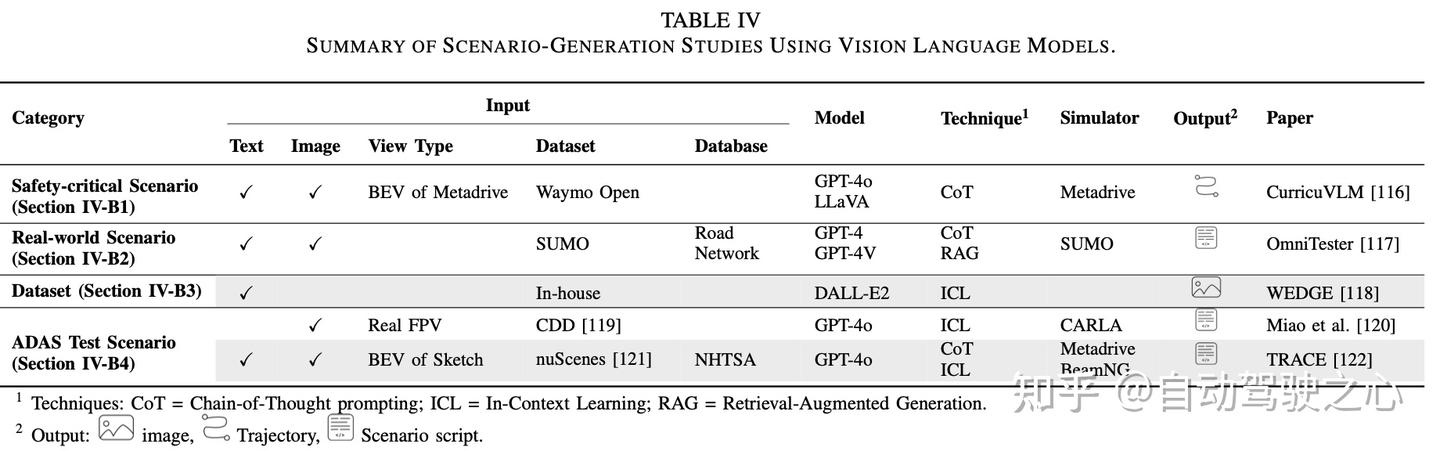
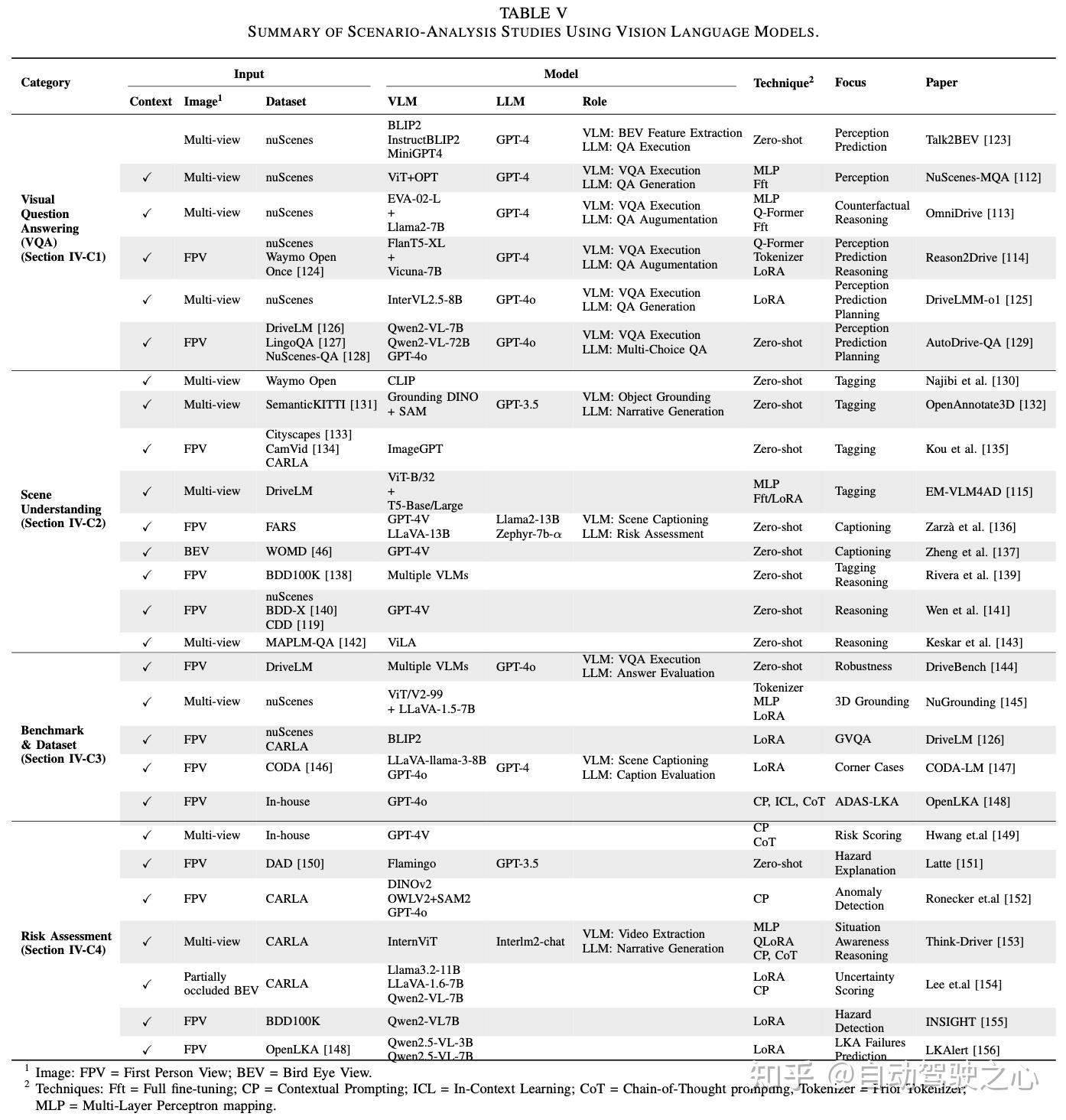
为了实现实际应用部署,我们必须通过模型压缩、高效的提示工程以及专为自动驾驶汽车车端执行优化的轻量化视觉语言模型(VLM)架构,来降低推理延迟和资源消耗。
评估指标:
- 风险评分(Risk Scoring):通过分类准确率和由人工评估的解释质量来衡量。
- 危险与异常检测(Hazard and Anomaly Detection):通过定位准确率和人工评估的可解释性,以及异常物体检测的准确率来评估。
