
原文链接:https://zhuanlan.zhihu.com/p/1905737113334419917
DriveSOTIF
- 论文标题:DriveSOTIF: Advancing Perception SOTIF Through Multimodal Large Language Models
- 论文链接:https://arxiv.org/abs/2505.07084

核心创新点:
1. 首创性融合多模态大语言模型(MLLMs)与SOTIF风险认知
- 提出首个基于MLLM的SOTIF风险感知框架,通过监督微调(SFT)将领域知识注入预训练模型(如LLaVA、Blip2),突破传统规则/学习方法在动态环境中的适应性瓶颈。创新性地引入因果推理机制,使模型具备类人驾驶员认知能力,实现对感知SOTIF风险的空间-时间联合推理 (Cognition-Causal Analysis-Prediction-Reaction闭环)。
2. DriveSOTIF数据集:首个面向感知SOTIF的多模态基准
- 构建包含1,114组图像-问答对的领域专用数据集,覆盖长尾交通场景 (如极端天气、罕见目标物),标注类型涵盖开放/闭合式VQA(5类封闭型+因果推理型问题)及细粒度图像描述。
- 提出多智能体协同生成框架 :集成GPT-4v/Claude3等视觉LLM,通过交替后端生成-验证机制降低单一模型偏倚,结合人工复核确保数据可靠性,标注一致性提升204.54%(CiDEr指标)。
3. 参数高效微调与边缘部署优化
- 采用低秩适配 (LoRA)与量化LoRA(QLoRA)技术,在仅微调0.1%参数条件下,使Blip2-6.7B模型在ROUGE-L指标提升24.56%,内存占用降低40%(4bit量化)。
- 验证模型在边缘设备的实时性:Qwen2-VL-2B在RTX 4090实现单图0.82秒推理,支持车载低延迟场景(如拥堵辅助驾驶)。
4. 跨域风险泛化能力验证
- 在加拿大滑铁卢雪天施工区与国内暴雨眩光场景中,模型成功识别传感器退化风险 (能见度<50m时车道线检测失效)与非常规目标威胁 (雪铲车遮挡、箱内隐藏行人),推荐动作符合ISO 21448标准要求(如激活危险灯+降速30%)。
- 提出混合决策框架 :将MLLM风险评估模块与DriveLLM规划器集成,实现SOTIF风险向实时控制指令的映射(如跟车距离动态扩展算法)。
5. 幻觉抑制与可解释性增强
- 设计三阶段验证代理(图像-问题-答案关联校验),将对象幻觉率降低至5%以下(基线模型达34%)。
- 通过SPICE场景图分析揭示模型对道路使用者交互关系 (如锥形桶与施工人员空间拓扑)的理解深度,提升决策透明度。
Towards Human-Centric Autonomous Driving
- 论文标题:Towards Human-Centric Autonomous Driving: A Fast-Slow Architecture Integrating Large Language Model Guidance with Reinforcement Learning
- 论文链接:https://arxiv.org/abs/2505.06875
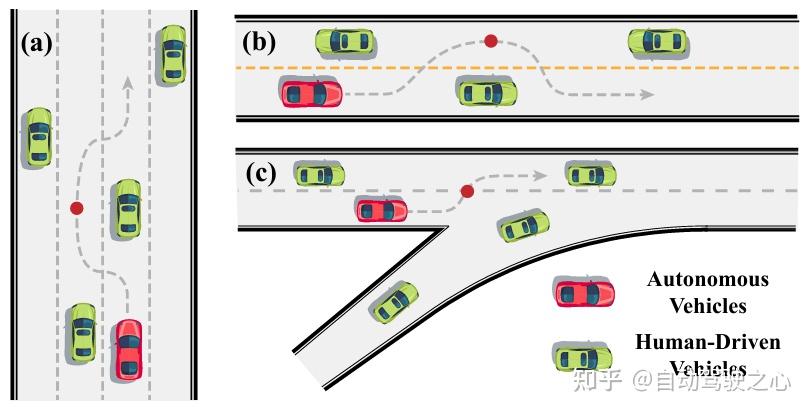
核心创新点:
1. 双通道决策架构(Dual-System Fast-Slow Architecture)
提出一种融合”慢速-快速”协同机制的决策框架:
- 慢速系统(Slow System) :基于大型语言模型(LLM)执行高阶语义解析,将自然语言指令(如”加速以准时到达”)转化为结构化上下文感知的驾驶策略,集成场景编码(Scene Encoding)、记忆检索(Memory Retrieval)及思维链推理(Chain-of-Thought Reasoning)模块;
- 快速系统(Fast System) :基于强化学习(RL)的深度注意力网络(Multi-Head Attention Policy Network)实现实时低阶控制,通过Actor-Critic优化算法与安全掩码(Safety Mask)机制保障动态安全约束。
