
原文链接:zhuanlan.zhihu.com/p/1931283727692066978
背景与核心目标
自动驾驶在端到端技术上虽然发展迅速,但在长尾场景(如罕见高风险事件)中,准确预测 ego 车辆未来运动的安全性仍面临巨大挑战。现有轨迹评估方法多输出单一奖励分数,无法解释风险类型,难以辅助决策算法采取预防措施。
本文核心目标在于:通过合成高风险运动数据,增强视觉语言模型(VLM)的运动风险预测能力,同时实现风险类型识别与原因解释,为自动驾驶的可靠性和决策优化提供基础。
现有方法的局限
- 规则基方法:依赖外部世界模型和感知模型预测其他车辆未来位置,再基于预定义规则计算分数(figure 1(a))。但这类方法对感知误差高度敏感,且过度依赖结构化空间,难以泛化到真实复杂场景(如无法识别极端天气下的风险)。
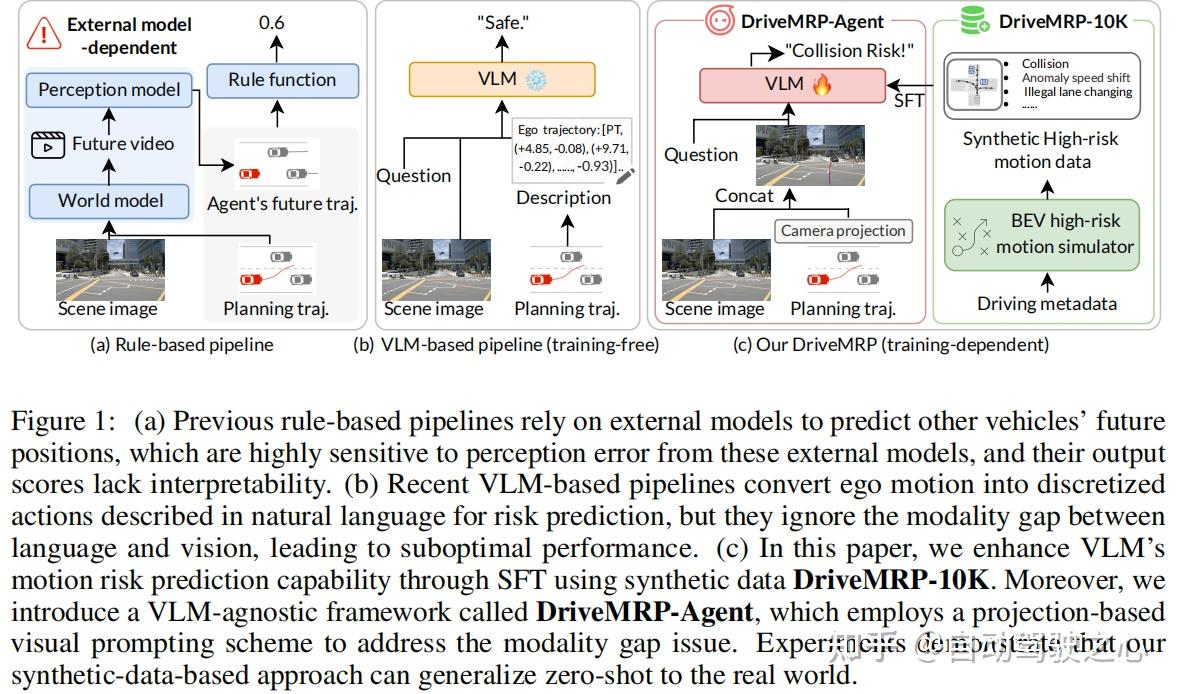
- 世界模型基方法:通过视频预测模型评估候选动作,但继承了规则基方法的局限,且感知模块泛化性差,输出的标量奖励缺乏可解释性。
- VLM 基方法:利用 VLM 对非结构化空间的理解能力,但直接将轨迹坐标转化为文本输入,存在语言与视觉的模态差距(figure 1(b)),导致 VLM 难以理解运动路点与环境的关键空间关系,预测效果欠佳。
