
原文链接:https://zhuanlan.zhihu.com/p/1913399452405851810
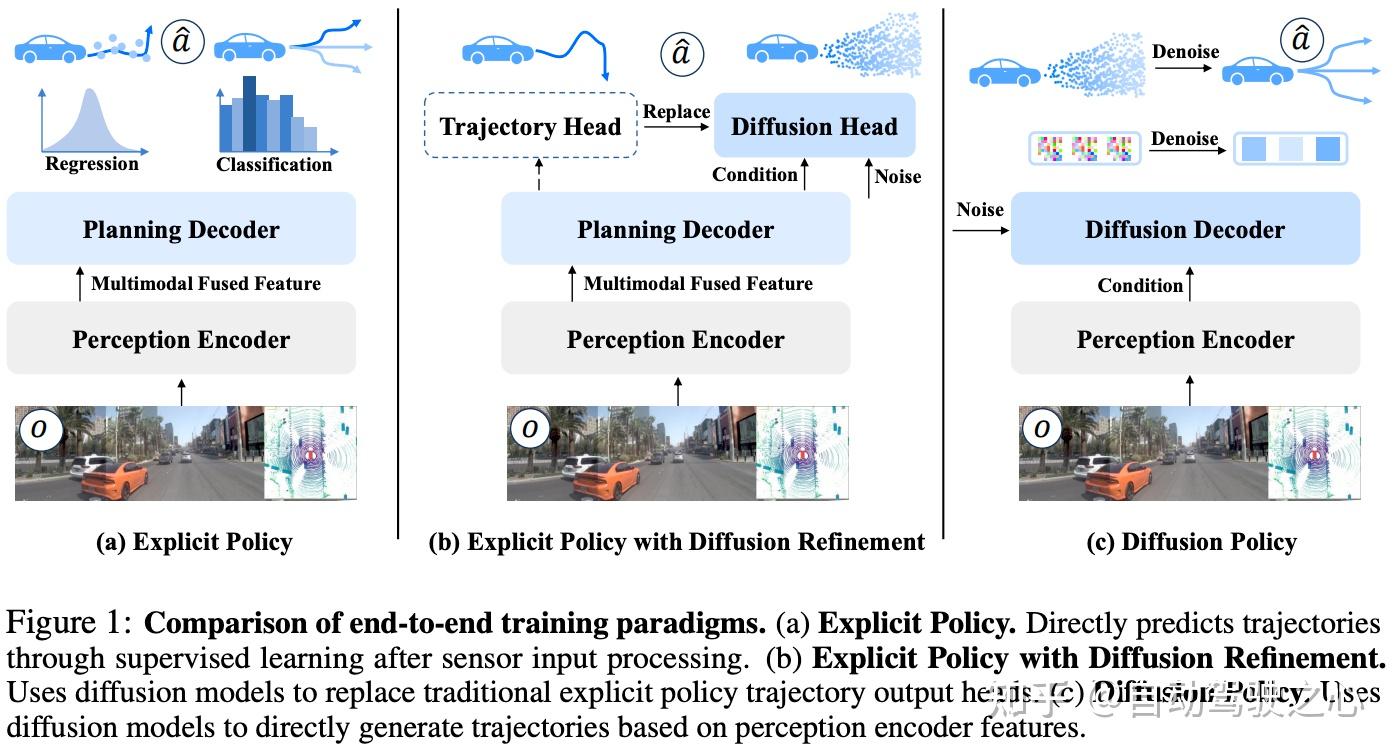
为了避免感知、预测、规控各个模块之间的信息传递损失,端到端可谓是当下自动驾驶领域最主流的技术方向,没有之一。现在主流玩法是用显式监督学习,直接从海量驾驶数据里学怎么把环境信息变成方向盘和油门控制。不过这路子也有两个较大的硬伤:开车本来就有多种可能性(比如遇到障碍可以绕左或绕右),但监督学习只会学个”平均动作”,结果经常整出别扭操作;而且遇到训练数据里没见过的奇葩路况,模型就直接懵了。
设想一下,遇到一个十字路口,老司机可能有五六个合理选择,而现在的AI只会选个相对比较折中方案。为了解决这个问题,最近也有人用离散轨迹集合来应对多模态问题,但这种硬编码的方式就像把活人手脚绑住,把灵活的决策变成固定选项选择题,遇到突发状况就抓瞎。这时候扩散模型(Diffusion Models)就可以大展身手了!这项技术其实在AI作画圈已经封神,靠”先加噪再去噪”的套路能生成千变万化的图片。机器人运动规划领域也验证了它能搞定复杂动作序列。但自动驾驶任务要更为困难——既要实时响应,又要确保轨迹符合交规,还得躲开乱窜的行人和车流。