- 风险预测与故障预测(Risk Forecasting and Failure Prediction):通过不确定性评分的质量、动作准确率、二元故障分类准确率以及事故发生时间(time-to-accident)等指标来衡量性能。
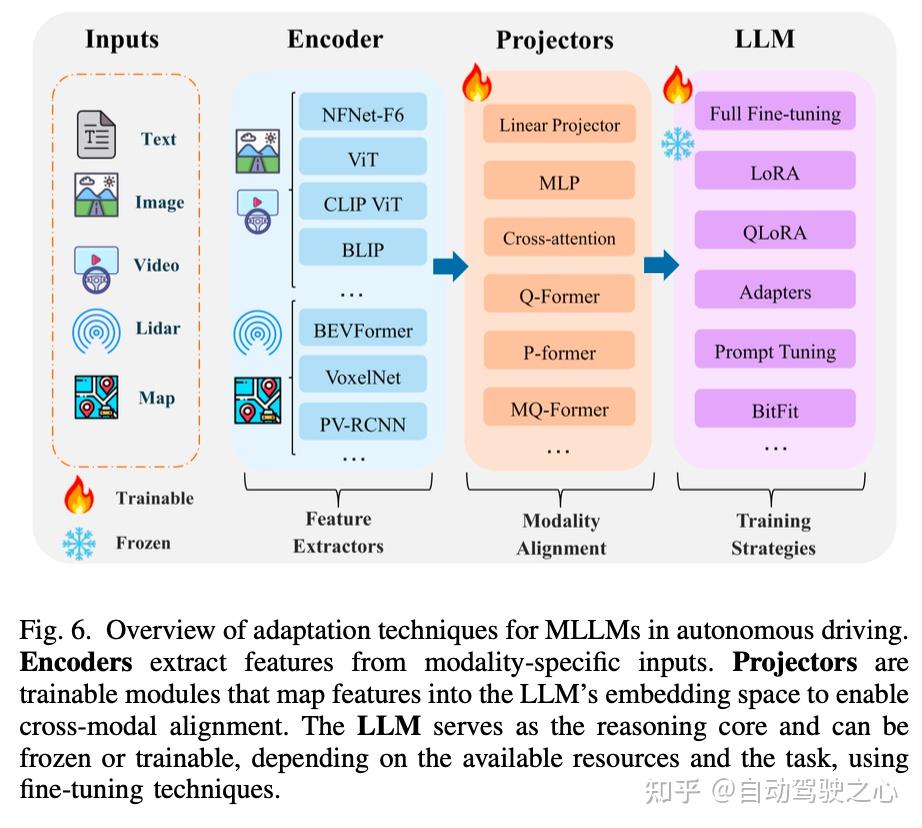
多模态大模型MLLM
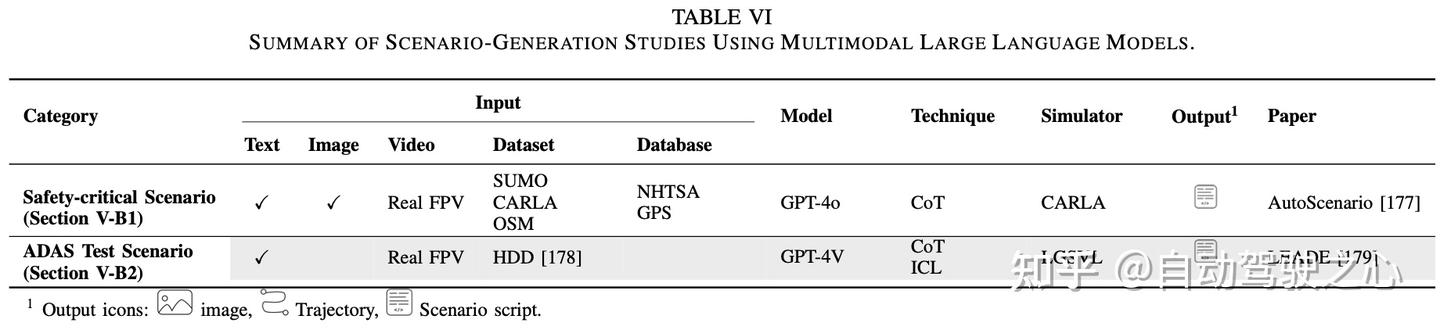
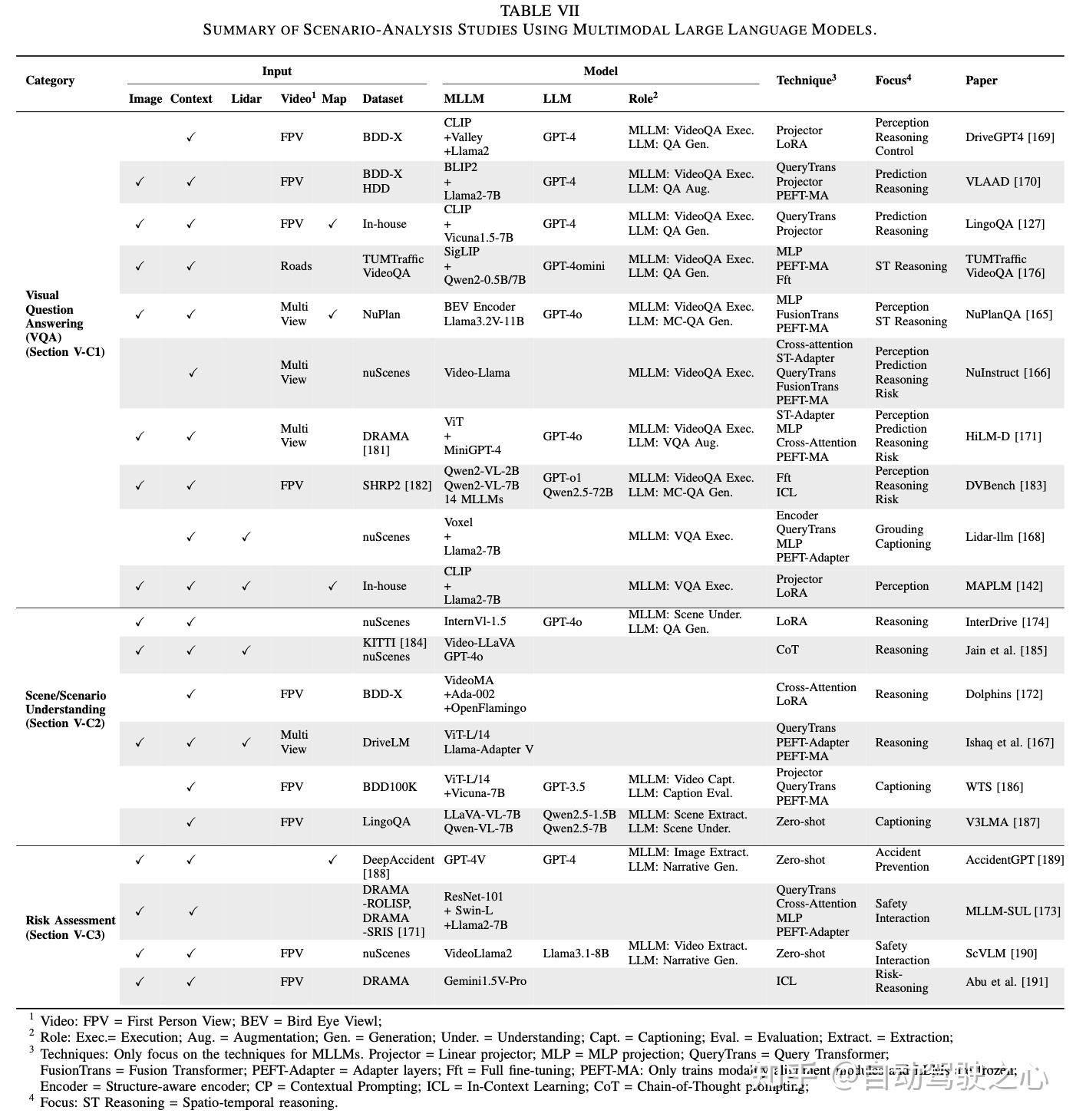
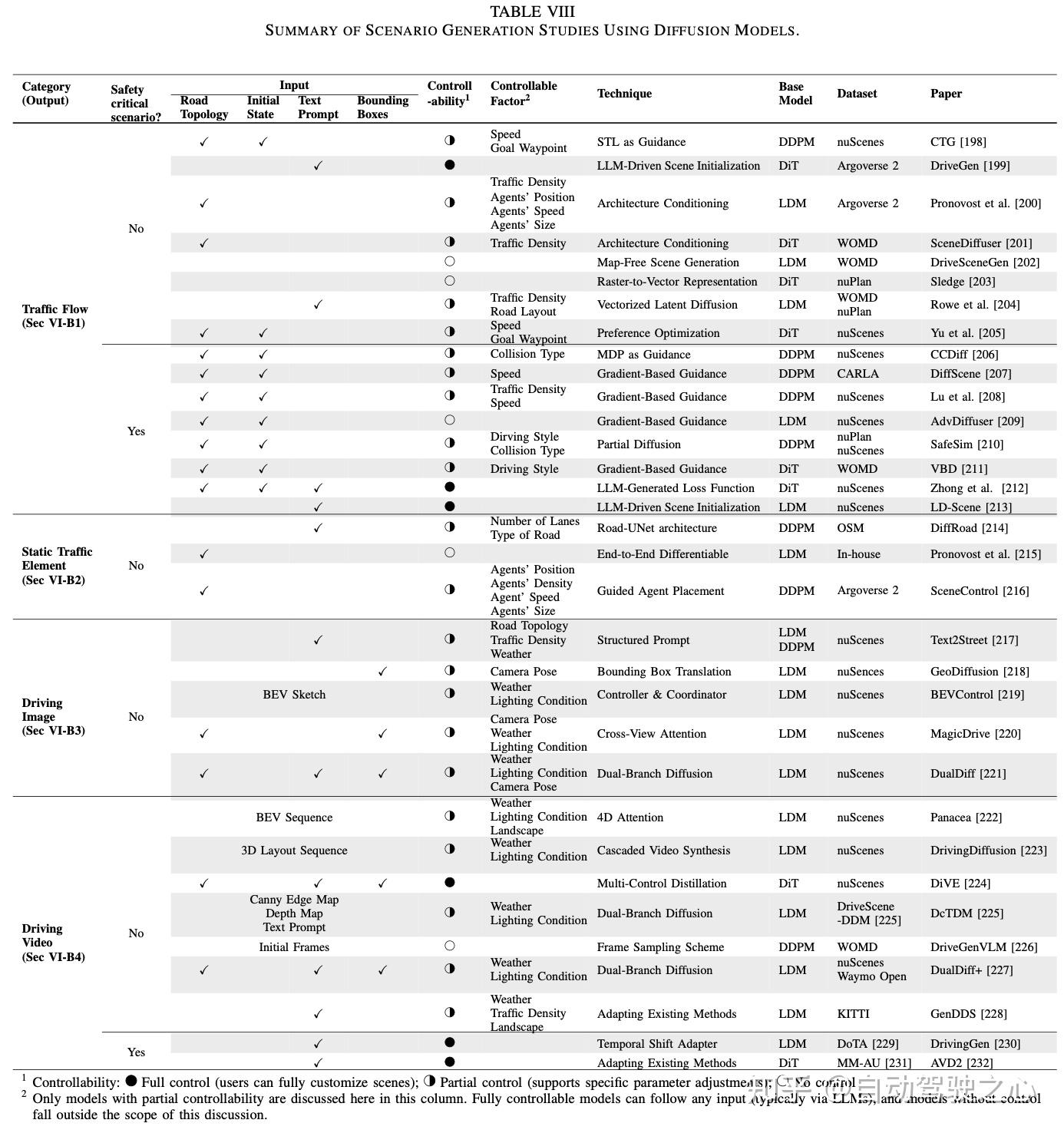
扩散模型

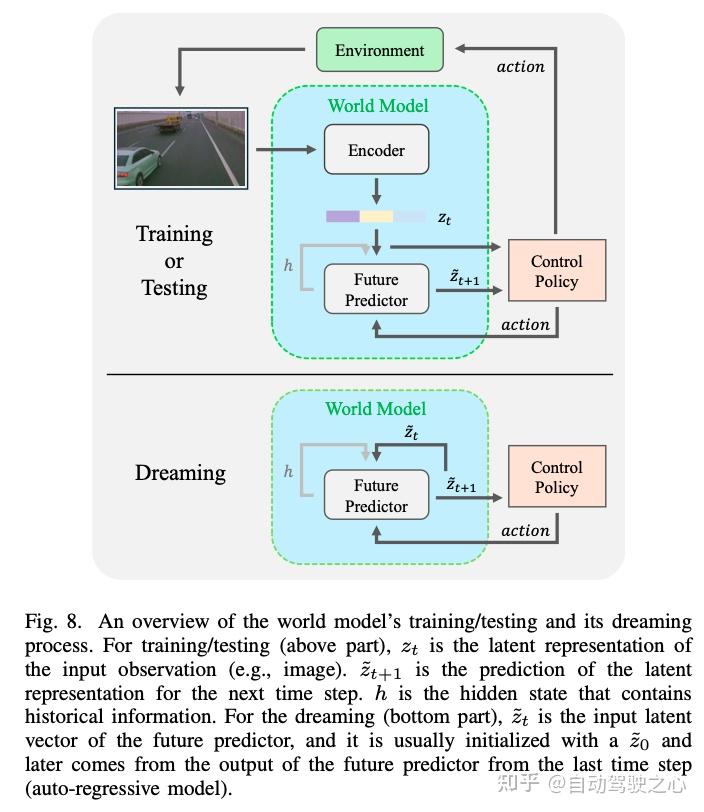
