
原文链接:https://zhuanlan.zhihu.com/p/1905783645555397029
自动驾驶通过数据驱动技术取得了显著进展,在标准化任务中实现了稳健的性能。然而,现有方法经常忽视用户特定的偏好,与用户互动和适应的空间有限。为解决这些挑战,我们提出了一种“快慢”决策框架,该框架结合了用于高层指令解析的大型语言模型(LLM)和用于低层实时决策的强化学习(RL)代理。在这一双系统中,LLM作为“慢”模块运行,将用户指令转换为结构化指导,而RL代理作为“快”模块运行,能够在严格的延迟约束下进行时间紧迫的操作。通过将高层决策与快速控制分离,我们的框架能够在保持稳健安全边际的同时实现个性化以用户为中心的操作。在各种驾驶场景中的实验评估证明了我们方法的有效性。与基线算法相比,所提出的架构不仅降低了碰撞率,而且使驾驶行为更贴近用户偏好,从而实现了以人为中心的模式。通过在决策层面整合用户指导并用实时控制加以完善,我们的框架弥合了个别乘客需求与在复杂交通环境中实现安全可靠驾驶所需严谨性之间的差距。
简介
近年来,硬件和机器学习技术的快速进步推动了自动驾驶领域的显著进展,使其有望重塑现代交通系统。尽管取得了这些进展,但在实现以人为本的设计方面仍存在一个关键差距,即自主系统解释和适应多样化用户偏好的能力,例如“请快点,我快要迟到了”。传统的数据驱动或基于规则的方法往往难以将这种高层次、可能模糊的指令转化为有效的低层控制动作。此外,许多现有方法仍然缺乏整合用户反馈的稳健机制,限制了它们在现实世界中灵活适应不断变化的需求的能力。
强化学习(RL)由于其出色的学习和泛化能力,已被广泛应用于自动驾驶决策算法的设计中。基于RL的方法在定义明确的任务中表现出色。然而,RL系统通常将用户命令视为不存在或过于简单,阻碍了它们捕捉细微或不断变化的人类意图的能力。相比之下,基于规则的方法可以更直接地编码某些人类指导原则,但它们在适应新颖或罕见场景时灵活性不足,导致次优或脆弱的表现。