所以,最近有些团队试水用扩散模型做路径规划和端到端控制,用了DDIM、DPM-Solver这些加速技术,效果确实惊艳。不过现在多数方法只是把扩散模型当”后处理插件”(如图1(b)),在传统规划模块后面加个扩散优化。这相当于戴着镣铐跳舞——既丢了原始感知数据的细节,又被前面的模块限制发挥。
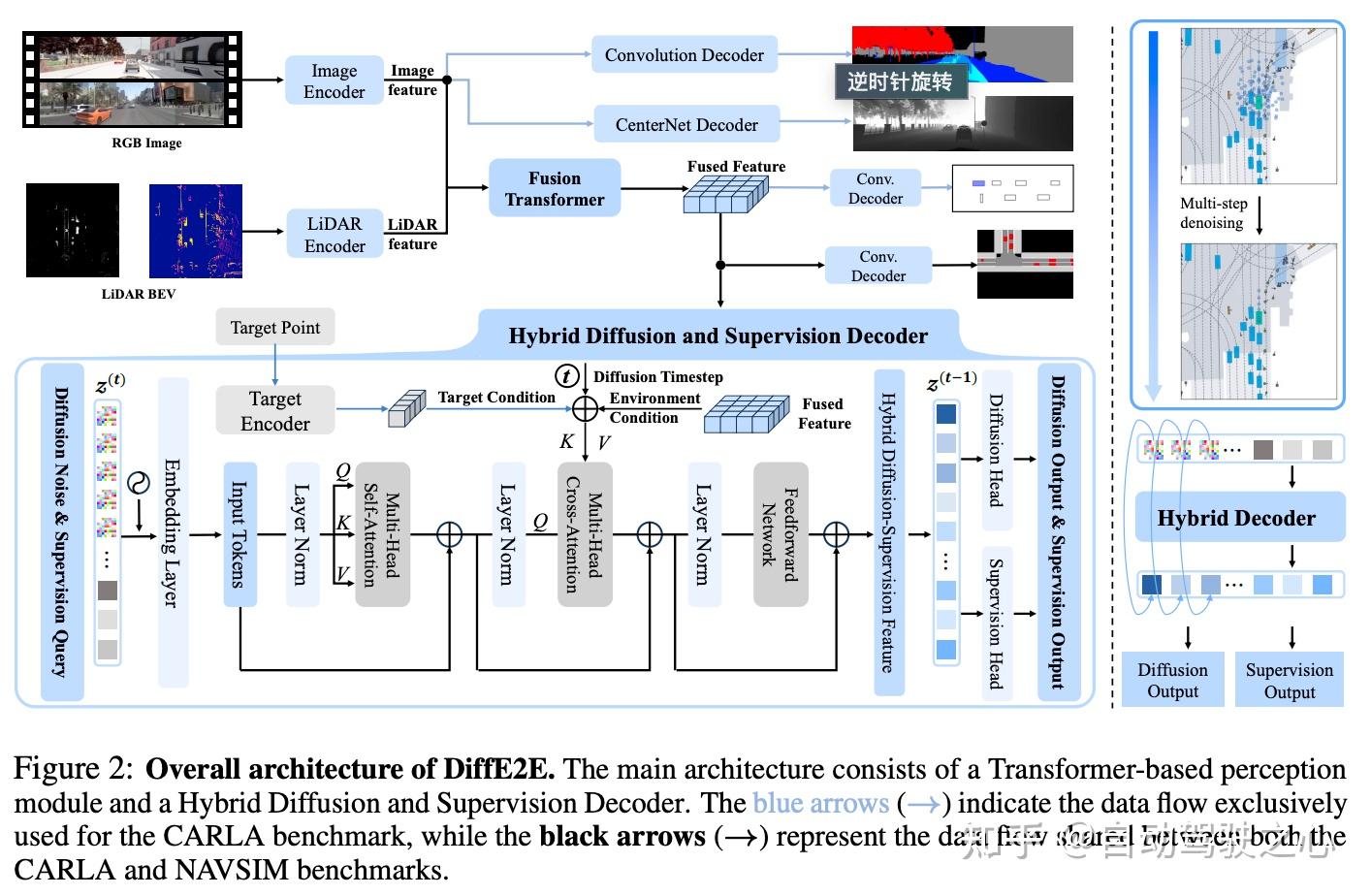
基于这样的背景之下,作者提出了一个新的方案—— DiffE2E 框架(如图2所示)。首先用双向跨注意力让激光雷达和摄像头的数据对齐,把不同传感器的信息融合到一起。然后送进Transformer架构的混合解码器,让扩散模型和传统监督学习组队打配合:扩散模型负责天马行空地想象各种可能轨迹,监督学习则盯紧车速、周围车辆动态这些硬指标。这俩通过跨注意力机制实时交换信息,最后生成既灵活又靠谱的驾驶方案。
相关研究
端到端自动驾驶
端到端自动驾驶近年来在跨模态感知融合与决策规划方面突飞猛进。UniAD 构建了全栈Transformer架构,将感知-预测-规划任务统一编排;VAD 提出矢量化场景表征提升规划效率;VADv2 通过轨迹词库建模动作空间分布;SparseDrive 提出稀疏轨迹表征实现无BEV的高效驾驶;Hydra-MDP系列设计多教师蒸馏框架,将规则系统与人类驾驶知识相融合。Transfuser 通过 Transformer 融合相机与激光雷达特征应对路口决策;TCP 联合训练轨迹与控制预测;InterFuser 引入安全思维图谱实现多视角跨模态融合;TF++ 则通过解码器增强与解耦速度预测提升性能。