2. 自适应指令协调机制(Adaptive Instruction Coordination)
构建LLM-RL双向交互协议:
- RL策略网络通过可微注意力机制(Differentiable Attention)动态融合LLM生成的结构化指令(Structured Directives)与观测空间特征;
- 设计优先级覆盖逻辑(Priority Override Logic),允许RL层在检测到安全冲突(如碰撞风险)时临时延迟或修正LLM指令,实现用户偏好与安全约束的动态平衡。
3. 端到端人机对齐训练范式(Human-Aligned End-to-End Training)
创新性整合多模态输入与奖励函数:
- 观测空间嵌入指令槽(Instruction Slot)与车辆动力学状态联合编码;
- 奖励函数R(s,a)显式建模四维目标:安全(R_safe)、效率(R_eff)、舒适(R_comfort)及用户偏好(R_pref),通过KL散度约束的可信域优化(Trust Region Policy Optimization)实现多目标权衡。
4. 面向真实场景的泛化增强设计(Generalization Enhancement for Real-World Scenarios)
- 采用记忆银行(Memory Bank)存储历史场景与决策案例,通过余弦相似度检索(Cosine Similarity Retrieval)提升LLM在罕见交通情境中的推理鲁棒性;
- 在策略网络中引入车道偏移随机化(Lane Offset Randomization)与对抗扰动(Adversarial Perturbation),增强系统对部分可观测环境(Partially Observable Environments)的适应能力。
Beyond Patterns
- 论文标题:Beyond Patterns: Harnessing Causal Logic for Autonomous Driving Trajectory Prediction
- 论文链接:https://arxiv.org/abs/2505.06856
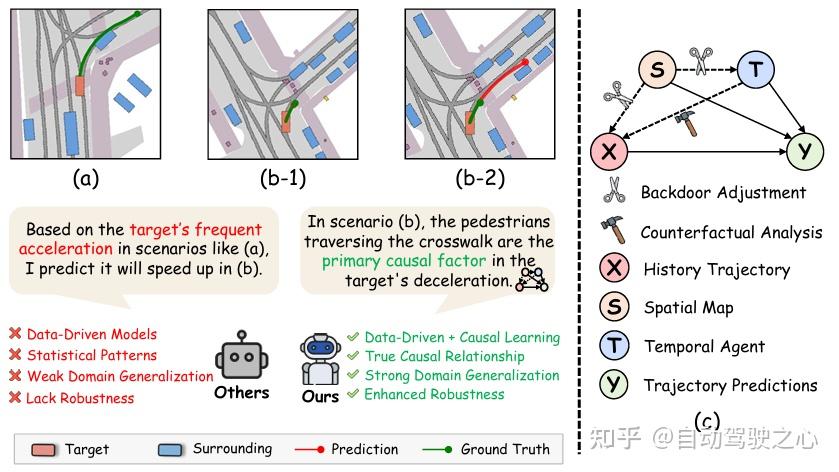
核心创新点:
1. 因果推断与轨迹预测的深度融合
- 提出首个基于因果图(Causal Graph)的轨迹预测框架,明确建模空间地图数据(S)、时序智能体数据(T)与历史轨迹(X)对目标轨迹(Y)的因果关系。
- 创新性地将后门调整(Backdoor Adjustment)与反事实分析(Counterfactual Analysis)结合,通过扩散模型生成多样化交通场景,系统消除混杂变量(如道路布局S和交互智能体T)的干扰,实现因果效应解耦。
2. 跨模态渐进融合策略
- 设计多阶段注意力机制 (Progressive Multi-Stage Attention):通过时空上下文感知模块(Spatial/BEV/Temporal Encoder)提取异构特征,采用渐进式查询更新机制(Progressive Query Refinement),模拟人类驾驶员的逐步推理过程。
- 提出双尺度信息融合 (Dual-Scale Fusion)架构:同步处理目标智能体与周围智能体的局部-全局交互信息,增强动态场景适应性。
3. 因果解耦的轨迹预测架构
- 开发因果解码器 (Causal Decoder):集成事实轨迹(Factual)与反事实轨迹(Counterfactual)的预测结果,通过差值计算(Y=Y˜−Y˜c)显式分离因果效应与相关性噪声。
- 引入扩散模型驱动的后门调整模块 (Diffusion-based Backdoor Adjustment):通过前向加噪(Equation 3)与反向去噪(Equation 4)过程,生成分层结构的空间混杂因子样本集(S¯),有效切断S→X/S→T的虚假关联。
4. 实证验证与泛化能力突破
- 在5个真实世界数据集(ApolloScape、nuScenes、NGSIM等)上全面超越SOTA方法,尤其在长周期预测(3-5s)中RMSE提升13.82%(NGSIM)和6.45%(HighD)。
