
原文链接:https://zhuanlan.zhihu.com/p/1903725539879032282
Frenet Corridor Planner
- 论文标题:Frenet Corridor Planner: An Optimal Local Path Planning Framework for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2505.03695
核心创新点:
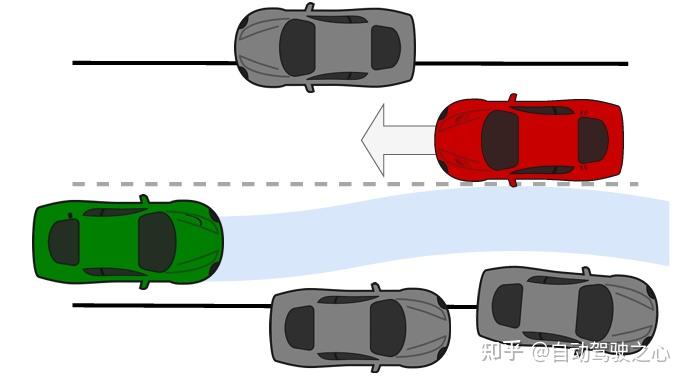
1. Frenet空间下的障碍物建模与可行驶走廊生成
- 安全增强包围盒(Safety-Augmented Bounding Boxes) :将动态车辆建模为安全扩展的矩形包围盒,行人聚类为凸包(Convex Hulls),在Frenet坐标系下实现高效障碍物表征。
- 动态偏离侧决策(Deviation Side Determination) :通过决策树(Decision Tree)确定静态障碍物的上下边界归属(Upper/Lower Bound),构建可行驶走廊(Corridor),解决传统方法在复杂场景中的边界冲突问题。
- 边界生成算法(Boundary Generation Algorithm) :基于纵向分段(Space-Domain Sampling)直接生成走廊边界,显著提升计算效率。
2. 空间域自行车运动学模型(Space-Domain Bicycle Kinematics)
- 时空解耦建模 :将传统时间域的自行车模型转换为空间域(Longitudinal Distance Δs为自变量),消除速度波动对路径规划的影响,实现路径与速度的解耦优化。
- 曲率补偿机制(Curvature-Based Correction) :引入参考路径的曲率约束,确保运动学可行性,避免因忽略道路曲率导致的路径跟踪失效。
3. 多目标非线性优化框架
- 动态障碍物风险项(Dynamic Obstacle Risk Term) :将动态障碍物轨迹预测嵌入目标函数,避免传统碰撞规避约束导致的递归不可行性。
- 鲁棒性增强 :引入松弛变量(Slack Variables)与惩罚项处理感知噪声,保障规划可行性。
4. 实验验证与部署
- 仿真与实车测试 :在CARLA仿真器及1/10比例的MuSHR硬件平台上验证了FCP的实时性(平均计算时间0.0424秒)与鲁棒性,尤其在高噪声环境下仍能保持路径一致性。
- 性能对比优势 :相比A* 、RRT等基线方法,FCP在路径平滑性(最大偏航角变化0.053 rad vs. RRT 的0.816 rad)、安全性(最小车距3.18 m vs. A的2.68 m)及实时性(0.035秒 vs. A 的0.628秒)上均显著提升。
CaRaFFusion
- 论文标题:CaRaFFusion: Improving 2D Semantic Segmentation with Camera-Radar Point Cloud Fusion and Zero-Shot Image Inpainting
- 论文链接:https://arxiv.org/abs/2505.03679

核心创新点:
1. 三阶段相机-雷达融合架构
- 跨模态特征融合 :通过交叉注意力机制(Cross-Attention)融合雷达点云空间特征与RGB图像视觉特征,生成初始分割掩码(
M<sub>init</sub>)。 - 雷达驱动的伪掩码生成 :利用Segment-Anything Model(SAM)将雷达点云投影作为点提示(Point Prompts),生成鲁棒的伪掩码(
