
原文链接:https://zhuanlan.zhihu.com/p/1907601223407892139
LangCoop: Collaborative Driving with Language
项目主页(含视频)https://xiangbogaobarry.github.io/LangCoop/)
GitHubhttps://github.com/taco-group/LangCoop)
论文地址https://www.arxiv.org/pdf/2504.13406
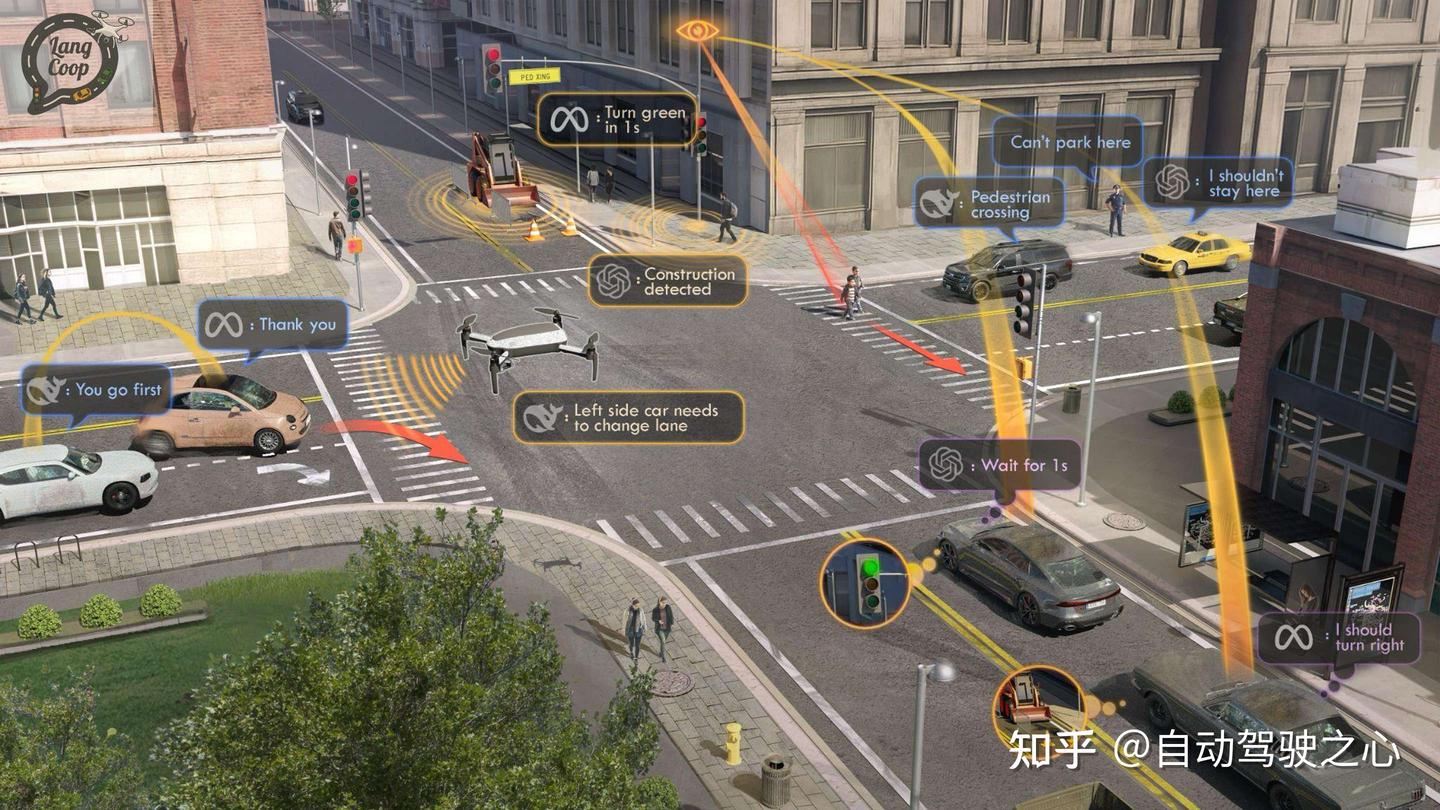
动机:从“数据共享”走向“语言协作”
车连万物(V2X
, Vehicle-to-Everything)是智能交通系统的未来核心,通过车与车(V2V)、车与路(V2I)、车与人(V2P)之间的协作,有望显著提升自动驾驶的安全性与效率。
然而,当前流行的协作范式(early collaboration, intermediate collaboration, late fusion)存在以下挑战:
- 通讯负担重:原始特征或多模态数据的传输带宽开销巨大
- 模型异构性:不同车辆使用不同模型时,信息难以有效兼容
- 信息表达力不足:融合后丢失了大量细节和上下文
随着大规模视觉语言模型
(VLMs)的崛起,我们提出:
既然人类可以用自然语言交流复杂的感知和决策,为什么车辆不能?