不过这些显式监督方法常将多模态驾驶行为压缩为单一确定性输出,在多选择场景中容易产生”平均化”决策。虽然在特定场景表现亮眼,但面对超出训练数据的复杂路况时泛化能力明显受限。
扩散模型在交通与自动驾驶中的应用
扩散模型正以强大的多模态生成能力应用于自动驾驶。Diffusion-ES 创新地将进化策略与扩散模型结合,在nuPlan基准测试中零样本性能碾压传统方法;VBD 用博弈论指导对抗场景生成,提升仿真真实性;MotionDiffuser 提出置换不变架构实现约束条件下的多智能体轨迹采样,保证交互一致性;Diffusion Planner 利用 DPM-Solver 和分类器引导,实现闭环规划中快速、安全、个性化的轨迹生成。不过这些方法多基于完美感知假设,忽视了实际应用中感知不确定性带来的状态估计误差。
在端到端自动驾驶领域,扩散模型的应用已崭露头角:DiffusionDrive 首次将扩散模型引入端到端驾驶,采用锚点策略平衡实时性与多样性;HE-Drive 通过条件 DDPM 和视觉语言模型打分,生成拟人化的时空一致轨迹;GoalFlow 用目标驱动的流匹配解决轨迹发散问题,实现高效一步生成。这些工作体现出了扩散模型在该领域的巨大潜力,但现有方法在感知-规划协同优化、实时性保障等方面仍有提升空间。
预备知识

方法论