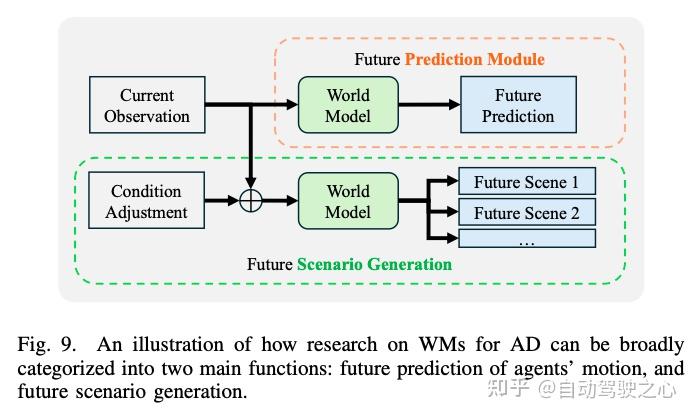
世界模型
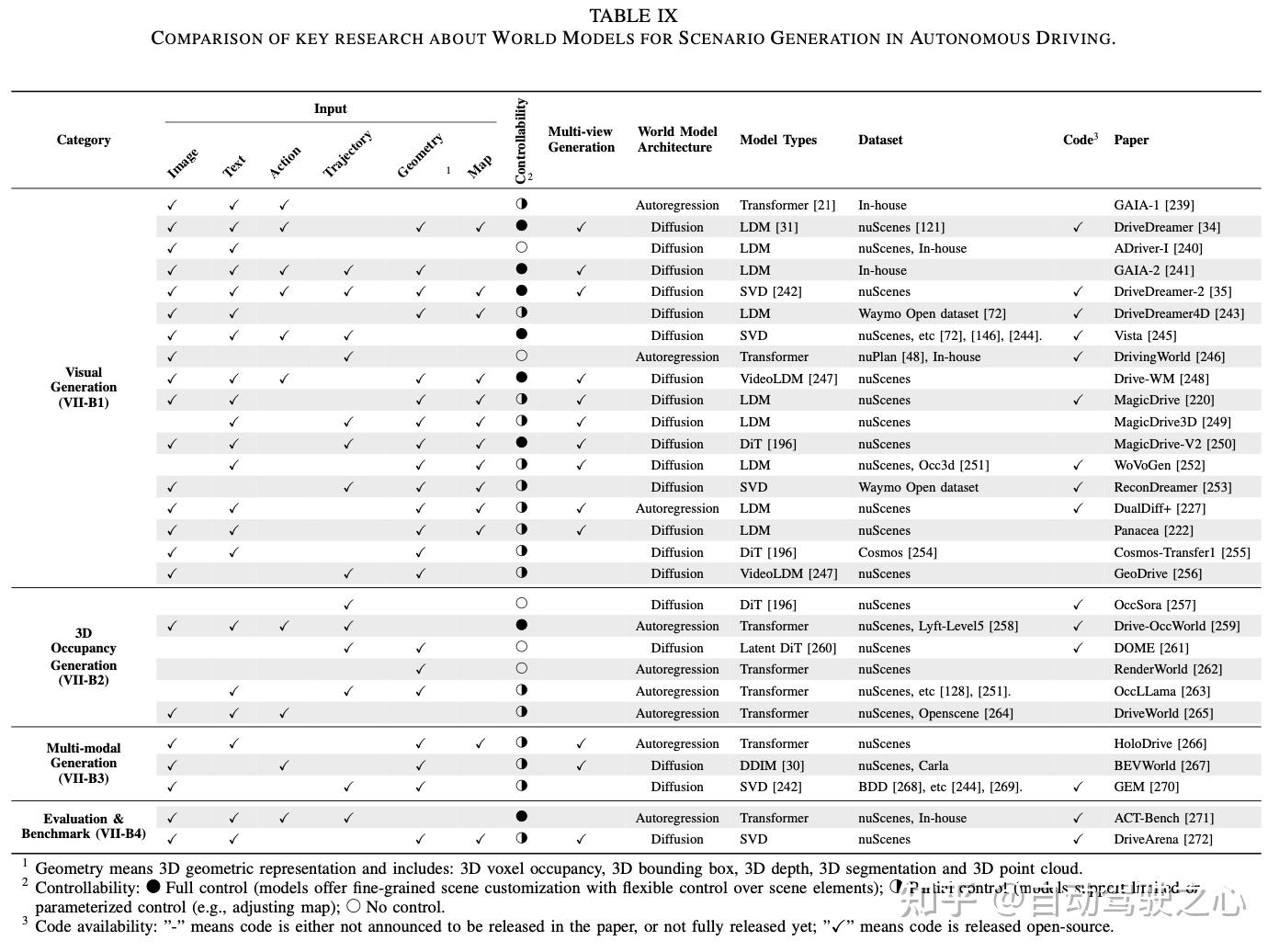
数据集、仿真器和基准汇总
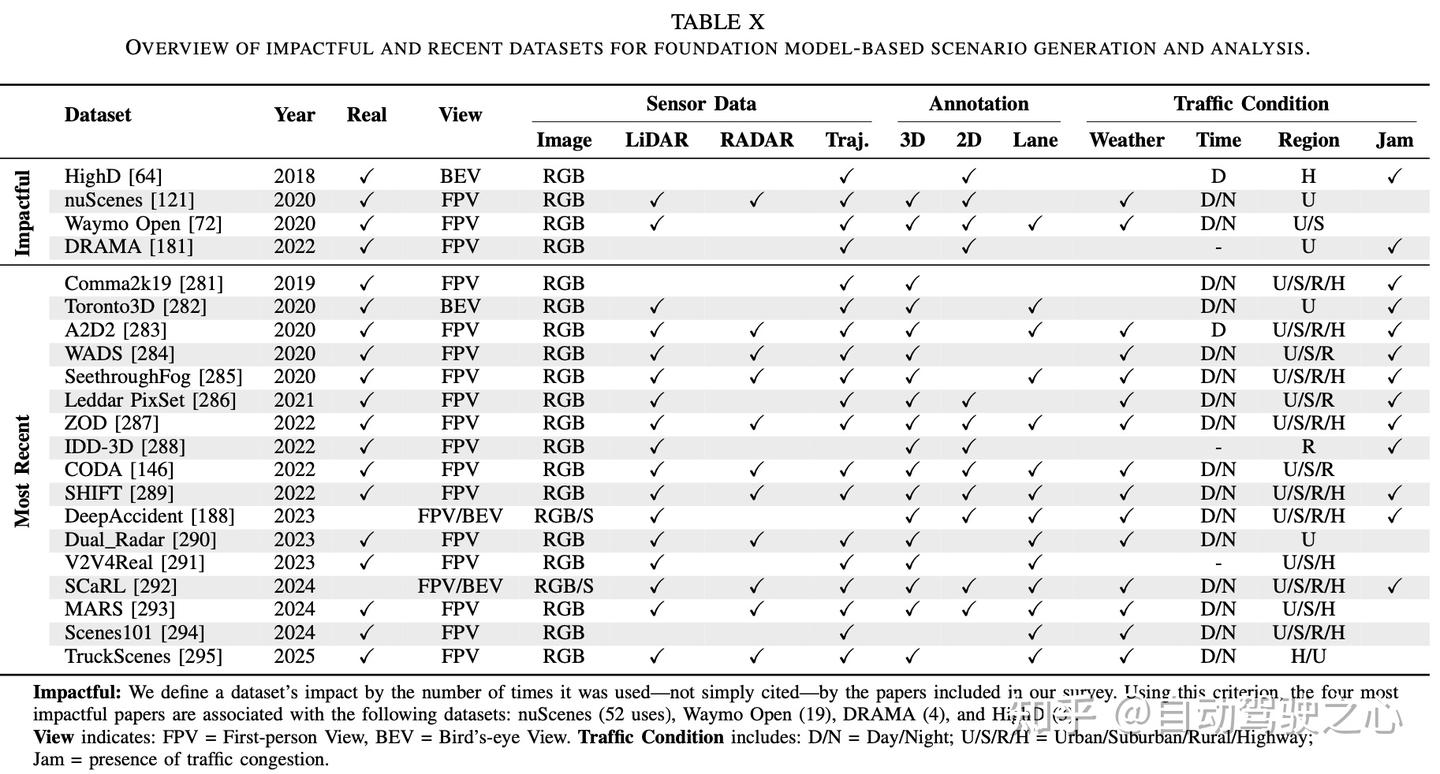
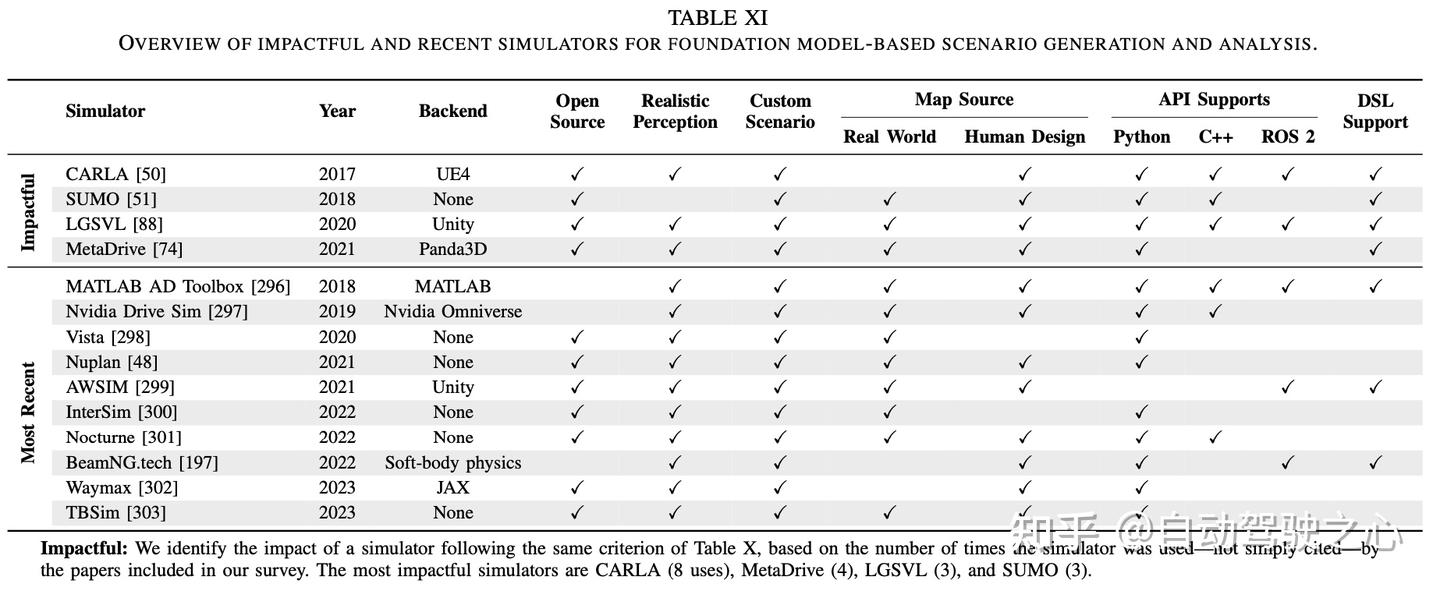
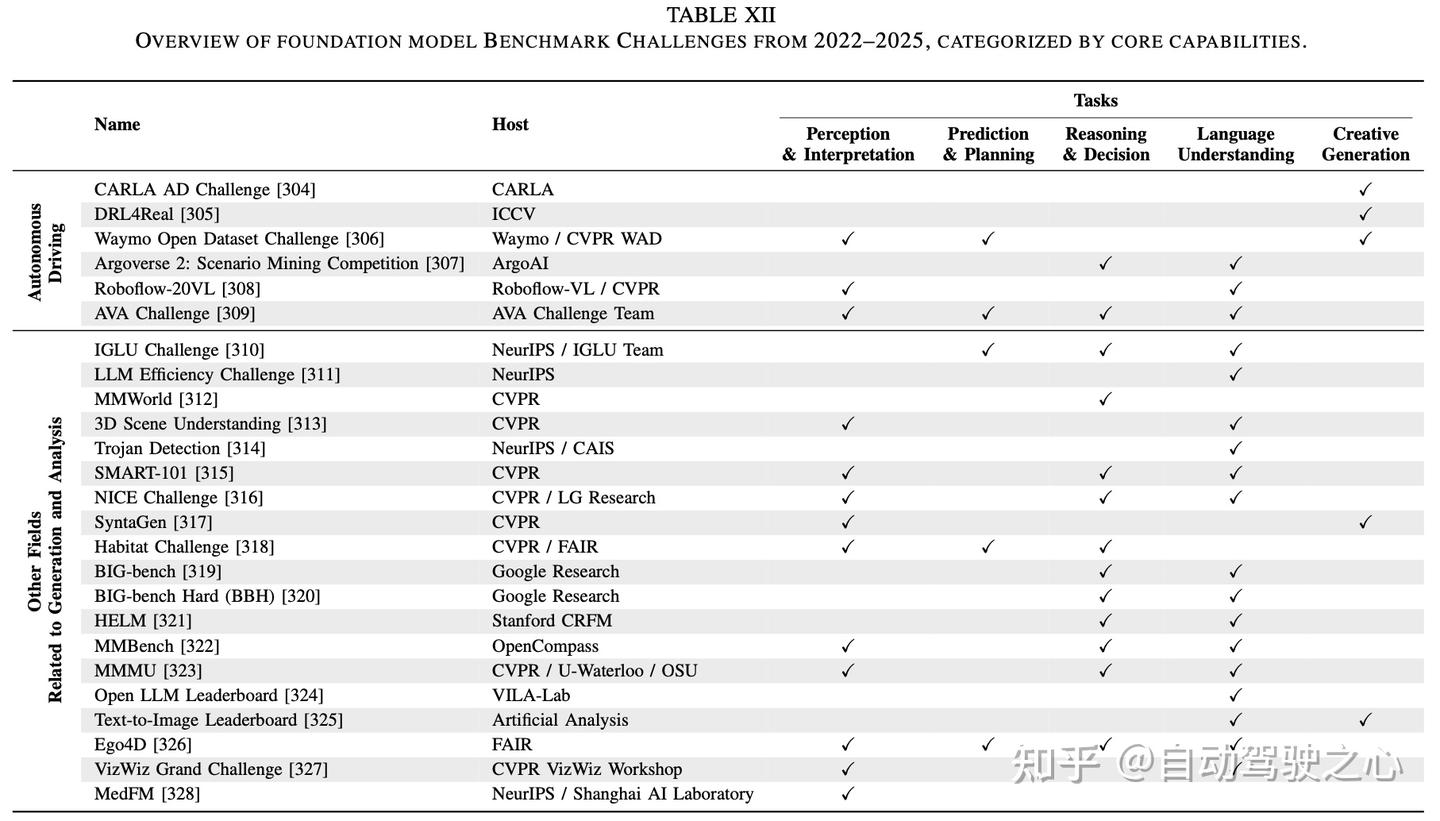
未来方向
应对上述在使用基础模型(FMs)进行场景生成与分析时面临的挑战,催生了多个未来改进的方向和新的研究议程。