与此同时,以Deepseek和ChatGPT为代表的大型语言模型(LLMs)在自然语言理解和生成方面取得了显著成功。它们的生成能力使它们能够解析复杂或抽象的指令,可能为人车交互提供一个强大的接口。然而,尽管LLMs在语言任务上表现出色,但仅凭它们不足以胜任实时、安全至关重要的控制。此外,没有明确约束的情况下,它们可能会产生忽视安全边际、交通法规或物理可行性的指令。这些考虑因素使得LLMs更适合作为“慢”系统,在此系统中,它们的解释能力可以被用来将人类偏好转化为结构化的上下文感知指导,同时将快速、精细的控制决策委托给RL代理。
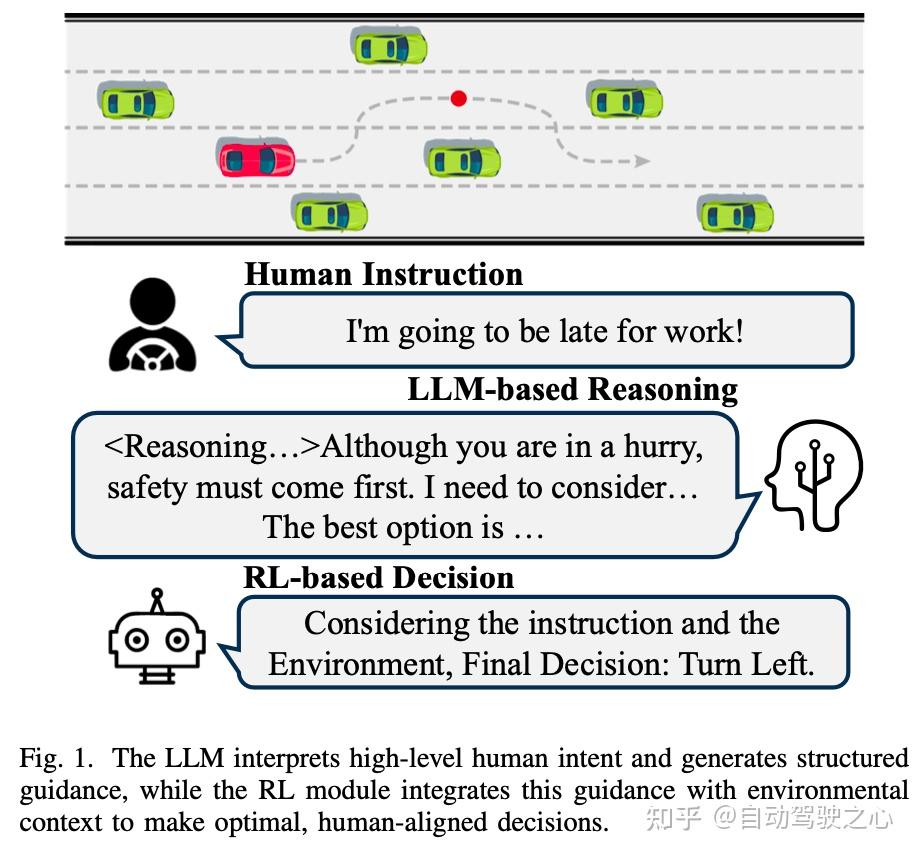
为了弥合这些互补优势之间的差距,我们提出了一种“快-慢”决策框架,该框架结合了一个用于高层命令解析的LLM和一个用于低层车辆控制的RL代理。如图1所示,LLM处理用户提供的命令并输出结构化指导信号。RL模块在实时约束下运行,然后根据LLM的命令调整转向和加速,确保适应性和稳健的安全性。通过利用LLM的解释能力和RL的效率,我们的框架解决了纯数据驱动方法与需要保证实时性能的知识驱动方法之间的差距。
我们的贡献可以总结如下:
- 提出了一种新颖的以人为中心的双层决策框架,该框架集成了用于解释高层用户指令的LLM和用于实时、低层决策的RL代理。
- 设计了一种自适应协调机制,使RL代理能够在安全约束要求时选择性地延迟或覆盖LLM的指令,从而平衡用户偏好和风险。
- 在一系列驾驶场景中对所提出的框架进行了实证评估,结果表明其在安全性和对用户偏好的遵循方面优于现有基线。
相关工作回顾
自动驾驶中的强化学习
强化学习(RL)方法越来越多地应用于自动驾驶任务中,例如换道、自适应巡航控制和超车操作。虽然这些数据驱动的方法在模拟环境中通常表现出色,但仍存在几个挑战。
大多数强化学习代理都是基于固定目标开发和评估的,无法整合现实中可能出现的不断变化的用户需求。接受人类输入的方法通常将其视为静态或过于简单,限制了它们对动态用户偏好的响应能力。同时,尽管强化学习在具有稳定奖励结构的明确定义任务中表现出色,但在遇到乘客的模糊指令时,在分布转移的情况下仍然容易出现泛化能力差的问题。这些问题凸显了需要更灵活的框架来平衡稳健策略学习与多样化用户目标的需求。
以人为本的自主系统
除了强化学习的研究之外,人们对以人为本的自主系统也日益关注。主要目标是设计能够直观解释人类偏好并将其纳入控制回路的方法。