核心创新方案
1. DriveMRP-10K:合成高风险运动数据集
基于 nuPlan 数据集
构建,包含 10,000 个高风险场景,通过“人类在环”机制生成视觉问答(VQA)对,流程分为四阶段(figure 2):
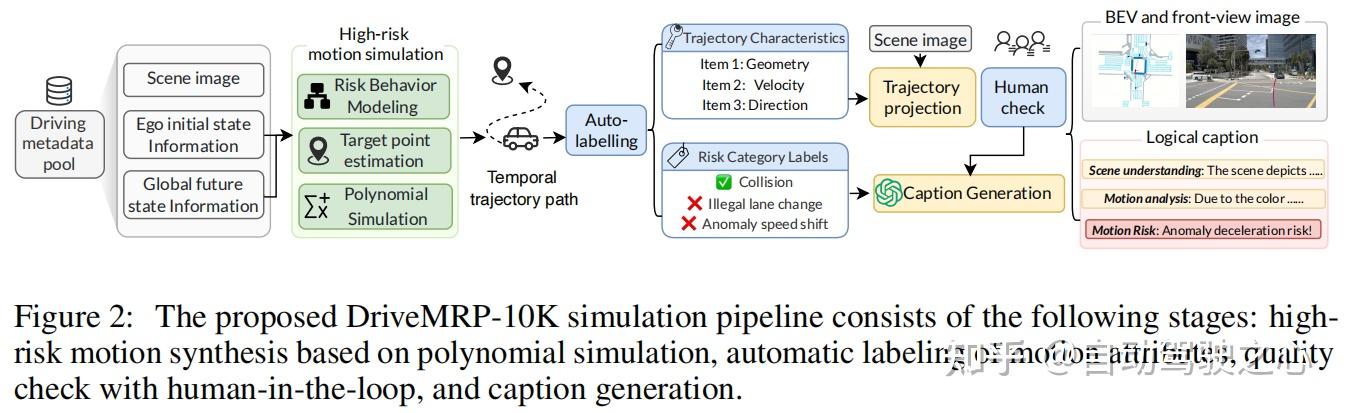
- 高风险轨迹合成:基于多项式模拟,从 ego 车辆行为(急刹、异常加速)、与其他车辆交互(碰撞)、环境约束(违规变道、偏离道路)三个维度设计场景,结合场景初始状态生成平滑轨迹。
- 自动标注:提取轨迹的几何、速度、方向等运动属性,结合驾驶元数据标注风险类别。
- 人工质检:筛选物理上不合理(如违反牛顿定律)或语义不一致的样本,保证数据质量。
- 文本生成:利用 GPT-4o
- 生成包含场景描述、运动分析、风险预测的结构化文本,构建“场景图像-轨迹-文本-风险标签”的多模态数据集。
2. DriveMRP-Agent:VLM 通用框架
以 BEV 布局
、场景图像、运动路点为输入,提升 VLM 的风险推理能力(figure 3):
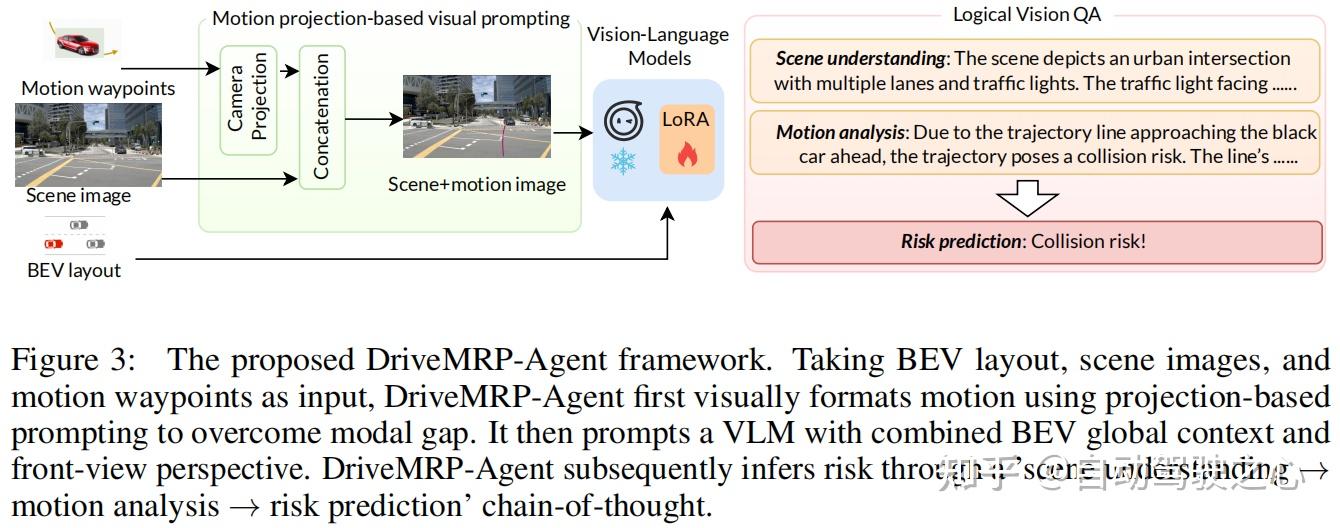