LangCoop 利用大模型的视觉理解与推理能力,对周围环境进行感知,并生成语言描述,从而在异构体之间实现低带宽、高语义、强泛化的通讯。
LangCoop 的核心理念
LangCoop 在理论与实证上系统性验证了自然语言作为通信媒介的独特优势:
- 低通信成本:语言具有极高的信息压缩比,每条消息 < 2KB
- 跨模型/跨主体通用性:自然语言是普适的“世界语”,可被人类和不同模型理解
- 保持上下文与关键推理信息:语言具备对抽象、高层语义的表达能力
- ️ 表达非结构化知识:如“前方事故多发,请减速慢行”,难以用向量编码表述但可用语言直观表达
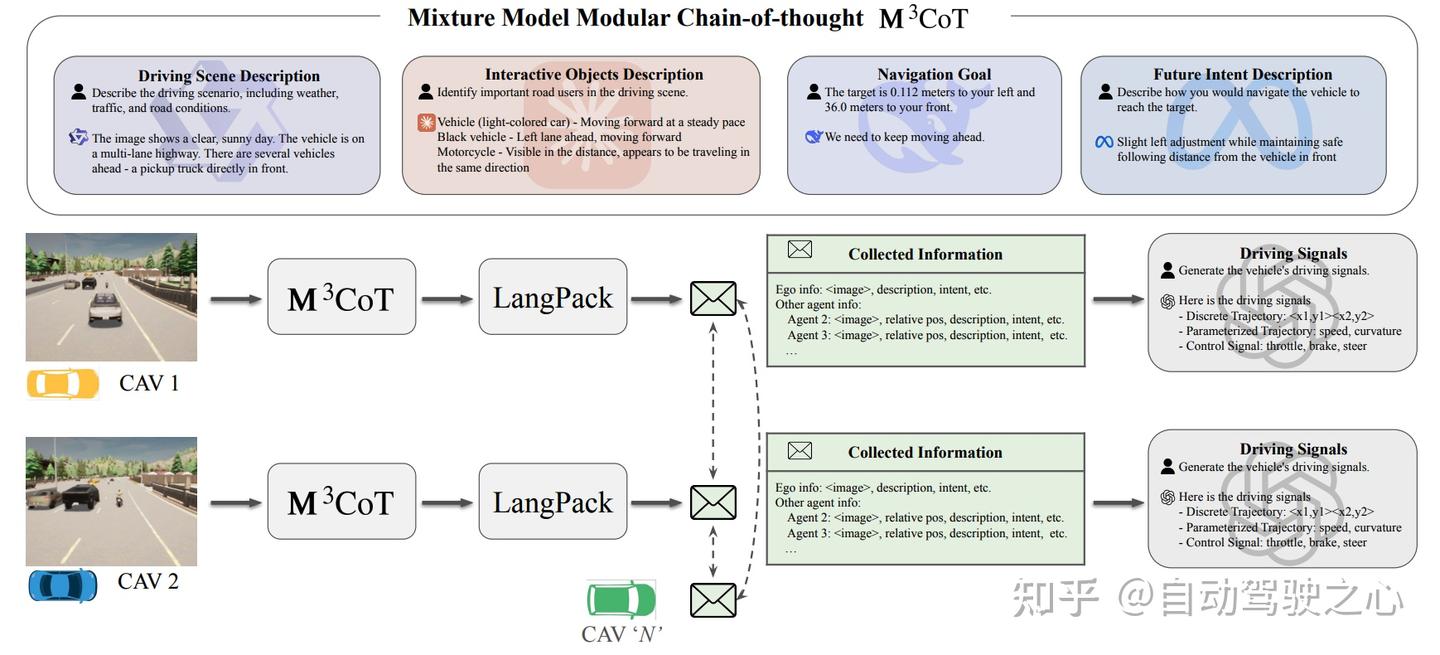
M3CoT
:模块化语言链式推理架构
我们进一步提出了 Mixture Model Modular Chain-of-Thought (M³CoT) 架构。该模块充分挖掘不同VLM模型的特长,如:
:数字与符号推理能力强GPT-4V:图像理解能力优秀Deepseek-VL
- :语言联想与发散能力强
M³CoT 通过模块化任务分工(如场景理解、对象分析、意图规划等),实现多个异构 VLM 的协同推理,显著提升了感知-决策一体化能力。