早期的工作主要依赖语音或文本接口,使用基于规则的自然语言解析器或简单的机器学习模型,允许有限的车辆参数定制。然而,这些解决方案往往存在语言覆盖不全或缺乏理解更抽象、情境感知命令的能力。
大型语言模型(LLMs)的最新进展激发了将生成式语言能力应用于驾驶任务的兴趣。尽管LLMs在解析和生成复杂人类指令方面表现出色,但其在实时控制中的直接部署受到延迟和安全约束等因素的阻碍。为解决这些问题,一些研究人员提出了将高层语言理解与下游模块结合的混合方法。尽管有这些创新,实现LLM引导与低层驾驶控制器之间的紧密可靠集成仍然是一个开放性挑战。这一差距突显了需要架构能够将用户指令转化为可行的驾驶策略,同时保持响应性和安全性。
分层决策架构
在生物学和认知科学中,快慢系统已被确认为智能组织的关键原则,主要体现在Kahneman提出的反应性系统I和深思熟虑的系统II上。受这些双重过程理论的启发,机器人学和人工智能领域的研究者探索了分层控制架构,将高频反应控制与低频战略规划分开。
在自动驾驶汽车(AVs)的背景下,快慢范式被提出以解决快速反应决策(包括避障)与更耗时的决策(包括路线规划和复杂环境解读)之间的矛盾。最近的工作利用基于学习的方法用于高层或低层模块,但很少将广泛的用户指令与真正以人为本的“慢”决策模块结合起来。通过借鉴认知科学中的既有概念并利用现代机器学习技术,分层快慢系统可以捕捉长期目标和短期安全要求,确保自动驾驶决策尊重多样且不断变化的需求。
问题建模


方法详解
框架概述

如图2所示,所提出的系统架构分为两个主要组成部分:由大型语言模型(LLM)驱动的“慢”系统和由强化学习(RL)驱动的“快”系统。在慢系统中,LLM结合人类指令与场景上下文,生成反映用户偏好的结构化指令。
同时,相关的场景数据和决策事件存储在一个记忆库中,允许系统在未来迭代中参考和优化其决策。
快系统整合观测空间与LLM的人本主义指令,并将这些输入送入一个基于注意力机制增强的策略网络,使智能体能够强调场景和用户偏好中的关键元素。低层控制器应用经过安全掩码过滤的选定动作,以避免危险操作。
基于LLM的慢系统





仿真与性能评估
实验设置
我们在一个自定义的仿真环境中评估所提出的快慢架构,该环境结合了Highway-Env和Gymnasium