研究方向1 – 提升真实性:提升生成场景的真实性和合理性,需要将特定领域的知识融入基础模型中,以增强其对现实世界动态和交互的理解。将基于物理的模型与数据驱动的基础模型相结合的混合方法,有望生成物理上连贯的场景。此外,探索世界模型(WMs)的“梦境”(dreaming)可以弥补传感器模拟的不足:这种数据驱动的“梦境”能够以高保真度捕捉到细粒度的传感器特征。
研究方向2 – 生成罕见事件:捕捉罕见的高风险事件需要专门的方法来系统性地识别和生成此类场景。我们建议创建专注于不频繁但关键情境的针对性数据集,以提高模型在这些情况下的准确性。此外,引入因果推理或反事实推理等推理技术,可能有助于基础模型推导出既合理又不常见的场景。
研究方向3 – 创建多模态数据集:多模态数据的融合仍然是一个重大挑战,需要专门针对场景生成而设计的大规模数据集。这些数据集应结合车辆传感器数据(如激光雷达、雷达、摄像头)、地图数据、交通规则、控制指令、人类反馈和文本注释。我们还建议开发新的、专为多模态融合设计的模型架构和训练方法,以解决当前在可扩展性和集成方面的局限性。
研究方向4 – 开发用于比较的指标和关键绩效指标(KPIs):我们强烈建议开发标准化的评估方法,以客观地比较不同场景和场景生成方法。这需要建立针对真实性、可控性、多样性和安全关键性的新基准和指标,并得到学术界的广泛采纳。在主要学术会议上推广这些新基准的竞赛,将推动技术进步、实现标准化并激发社区驱动的创新。