多模态融合感知模块

混合扩散和监督模块
在多模态融合感知模块完成不同传感器数据的整合后,本文提出的DiffE2E框架采用了一种创新的架构。通过引入基于Transformer的混合扩散-监督解码器,并采用协作训练机制,无缝整合了扩散策略和监督策略的优势。



扩散和监督学习写作训练策略
基于上述混合扩散和监督解码器结构,论文中提出了基于扩散生成和监督学习的协作训练策略。该策略的核心在于结合扩散模型的生成能力和显式监督的精确性,形成互补优势。

实验及结论
CARLA
中的实验结果
论文中主要使用CARLA模拟器的闭环基准测试。
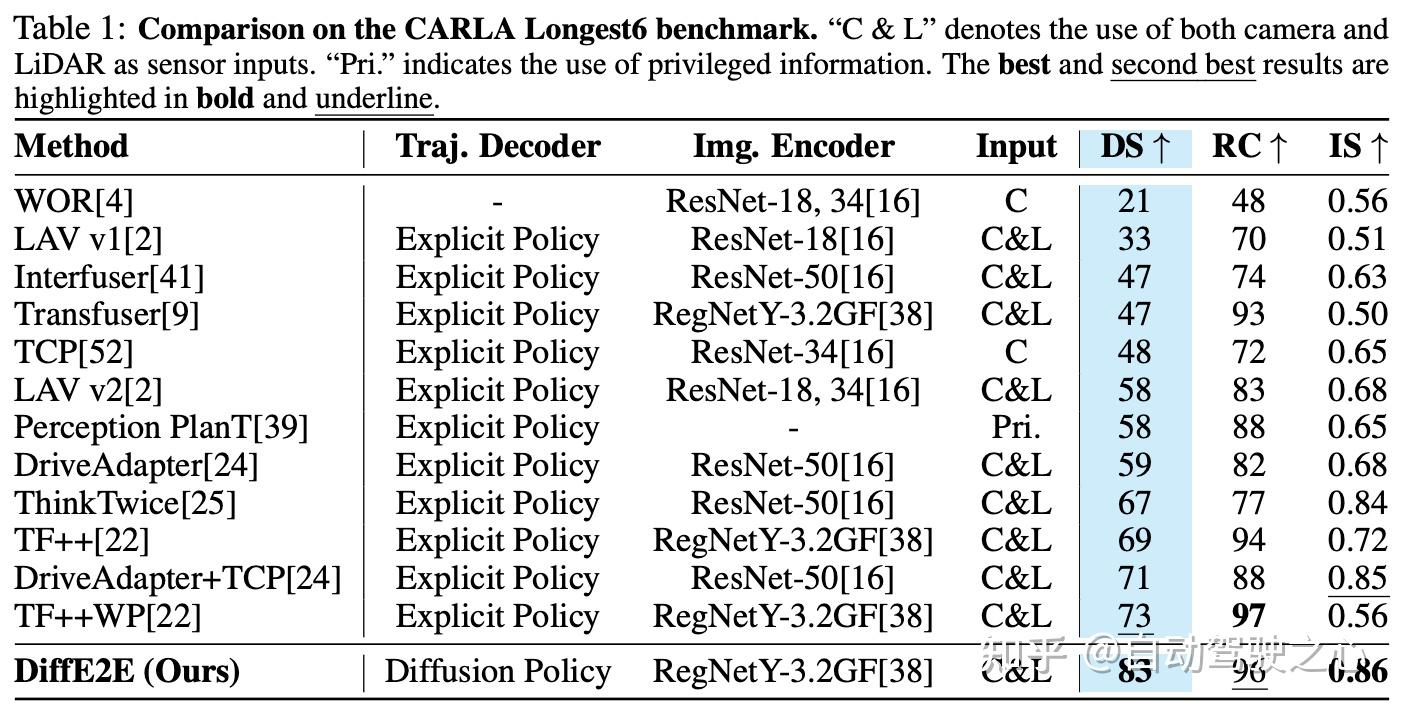
主要结论: 如表1所示,DiffE2E在CARLA Longest6基准测试中表现出色。在三个关键评估指标中,DiffE2E均排名首位:DS为83(比TF++WP高出13.7%),IS为0.86(比DriveAdapter+TCP高出2.3%),RC为96,接近最优。总体而言,DiffE2E提供了稳健、高效的端到端驾驶性能。
定性结果分析: 图3展示了在一个典型的右转场景中的比较。最初,TF++和DiffE2E都计划通过先向右合并来规划路径。当出现一辆车时,TF++坚持其预设路径并发生碰撞,而DiffE2E通过暂时向前行驶,然后在车辆通过后安全合并,从而适应环境。这表明DiffE2E在动态交通中具有优越的多模态生成能力和实时适应性,有效避免了碰撞。