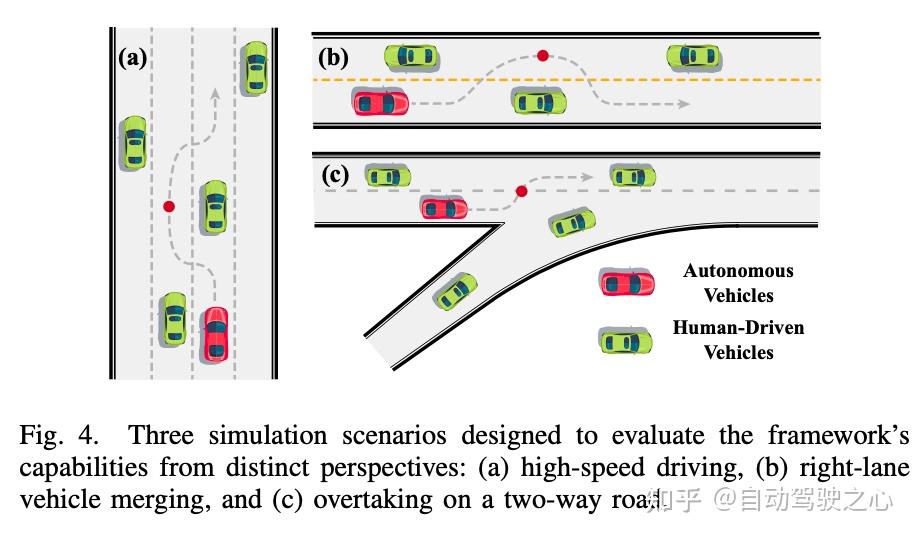
。如图4所示,设计了三个互补场景来测试自动驾驶能力的不同方面:(a) 测试高速巡航和多车道规划的直行四车道高速公路;(b) 需要自动驾驶车辆协调合并的右侧匝道;(c) 要求在对向车流存在的情况下安全超车的双向乡村道路。对于每个场景,我们生成至少100个具有随机交通种子、到达率和自动驾驶车辆起始位置的回合。
实现细节
慢系统使用GPT-4o-mini作为基准LLM,因其快速推理和可靠的逻辑推理能力。快系统的策略网络采用两个注意力头和模型维度dmodel= 128。观测向量通过一个指令槽ydis进行增强,该槽在回合开始时随机选择,并在运行时由LLM生成的车道偏好ˆit覆盖。策略优化遵循基于信任区域限制的actor-critic方案,使用折扣因子γ= 0.99和学习率5×10−4。每个模型训练105步。所有训练和验证均在一个配备Intel(R) Core(TM) i7-14700K CPU、NVIDIA GeForce RTX 4080 SUPER GPU和32 GB内存的计算平台上进行。
C. 性能评估
1) 学习效率与收敛性:
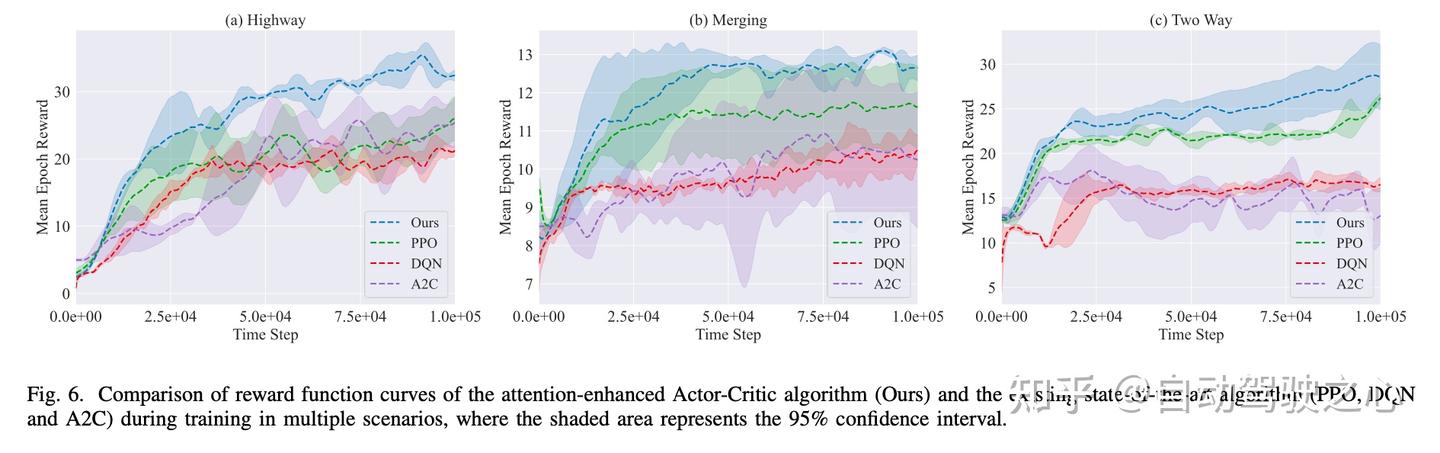
为了评估所提出快慢架构的有效性,我们将我们的模型与三种常用的RL基线模型进行比较:DQN、PPO和A2C。所有代理均使用相同的参数进行训练。
如图6所示,在每个场景中,所提出的代理最快爬升回报曲线并在最高渐近值稳定。例如,在四车道高速公路上,我们的模型在大约3 × 104次交互后超越PPO,并且收敛到比A2C高30%的回报。在合并和双向超车任务中也显示出类似的优势。我们将这种样本效率的提升归因于多头注意力模块,它共同关注环境特征和嵌入指令,使策略能够快速泛化到异构用户命令。
行为分析:
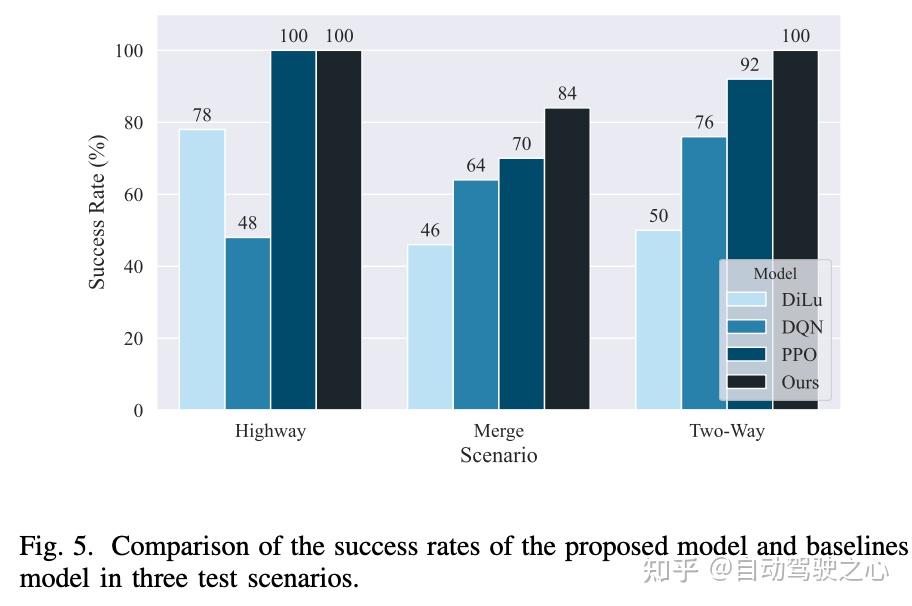
作为基准测试,我们采用最先进的RL基线模型:用于基于价值方法的DQN和用于基于策略方法的PPO,以及领先的LLM算法DiLu。如图5所示,所提出的代理在所有场景中实现了最高的成功率。