M<sub>sam</sub>),缓解恶劣天气下视觉特征失效问题。
2. 噪声减少单元(Noise Reduction Unit, NRU)
- 动态噪声过滤 :针对雷达点云在水体表面等区域的噪声干扰,提出通道级去噪策略:
- 噪声掩码构建 :通过背景(
M<sub>background</sub>)与水面(M<sub>water</sub>)掩码叠加生成M<sub>noise</sub>。 - 掩码优化 :对伪掩码
M<sub>sam</sub>进行逐通道减法去噪(M<sub>denoised</sub> = M<sub>sam</sub>–M<sub>noise</sub>),结合ReLU激活与初始掩码叠加,输出降噪掩码M<sub>nr</sub>。
3. 零样本图像修复(Zero-Shot Image Inpainting)
- 扩散模型驱动的缺失信息重建 :基于Stable Diffusion模型,以
M<sub>nr</sub>为引导修复图像模糊/遮挡区域,生成补充信息的修复图像(I<sub>inp</sub>)。 - 双编码器特征融合 :通过独立Segformer编码器分别处理原始图像与修复图像,融合特征后输出最终分割掩码,增强对恶劣天气场景的适应性。
4. 多模态协同优化策略
- 端到端训练机制 :联合优化雷达点云分类任务与图像分割任务,通过Focal Loss与Dice Loss平衡类别分布,提升多模态特征表征能力。
- 渐进式框架设计 :分阶段训练策略(Stage 1→Stage 3)降低计算复杂度,同时通过消融实验证明各模块对mIoU提升的贡献(如NRU提升1.48%,修复模块提升0.96%)。
RIFT
- 论文标题:RIFT: Closed-Loop RL Fine-Tuning for Realistic and Controllable Traffic Simulation
- 论文链接:https://arxiv.org/abs/2505.03344
- 项目主页:https://currychen77.github.io/RIFT/
核心创新点:
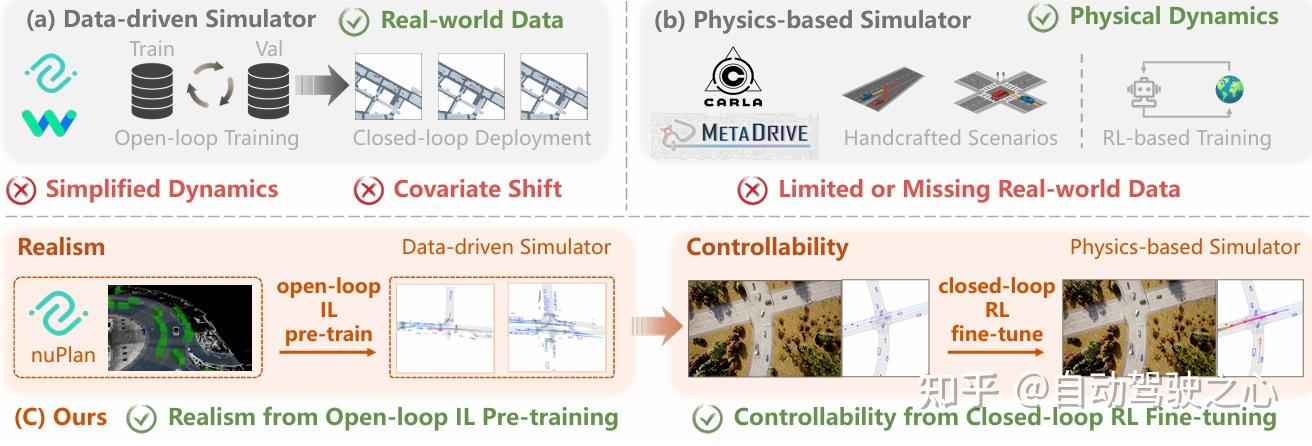
1. 双阶段仿真框架
提出开环模仿学习(IL)预训练 + 闭环强化学习(RL)微调的双阶段框架:
- 数据驱动仿真器中通过IL预训练捕捉轨迹级真实性与多模态性(如速度、加速度分布);
- 物理仿真器中通过闭环RL微调缓解协变量偏移(covariate shift),增强交互可控性,结合两类平台优势。
2. RIFT闭环微调策略
- 组相对优势(GRPO-style Group-Relative Advantage):将多候选轨迹视为组输出,计算组内相对奖励与优势,保留轨迹多模态性,避免传统RL仅优化单一最优轨迹的局限。
- 双剪裁机制(Dual-Clip Surrogate):以常数下界c>1约束负优势值,替代KL正则化,解决传统PPO在组优化中因重要性采样比率过大导致的梯度爆炸问题,提升训练稳定性。
3. 关键背景车辆(CBV)动态识别
- 基于路径级交互概率分析,筛选与自动驾驶车辆(AV)交互概率高的背景车辆,仅对CBV进行轨迹生成与微调,降低计算开销,同时聚焦关键交互场景。
4. 模块化微调设计
- 仅微调轨迹评分头(Trajectory Scoring Head),冻结预训练网络其他部分,避免破坏IL阶段学习的轨迹级真实性与多模态表征。
Automated Data Curation Using GPS
