
原文链接:https://zhuanlan.zhihu.com/p/1908667895145279797
自动驾驶系统在对抗性场景(Adversarial Scenarios)中的可靠性是安全落地的核心挑战。当前测试数据多依赖真实采集的常规场景,缺乏刻意构造的高风险驾驶场景。为此,清华大学联合吉利研究院提出全新框架Challenger,实现多视角、高保真对抗驾驶视频的自动化生成,在其生成的高挑战性数据集上验证显示,主流端到端模型碰撞率最高提升26.1倍!
论文链接:
代码仓库(GitHub):Pixtella/Challenger:https://github.com/Pixtella/Challenger
项目主页:Challenger:https://pixtella.github.io/Challenger/
数据集(Hugging Face):Pixtella/Adv-nuSc · Datasets at Hugging Face:https://huggingface.co/datasets/Pixtella/Adv-nuSc
生成对抗性场景示例:
交替前进

左侧超车

正面会车、掉头、侧方超车

从左侧疾驰而过

拥堵场景变道

从左侧加塞

研究背景
在自动驾驶领域,评估系统的鲁棒性和安全性是至关重要的。然而,现有的大规模自动驾驶数据集,如nuScenes、OpenScene等,主要包含自然交通流,缺乏刻意设计的具有挑战性的交互场景。这些数据集难以系统地评估自动驾驶系统在罕见但高风险事件下的表现。为了解决这一问题,先前工作已提出多种对抗性场景生成方法,但这些方法大多基于抽象的轨迹或鸟瞰图(BEV)表示,无法提供逼真的传感器数据来真正测试端到端自动驾驶系统
(end-to-end autonomous driving system)的极限。另有部分方法(如NeuroNCAP等)需要大量人力手动设计对抗性场景,或需要大量计算资源,难以实现复杂多样对抗性测试场景的批量生成。因此,如何自动、低开销地生成多样化、物理合理且逼真的对抗性驾驶视频,成为自动驾驶评估领域的一个重要空白。