NAVSIM 中的实验结果
论文中基于NAVSIM的navtrain数据集构建了模型训练框架。与CARLA设置不同,作者在NAVSIM中采用VovNetV2-99作为特征提取骨干网络。使用预测驾驶员模型分数(PDMS)作为综合指标,通过加权整合关键驾驶维度:无责任碰撞(NC)、可行驶区域合规性(DAC)、时间到碰撞(TTC)、舒适性(C)和自身进度(EP)。
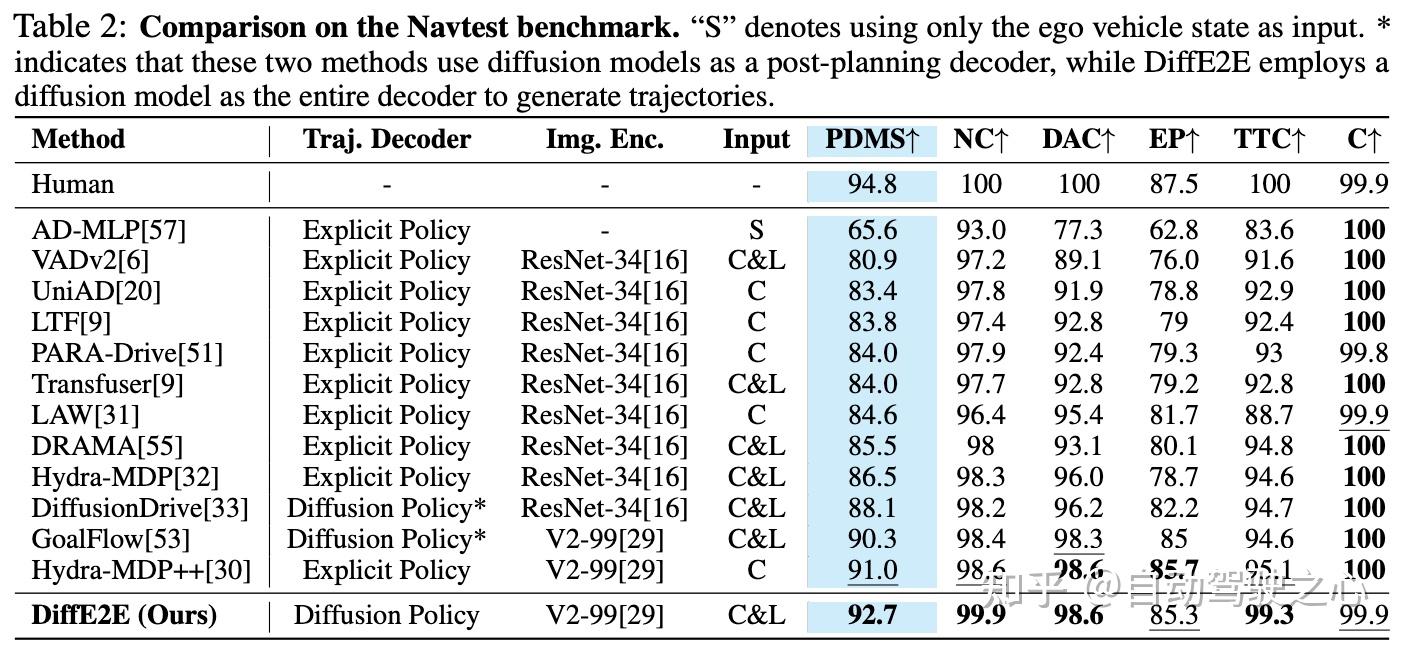
主要结果分析: 如表2所示,DiffE2E在NAVSIM基准测试中取得了优异的整体性能,PDMS得分为92.7——超过了Hydra-MDP++(91.0)、GoalFlow(90.3)和DiffusionDrive(88.1)。这突显了作者基于扩散的端到端方法在多维驾驶评估中的优势。在安全性和合规性方面,DiffE2E表现出色:无责任碰撞率为99.9(与Hydra-MDP++的98.6和GoalFlow的98.4相比),与Hydra-MDP++共享最高的可行驶区域合规性得分98.6。在时间到碰撞方面,DiffE2E以99.3领先,比Hydra-MDP++高出4.2分。在效率和舒适性方面,DiffE2E在自身进度上得分85.3(仅次于Hydra-MDP++的85.7),在驾驶舒适性上得分为99.9——接近SOTA,表明其轨迹平滑且类似人类驾驶。