- 视觉提示方案:将运动路点投影为视觉表示,嵌入视觉处理管道,解决坐标与视觉的模态差距。
- 链条推理机制:通过“场景理解→运动分析→风险预测”的步骤(类似人类思维链),先理解驾驶环境(如路口、交通灯),再分析轨迹与其他车辆/环境的交互(如轨迹接近前车可能碰撞),最终输出风险类型(如“Collision Risk!”)。
- 训练策略:采用 LoRA
微调 Qwen2.5VL-7B
- 模型,结合思维链(CoT)提示,让模型生成中间推理步骤,提升复杂场景的推理精度与可解释性。
3. DriveMRP-Metric:评估指标
从两方面评估模型性能:
- 跨模态场景理解能力:用 ROUGE-1-F1
- 、BERTScore 衡量生成文本与参考文本的相似度。
- 高风险运动预测能力:用准确率(Accuracy)、召回率(Recall)、F1 分数评估风险类别的识别效果。
实验验证
1. 性能提升
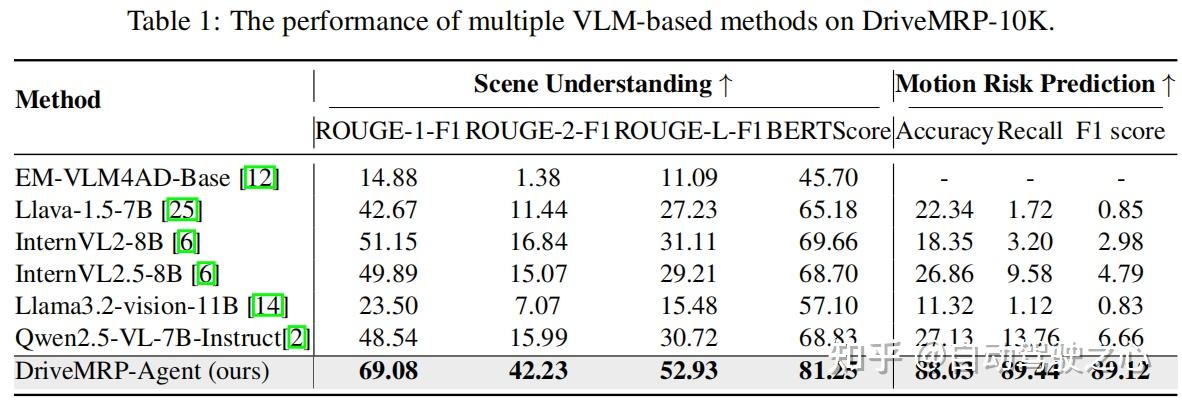
- 在 DriveMRP-10K 上,DriveMRP-Agent 的场景理解指标(如 ROUGE-1-F1 达 69.08)和风险预测准确率(88.03%)远超其他 VLM(table 1),其中事故识别准确率从基线模型的 27.13% 提升至 88.03%。