研究团队提出的Challenger框架能够生成物理合理且逼真的对抗性驾驶视频。该框架通过结合基于扩散模型的轨迹生成器、物理感知规划模拟器
和多视图神经渲染器,实现了基于真实驾驶场景自主生成对抗性驾驶场景。该项工作的核心贡献包括:
- 提出对抗性驾驶视频生成任务:为提升自动驾驶系统的安全性和可靠性评估效率,作者首次提出对抗性驾驶视频生成任务,并开发了统一框架Challenger。该框架通过多轮物理感知轨迹优化和渲染兼容的对抗性评分,实现了低成本的对抗性视频生成。
- 在nuScenes数据集上验证有效性:在nuScenes数据集上,Challenger成功生成了涵盖加塞、尾随、阻挡等多种对抗性驾驶行为的多样化且逼真的视频。这些视频覆盖了包括十字路口、环形交叉路口以及停车场等在内的多种动态交通场景。
- 显著降低先进自动驾驶模型性能并揭示可转移的失败模式:Challenger生成的视频使当前最先进的自动驾驶模型(如UniAD、VAD、SparseDrive和DiffusionDrive)的性能显著下降,并揭示了这些模型之间可转移的失败模式,为研究人员提供了深入了解模型脆弱性的机会。
方法
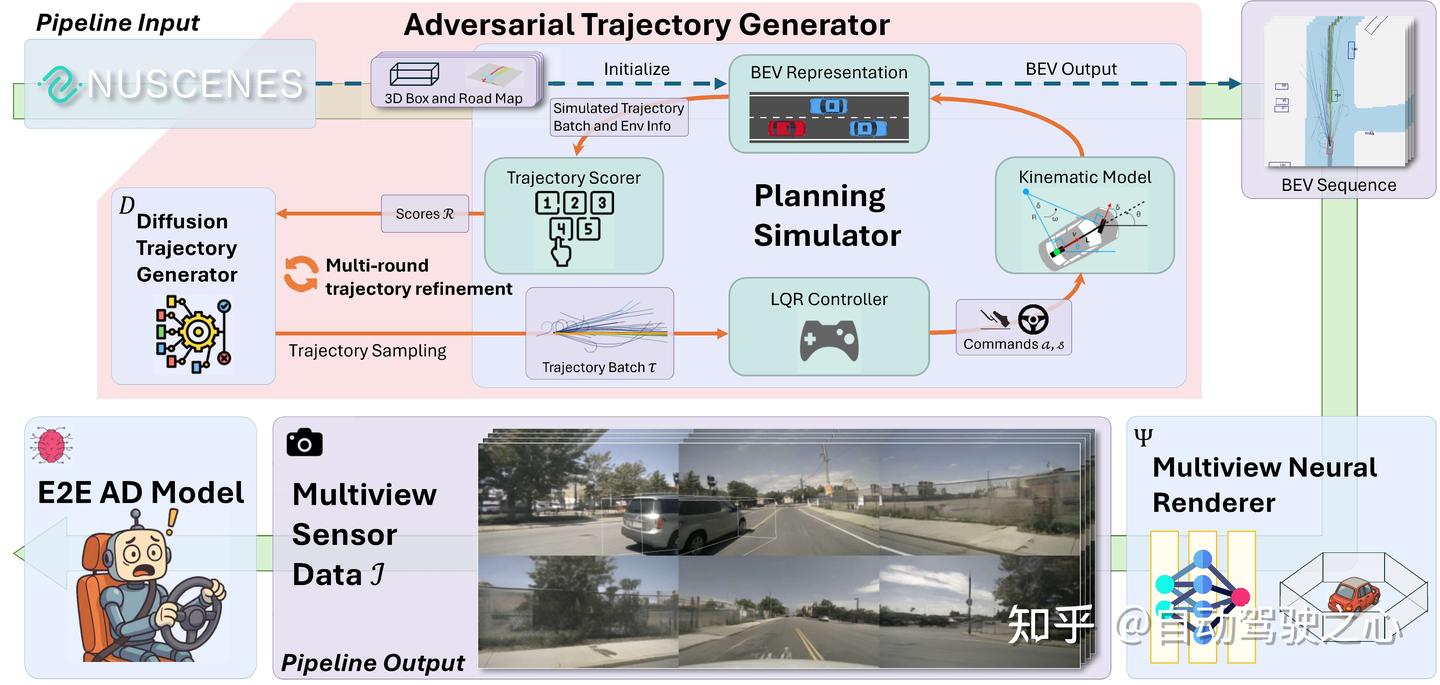
Challenger 方法流程简述
Challenger 首先读取真实数据集(如 nuScenes)中交通参与者的 3D边界框(bounding boxes) 与 鸟瞰图地图(BEV Map) 来初始化驾驶场景。在此基础上,系统随机选取一辆背景车辆作为对抗智能体(adversarial agent),其余交通参与者保持不变。
随后,Challenger 会在一系列关键帧(keyframes)上对该对抗车辆的行为轨迹进行规划,并在关键帧之间连续执行这些轨迹。在每一个关键帧处,Challenger 会执行一个多轮轨迹优化(multi-round refinement)的过程,以高效搜索对抗性轨迹空间,具体步骤如下:
- 第一轮,从一个基于扩散模型的轨迹生成器(diffusion-based trajectory generator)中采样一批轨迹候选;
- 候选轨迹输入物理感知的规划模拟器(physics-aware planning simulator) ,利用LQR 控制器 与 车辆运动学模型模拟对抗车辆的行驶轨迹;
- 轨迹评分器对模拟轨迹进行评估,选出表现最优的一批轨迹;
- 这批轨迹被重复采样、加入扰动噪声、再通过扩散模型去噪重建,作为下一轮的输入;
- 以上步骤重复进行若干轮,以逐步收敛至最优对抗轨迹。
最终,挑选出最优轨迹作为当前关键帧的对抗计划,并将其作用到驾驶场景中。该过程将在所有关键帧上重复进行,生成完整的扰动行为序列。
在轨迹规划完成后,Challenger 利用一个多视角神经渲染器
(multiview neural renderer),将这些对抗性场景转换为逼真的多摄像头视频输出,将用于后续评测端到端自动驾驶模型。
扩散轨迹生成器
Challenger首先训练一个无条件扩散模型(unconditional diffusion model),学习自然驾驶轨迹的分布
。每条轨迹表示为自车坐标系下的二维路径序列。训练数据来自 nuPlan 数据集,包含大量真实轨迹样本。
在生成过程中,模型从高斯噪声出发,通过逐步去噪,生成符合人类驾驶风格的轨迹。它还可用于轨迹微调,即对已有轨迹加噪后再去噪,从而实现多样化输出。
物理感知的规划模拟器
为了确保生成轨迹的物理可行性,Challenger引入了一个物理感知仿真器:
- 使用LQR 控制器生成车辆控制指令(转向与加速度)。
- 用自行车运动学模型(Kinematic Bicycle Model)模拟车辆运动。
该模块确保轨迹能被现实车辆动态执行,且适配当前背景车辆的物理特性(如轴距、轮距等)。
轨迹评分器
为了高效选择具有挑战性的轨迹,Challenger设计了一个复合评分函数,评价每条轨迹的可行性与对自车的挑战程度:
- 道路约束性:偏离可驾驶区域的轨迹将被惩罚;