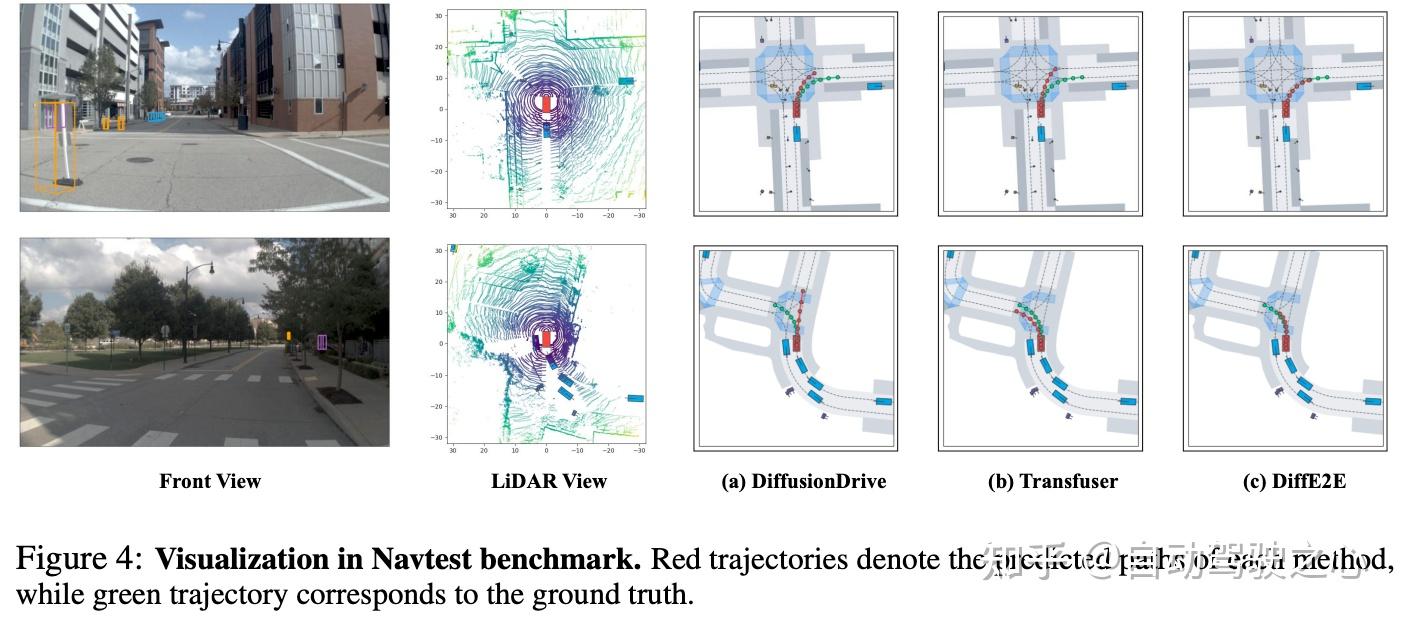
定性结果分析: 为了验证DiffE2E的泛化能力和优越性,作者选择了两个具有代表性的复杂驾驶场景进行比较分析(图4)。绿色轨迹表示人类参考轨迹,红色轨迹表示计划轨迹。在右转交叉路口,基线方法经常偏离或越过边界,而DiffE2E能够准确地沿着车道边缘进行平滑转弯。在小交叉路口左转时,DiffusionDrive错误地解释了导航意图并计划了一条直线轨迹,Transfuser错误地选择了右车道,而只有DiffE2E准确地执行了左转指令,其轨迹几乎完全与参考轨迹匹配。这证明了DiffE2E在轨迹规划中的准确性和安全性。
消融实验
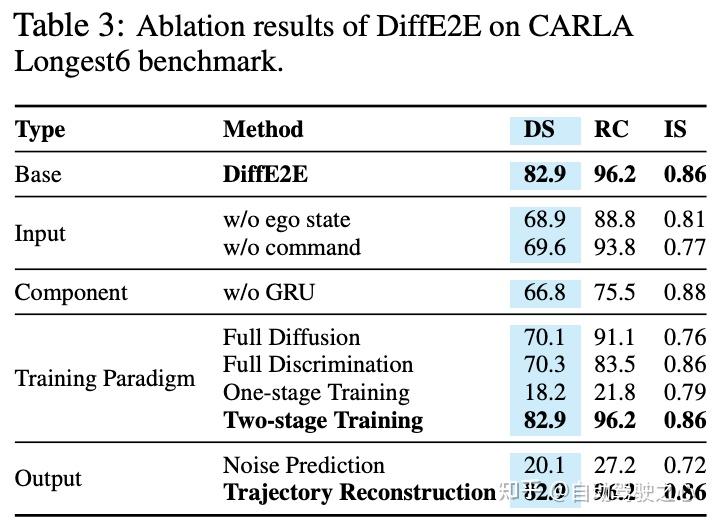
为了评估DiffE2E框架中每个组件的贡献,作者进行了一系列消融实验(见表3)。对于模型输入,作者分别消除了自我状态和导航指令。在这两种情况下,驾驶分数都有所下降,证实了自我状态对于准确规划的重要性以及导航输入对于意图理解的重要性。在架构方面,移除GRU模块导致分数显著下降,显示了其在复杂场景中提高预测的作用。在训练方面,作者比较了混合扩散、全扩散和显式策略范式,以及一阶段与两阶段策略。全扩散和显式策略训练都降低了性能,验证了混合方法的有效性。一阶段训练仅获得了18.2的驾驶分数——比两阶段低78%,导致车道保持能力差。这表明联合训练感知和规划存在挑战,而两阶段训练使每个模块都能得到有效优化。