研究方向5 – 降低计算需求:计算效率和可扩展性是主要的实际约束。解决这一问题需要进一步研究模型蒸馏、剪枝和量化等技术,并将其专门针对场景生成与分析任务进行优化,以在不牺牲性能的前提下最大限度地降低计算需求。
研究方向6 – 纳入合规性考量:另一个研究方向是,如何将基础模型的能力系统性地整合到自动驾驶汽车(AV)开发项目的安全验证工作流中。这包括其在“安全数据飞轮”中的作用,即生成的场景被输入到持续测试、模型再训练、安全评估和性能监控的流程中。我们需要重点关注确保场景的代表性、平衡真实数据与合成数据、与监管安全标准保持一致,并建立能够捕捉整个自动驾驶汽车生命周期中生成的边缘案例安全影响的稳健评估指标。此外,必须开发稳健的数据隐私管理方法,以确保符合监管标准和伦理规范,保护模型所学习数据中可能包含的敏感信息。
结论
本综述全面考察了基础模型(FMs)在自动驾驶应用中的前沿进展,重点强调了其在场景生成与分析两方面的重要贡献。包括大语言模型(LLMs)、视觉语言模型(VLMs)、多模态大语言模型(MLLMs)、扩散模型(DMs)和世界模型(WMs)在内的FMs,已成为提升基于场景测试在真实性、多样性和可扩展性方面的有前景的工具。
FMs的通用性在于其能够通过自监督训练,从大规模、异构的数据集中进行学习。它们跨多种任务泛化知识的能力,推动了基于场景的测试范式的进步,克服了传统基于规则和数据驱动方法的诸多局限。特别是,FMs所展现出的场景生成与分析的双重能力,使其成为构建自动驾驶系统稳健、高效验证框架的关键赋能者。
尽管取得了这些进展,但仍存在显著的挑战。在安全关键场景中实现细粒度的可控性、确保生成场景的强健真实性,以及解决计算效率问题,仍是关键的障碍。此外,尽管所综述的模型已展现出有希望的结果,但仍需进一步研究以增强其输出的可解释性、改进与真实交通状况的对齐,并系统性地处理分布外(out-of-distribution)场景。
最终,随着自动驾驶汽车向更广阔的运行设计域(ODDs)和更高级别的自动化迈进,先进的场景生成与分析方法将变得至关重要。FMs为此演进提供了一个强大的框架,有望彻底改变自动驾驶开发的安全性和效率。该研究的未来轨迹预计将带来进一步的变革性进展,促进更安全、更可靠且更广泛普及的自动驾驶出行。
发表回复