- 首次实现领域泛化 (Domain Generalization)验证:通过Kolmogorov-Smirnov检验划分具有显著行为差异的区域子集,证明模型在跨区域测试中保持稳健性能。
- 模型效率优化:以0.28M参数量和57ms/样本推理速度,达到实时预测要求。
RESAR-BEV
- 论文标题:RESAR-BEV: An Explainable Progressive Residual Autoregressive Approach for Camera-Radar Fusion in BEV Segmentation
- 论文链接:https://arxiv.org/abs/2505.06515
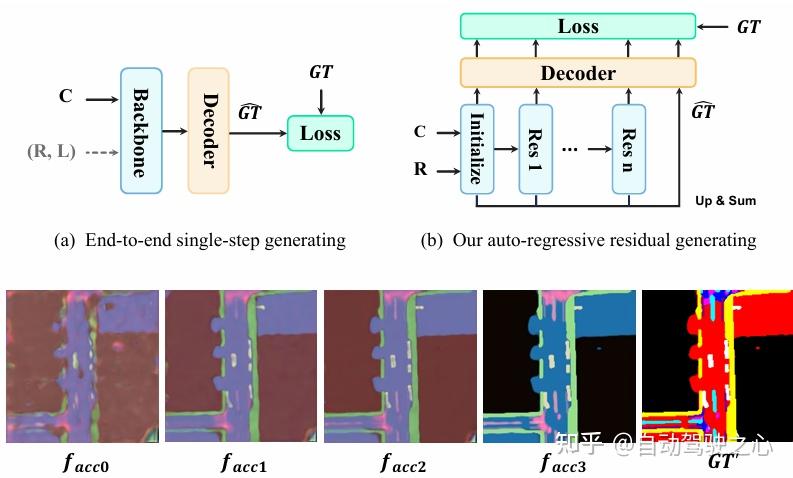
核心创新点:
1. 渐进式残差自回归学习架构
- 核心机制 :采用级联式Transformer架构 (Drive-Transformer + Modifier-Transformer),将BEV分割任务分解为粗粒度初始化→多阶段残差细化→层次化监督 的迭代过程。
- 技术细节 :
- 残差级联 :通过自回归机制逐步预测残差(Residual Token Maps),利用历史输出和雷达特征进行多尺度修正,动态调整分辨率/通道门控(resolution/channel-wise gates)。
- 层次化监督 :引入预训练的GT-Encoder-Decoder,对多尺度真值(Ground Truth)进行多级残差分解 (up-sub-down策略),在训练中强制模型学习粗略拓扑结构到精细边界的分阶段优化。
- 优势 :避免单步端到端方法的误差累积问题,提升长距离感知与复杂场景的鲁棒性。
2. 地面感知的鲁棒BEV表征优化
- 核心机制 :结合自适应高度偏移 (adaptive height offset)与双路径雷达特征编码 ,增强空间建模能力。
- 技术细节 :
- 地面邻近体素建模 :通过可学习的高度偏移率(drift rate)动态校正相机坐标系下的地面平面位置(
Y<sub>gr</sub>+ offset),缓解固定高度假设的局限性。 - 双路径雷达编码 :对点云特征进行最大池化 (提取局部显著特征)与注意力池化 (全局上下文聚合)的融合,并通过MLP压缩特征维度,实现稀疏雷达数据的高效特征增强。
- 地面邻近体素建模 :通过可学习的高度偏移率(drift rate)动态校正相机坐标系下的地面平面位置(
- 优势 :显著提升低光、远距离等挑战场景的分割精度,同时保持计算效率。
3. 解耦监督与在线联合优化策略
- 核心机制 :分离监督信号生成与模型训练流程,通过离线GT分解 与在线残差-分割联合优化 降低过拟合风险。
- 技术细节 :
- 离线多尺度GT分解 :基于RQ-VAE思想,采用动态门控残差更新 (σ(θ)⊙tanh(Down(
R<sub>i</sub>))生成多分辨率Token Maps,确保数值稳定性。 - 在线联合优化 :在训练过程中同步优化多阶段残差损失 (
L<sub>TPs</sub>)与最终分割损失(L<sub>seg</sub>),通过Dice Loss平衡类别分布。
- 离线多尺度GT分解 :基于RQ-VAE思想,采用动态门控残差更新 (σ(θ)⊙tanh(Down(
- 优势 :增强模型对遮挡、远距离等模糊区域的推理能力,同时保持结构一致性。
4. 可解释性驱动的模型设计
- 核心机制 :通过分阶段残差预测可视化 与跨模态注意力分析 ,实现生成过程的显式解释。
- 技术细节 :
- 残差生成轨迹追踪 :在不同阶段(①低分辨率粗分割→④高分辨率精细化)中,可视化Token Maps的累积过程,验证模型对复杂场景的渐进式理解。
- 注意力头差异化建模 :Transformer解码器中不同注意力头自动聚焦于道路表面(低层)、车辆(中层)或行人(高层)等语义层级,实现垂直空间信息的层次化捕获。
- 优势 :符合人类驾驶认知逻辑,支持故障诊断与决策可追溯性。
发表回复