- 在真实世界数据集(5,000 个高风险片段)上,零样本评估显示其准确率从基线模型的 29.42% 提升至 68.50%(table 2),验证了强泛化性。

2. 数据集有效性
DriveMRP-10K 可显著提升多种通用 VLM 的性能(table 3)。例如,Llava-1.5-7B 微调后,风险预测 F1 分数从 0.85 提升至 29.99,证明其“即插即用”的增强能力。
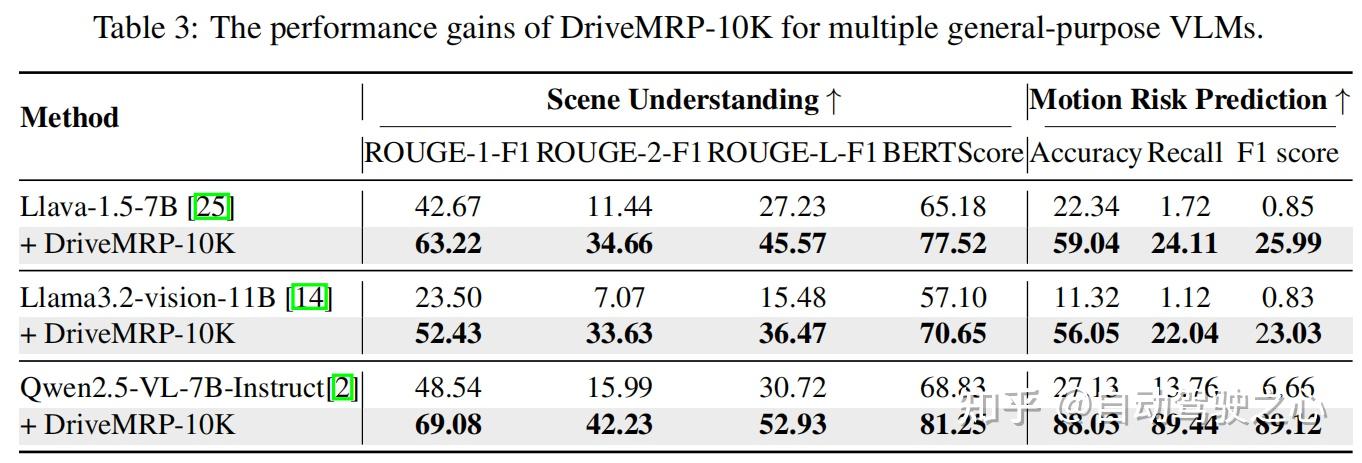
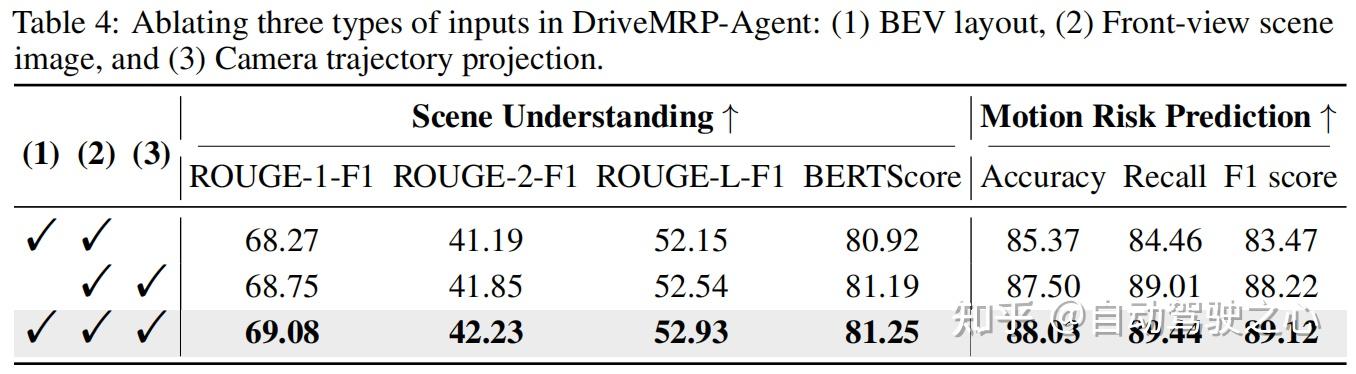
3. 关键组件 ablation 实验
- 加入 BEV 全局上下文后,模型场景理解和风险预测指标均显著提升,说明全局信息对推理的重要性。
- 用轨迹投影替代原始坐标序列,避免了模态差距,性能明显优于直接输入坐标(table 4)。
参考
[1]DriveMRP: Enhancing Vision-Language Models with Synthetic Motion Data for Motion Risk Prediction
发表回复