- 碰撞率:导致对抗车辆与其他交通参与者碰撞的轨迹将被惩罚;
- 对抗性:与自车发生危险接近行为(但未发生碰撞)的轨迹将获得奖励。
该评分机制无需渲染图像即可快速评估轨迹,有利于高效搜索。
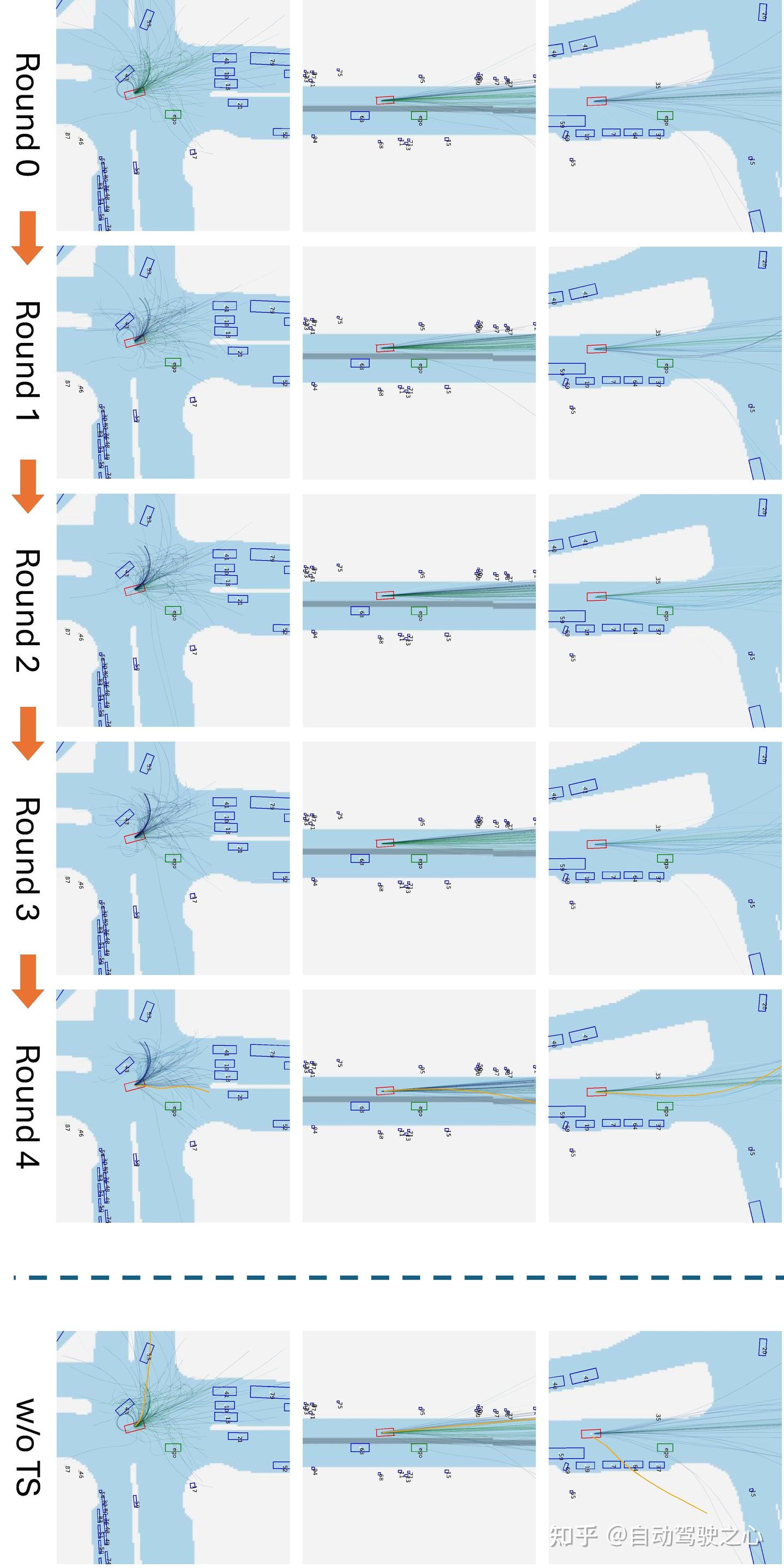
多轮轨迹优化
Challenger采用多轮迭代采样优化策略提升轨迹质量:
- 第0轮:从扩散模型采样一簇初始轨迹;
- 每轮:
- 用仿真器模拟轨迹;
- 使用轨迹评分器对轨迹打分;
- 重采样(Resample)得分高的轨迹;
- 加噪 + 扩散模型去噪,生成新的轨迹簇;
- 进入下一轮。
该过程逐步收敛到既物理可行又具对抗性的轨迹。
多视角神经渲染器
最终,Challenger使用MagicDriveDiT作为神经渲染器,将生成的BEV轨迹与3D包围盒转化为六视角真实感视频。其具备:
- 高分辨率;
- 跨时域一致性;
- 能渲染复杂的城市场景与对抗行为。
此渲染器保证最终视频的视觉质量,适用于端到端自动驾驶模型的测试输入。
扩展至多对抗车辆

虽然当前版本的Challenger尚未引入对抗智能体之间的高层次交互关系,但其提供了一种结构清晰、可复用的扩展流程以支持包含多辆对抗车辆的场景生成。具体而言:
- 初始对抗生成:首先,使用 Challenger 生成一个包含单个对抗车辆的驾驶场景;
- 重新注入场景:在神经渲染之前,将该场景重新输入 Challenger,并选定另一个背景车辆作为新的对抗智能体;
- 重复迭代:重复上述过程,当前轮生成的对抗车辆会将先前的对抗车辆视为环境中的一部分,从而逐步引入多个对抗参与者;
- 最终渲染:在所有对抗智能体行为均规划完成后,统一执行多视角渲染,生成最终的视频输出。
实验
实验设置
数据集
本研究基于nuScenes数据集构建实验环境。nuScenes是一个大规模的多模态感知数据集,包含1000 个场景,每个场景时长为 20 秒,标注频率为2Hz,含有车辆、行人等物体的3D边界框(3D bounding boxes)标注,是当前端到端自动驾驶研究中的常用数据集。