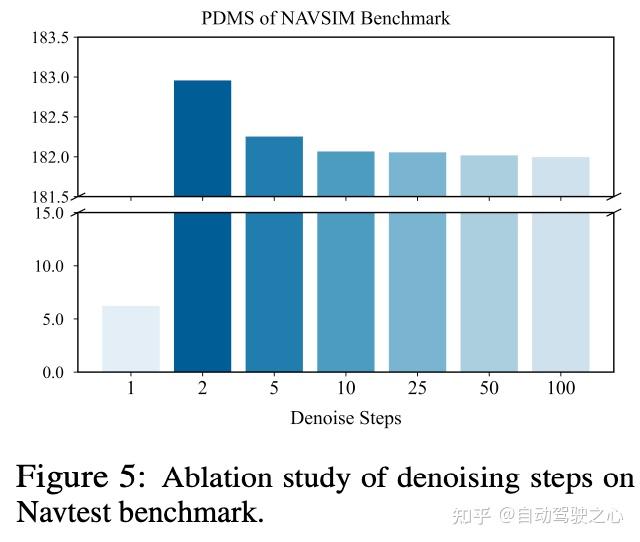
此外,作者还对扩散模型中的去噪步数进行了消融研究(图5)。由于CARLA的随机性以及去噪步数的较小影响,作者使用了更稳定的NAVSIM Navtest基准。为了清晰起见,作者将92.705设置为零基线,并应用了1e4的缩放因子。结果显示,1步时PDMS最低(去噪不完全),2步时达到峰值,然后逐渐下降,表明此时已完全去噪。因此,在DiffE2E中使用2个去噪步来平衡性能和实时效率,这对于自动驾驶任务还是至关重要的。
结论
论文中提出了一个创新的端到端自动驾驶框架DiffE2E,该框架整合了基于Transformer的混合扩散-监督解码器,并引入了协作训练机制,有效地结合了扩散策略和监督策略的优势。作者设计了一种结构化的潜在空间建模方法:利用扩散模型对未来轨迹分布进行建模,捕捉行为的多样性和不确定性;同时引入显式监督对诸如速度和周围车辆动态等关键控制变量进行细粒度建模,增强对物理约束和环境变化的感知能力,从而提高预测的可控性和精确性。在CARLA闭环测试和NAVSIM非反应式模拟中,DiffE2E均取得了领先的性能,平衡了交通效率和安全性,同时展现了出色的泛化能力。
发表回复