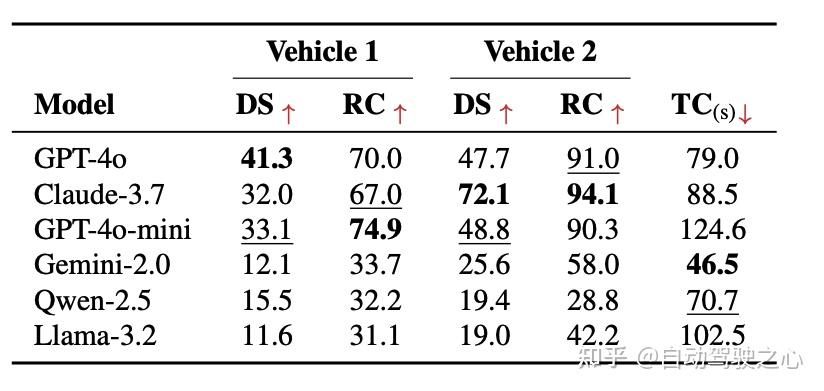
实验亮点:语言也能开车!
在 CARLA
闭环仿真中,LangCoop 展现出超越传统协作范式的能力:
- 驾驶得分高达 48.8,路线完成率 90.3%
- 显著优于非协作基线
- ️ 通信数据量 < 2KB,极度轻量
- 可适配异构主体,无需共享底层模型或向量空间
- 多个大VLM(未进行finetune)即可具备基本驾驶能力
未来展望:从实验室走向真实世界
LangCoop 为下一代通用型、可解释、可拓展的协同自动驾驶系统奠定了基础。未来,我们希望将其进一步拓展至更广泛的 V2X 场景:
与车联网(V2X)系统融合
- 支持语言格式的数据共享协议,实现人与车、车与路之间的无缝对话
️ 车-基础设施协作(V2I)
- 自然语言可用于描述道路施工、红绿灯状态、突发状况等非结构化信息,提高系统反应力和人类理解性
车-人交互(V2P)
- 车辆可向行人或非智能交通参与者发出语言提示(如“请先过马路”),实现主动对话式安全机制
通用协作代理
- 借助语言,车辆可以与无人机、清障机器人、甚至交警指挥系统协作,共同完成复杂任务
跨模态知识迁移
- 未来可探索如何将语言与图像、BEV地图、3D点云等模态融合,使得语言通讯更结构化、具备可验证性
发表回复