具体地:
- 研究团队使用nuScenes验证集,共包含 150 个场景,6019 个样本,作为 Challenger 的实验基础;
- 为评估神经渲染器带来的视觉效果差异,作者将原始验证集用Challenger框架中的多视角神经渲染器重新渲染,称为 nuScenes-val-R;
- 另外,作者使用 Challenger 生成了新的对抗性数据集 Adv-nuSc,包含156 个场景,6115 个样本,该数据集包含带有挑战行为的背景车辆,用于测试自动驾驶系统的鲁棒性。

端到端自动驾驶模型
研究团队评估了四个当前主流的基于视觉的端到端自动驾驶模型,包括UniAD,VAD,SparseDrive,DiffusionDrive。
这些模型均基于多视角相机图像(multi-view camera images) 输入,预测未来3 秒内的自车轨迹(ego trajectory)。所有模型采用官方公开的预训练权重进行评估。
定量实验结果
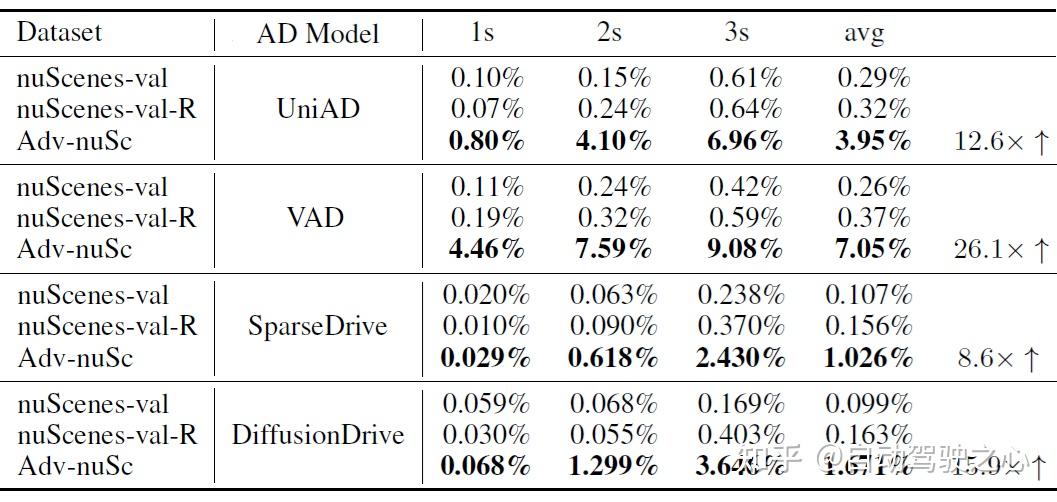
评估指标采用三秒碰撞率(collision rate),即预测轨迹在未来3 秒与任何其他物体发生碰撞的样本比例。
实验发现:
- 在nuScenes原始数据 和nuScenes-val-R上,各模型性能基本持平,碰撞率变化较小,说明虽然神经渲染带来了一定的分布漂移,但其影响非常有限。
- 在对抗性数据集 Adv-nuSc 上,所有模型的碰撞率显著上升,暴露出在面临挑战性行为时的脆弱性与泛化能力不足。
该实验结果清晰表明:Challenger 能够有效构造暴露自动驾驶系统失败模式的场景。
攻击可转移性实验
为进一步验证 Challenger 所生成的对抗场景是否对未知的自动驾驶系统 也能产生破坏效果,本节引入了攻击可迁移性(transferability)的评估实验。
实验设计:
- 引入替代模型(Surrogate Model):在Challenger系统中选定一个端到端自动驾驶模型作为替代模,随后生成一批对抗性场景并测试替代模型的表现