此外,表I提供了使用五个可解释指标的更细致比较。我们的代理同时提供了最低的加速度变异性,这是乘坐舒适性的指标。然而,基线异常值说明了优化单一维度的成本。
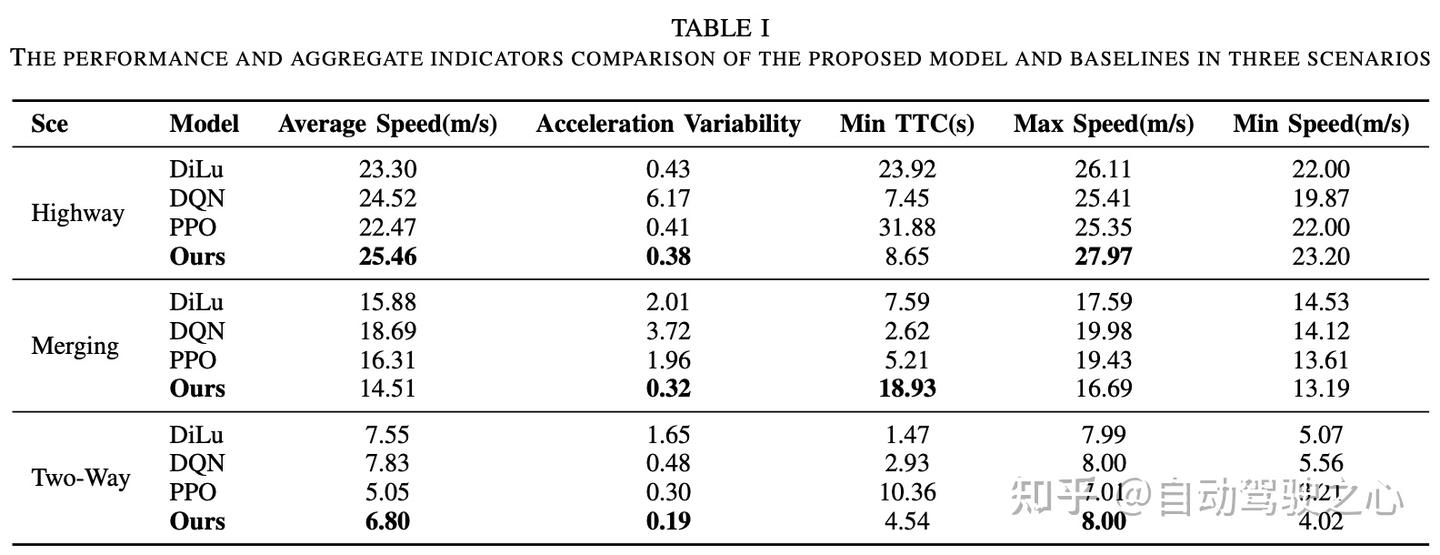
PPO通过跟随最慢的领导者在高速公路上获得最大的最小TTC,满足安全性但违反了用户按时到达的请求。DQN追求速度,但其六倍的加速度方差和易碰撞的合并行为违背了舒适性和安全性,反映了激进的风格,忽视了舒适性并偶尔导致碰撞。DiLu很好地解释了指令,但缺乏反应的精细度,在密集交通中使其成功率减半,并产生停停走走的速度轨迹。与基线模型不同,我们提出的架构在不牺牲安全性或舒适性的情况下实现了预期的车道或速度偏好,实现了符合指令的、值得信赖的以人为本自动驾驶的核心目标。
加速变异同时是最小的,这是乘坐舒适性的指标。然而,基线异常值说明了优化单一维度的成本。
PPO通过跟踪最慢的领导者在高速公路上获得最大的最小TTC,满足安全性但违反了用户按时到达的请求。DQN追求速度,但其六倍的加速度方差和易碰撞的合并行为违背了舒适性和安全性,反映了激进的风格,忽视了舒适性并偶尔导致碰撞。DiLu很好地解释了指令,但缺乏反应的精细度,在密集交通中使其成功率减半,并产生停停走走的速度轨迹。与基线模型不同,我们提出的架构在不牺牲安全性或舒适性的情况下实现了预期的车道或速度偏好,实现了符合指令的、值得信赖的以人为本自动驾驶的核心目标。
Case分析
为了展示快慢架构的定性优势,我们考察了双向超车场景,这是我们测试案例中最苛刻的,因为它需要同时考虑迎面而来的交通、车道可用性和用户意图。完整的实验视频可在我们的网站上访问。传统的RL和LLM-based算法保守地解决这种情况:它们在整个回合中停留在较慢的前车后面,从而最大化安全性但牺牲了行驶时间。相反,我们的框架接收用户指令“我急着上班,我想开得更快”。慢系统解析这个抽象请求,将其与当前场景描述结合,并发出一个倾向于迅速但安全超车的结构化指令。
如图7所示,慢系统在验证迎面车道至少有最小超车窗口清晰后,在t= 1 s时发出左转车道变更命令。快系统通过其安全掩码验证指令,并在t= 3 s前完成车道转换,加速超过较慢的车辆。这与保持在原始车道并减速的基线代理形成鲜明对比。