- 样本筛选:仅保留那些替代模型在至少一个样本中无法安全通行(发生碰撞)的场景;这一策略旨在聚焦更具挑战性的对抗场景,从而提升其对其他模型造成失败的可能性。
- 跨模型评估:对保留下来的场景,用其余三个模型分别评估;如果这些模型在至少一个样本中也发生碰撞,则说明该攻击对其具有迁移性。

多组对比结果显示:大量对抗场景不仅能诱导替代模型失败,也会导致其它未见模型发生碰撞;攻击可在模型间迁移,在黑盒(black-box)条件下依然有效;这表明目前多种主流端到端自动驾驶系统可能存在共同脆弱性。
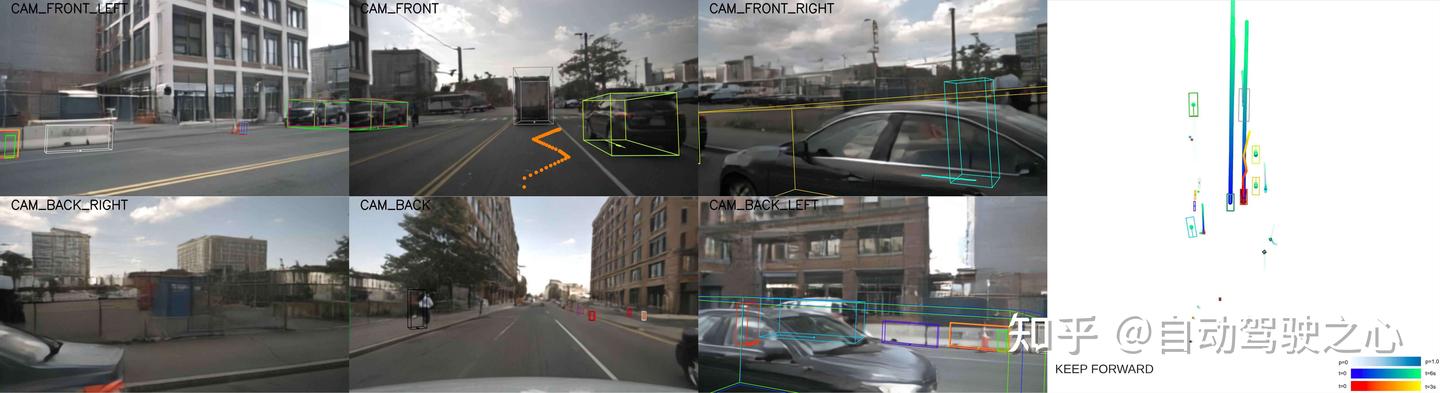
自动驾驶模型失败模式
研究团队通过对主流端到端自动驾驶模型在Adv-nuSc数据集上的部分失败样本的人工审查,识别出了两种典型的失效类型:
预测失败(Misforecasting):即使周围环境已明确展现潜在风险,自动驾驶系统未能正确预测其他交通参与者的行为轨迹,导致碰撞。这一问题主要归因于Challenger所生成的对抗性场景与原始训练数据之间存在协变量偏移(covariate shift)。
规划失败(Misplanning):指即便模型对周围环境的预测较为准确,但最终生成的驾驶决策存在严重风险,反映出规划模块对于复杂交互场景缺乏鲁棒性。



结论
该项工作提出了一种名为Challenger的创新框架,它能够以低成本生成多样化、复杂且高度逼真的驾驶场景。该框架结合了基于扩散的轨迹生成器、具备物理意识的规划模拟器以及多视角神经渲染器,从而合成传感器级别的视频数据,以挑战当前最先进的端到端自动驾驶(E2E AD)系统。研究结果表明,Challenger生成的驾驶场景使得现有E2E AD模型的碰撞率激增,凸显了这些系统在应对对抗性交通交互时的脆弱性。此外,研究发现,这些对抗攻击通常可以在不同的模型架构之间迁移,这进一步揭示了当前端到端自动驾驶模型可能存在的共同漏洞。希望这项研究能为自动驾驶模型的鲁棒性和泛化能力提供更深入的洞察,以应对现实世界的复杂性。
发表回复