两个子系统之间的协调不是单方面的。在t= 20 s时,慢系统请求返回右车道以恢复正常巡航。然而,快系统检测到一辆更快的车辆正在从后面接近;立即改变车道会迫使跟随者急刹车,造成交通流冲击的风险。因此,快层暂时覆盖了指令,首先加速拉开距离,然后在t= 23 s时执行车道变更,当可以完成操作而不损害跟随者的安全边际时。
这个案例突出了所提出的人本设计的三个标志。首先,基于LLM的慢系统成功将高层次的自然语言愿望转化为精确的控制目标。其次,基于RL的快系统保留了自主权,当实时安全约束要求时可以否决或延迟指令。第三,由此产生的行为既满足了用户更快旅程的意图,又保持了舒适性和安全性,这是传统模型难以平衡的。
结论与展望
研究总结
本研究提出了一种以人为本的决策框架,该框架结合了基于大型语言模型(LLM)的“慢”系统和基于强化学习(RL)的“快”系统。LLM将自然语言指令转换为结构化指令,而RL控制器则将这些指令嵌入其观测空间并生成实时动作。广泛的仿真结果表明,所提出的架构在安全性、效率、舒适性和指令遵循之间达到了最佳平衡。
通过将高层决策与快速控制分离,我们的框架能够在保持稳健安全边际的同时实现个性化以用户为中心的操作。实验评估证明了我们方法的有效性,与基线算法相比,所提出的架构不仅降低了碰撞率,而且使驾驶行为更贴近用户偏好,从而实现了以人为中心的模式。此外,案例分析展示了所提出的快慢系统在双向超车场景中的具体表现,证明了其在复杂交通环境中处理用户意图和实时安全约束的能力。
未来研究方向
未来的研究将扩展该框架,丰富多模态输入和输出,包括语音语调和手势线索,以捕捉乘客意图的更细微方面。同时,我们计划引入感知噪声和部分可观测性,以缩小仿真与实际部署之间的差距,并随后进行实地试验。 我们还计划进一步优化LLM和RL系统的集成方式,探索如何更有效地利用LLM的推理能力来指导RL策略的学习。此外,我们将研究如何在保证实时性的前提下,提高系统的可解释性,使其决策过程更加透明,从而增强用户对自动驾驶系统的信任。 希望这项工作能够为以人为本的自动驾驶系统探索一条新的可行路径,推动自动驾驶技术向更加智能化、个性化和人性化方向发展。
发表回复