- 论文标题:Automated Data Curation Using GPS & NLP to Generate Instruction-Action Pairs for Autonomous Vehicle Vision-Language Navigation Datasets
- 论文链接:https://arxiv.org/abs/2505.03174

核心创新点:
1. 基于GPS与NLP的指令-动作对自动生成框架
- 提出了一种无需人工标注的自动化数据整理方法,通过解析移动设备GPS导航应用(如Apple Maps、Google Maps、Waze)的语音指令输出,结合自然语言处理(NLP)技术,批量生成高质量的指令-动作对(Instruction-Action Pairs, IA Pairs) 。该框架显著降低了传统依赖人工标注的数据采集成本与时耗。
2. 多模态视觉-语言-动作(VLA)三元组构建
- 将GPS轨迹(动作空间)、车载摄像头视频(视觉空间)与语音指令转录文本(语言空间)进行时空同步,构建视觉-语言-动作三元组(Vision-Language-Action Triads) ,为端到端训练视觉-语言导航模型(Vision-Language Navigation, VLN)提供结构化数据支持。
3. 导航指令的细粒度语义分类体系
- 提出包含8个语义维度的指令分类法(Road Name, Distance, Static Object, Turn, Cardinal, Location Name, Lane Information, Light Information),系统刻画了导航指令中空间参照系(spatial referentiality)的多样性,揭示了不同导航应用在指代表征上的异构特性(如距离参照vs.静态物体参照)。
4. ADVLAT-Engine原型系统
实现了完整的自动化数据采集流水线:
- 多传感器融合 :同步记录视频流、GPS坐标与语音指令
- 语音转录对齐 :采用Whisper模型实现指令时序定位
- 轨迹-语义映射 :建立车辆轨迹关键点与语言指令的跨模态关联
该系统支持扩展至LiDAR、CAN总线等传感器数据,满足不同VLA模型的输入需求。
5. 大规模指令变体数据库构建
- 通过分析3个主流导航应用在71/82/80条路径上的指令输出,构建了包含多属性组合(如”Distance+Turn+Road Name”)的指令变体库(总计78种组合模式),揭示了实际导航场景中语言指令的复杂性与多样性。
Spotting the Unexpected (STU)
- 论文标题:Spotting the Unexpected (STU): A 3D LiDAR Dataset for Anomaly Segmentation in Autonomous Driving
- 论文链接:https://arxiv.org/abs/2505.02148
- 项目主页:https://www.vision.rwth-aachen.de/stu-dataset
核心创新点:
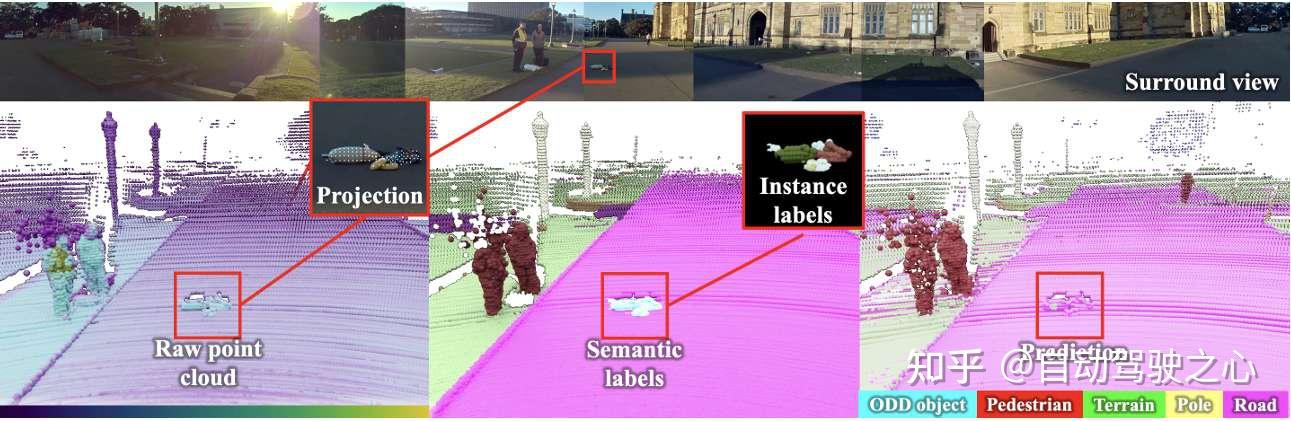
1. 首个面向自动驾驶的3D LiDAR异常分割公开数据集(STU)
- 填补领域空白 :提出首个专注于道路异常物体(Out-of-Distribution, OOD)的密集3D语义标注 数据集,结合高分辨率LiDAR点云 与同步多视角相机数据 ,支持跨模态与时间序列分析。
- 数据规模与质量 :包含70个异常序列(68个受控场景+2个真实道路场景),覆盖城市与乡村环境,标注范围达150米(训练阶段限制为50米)。提供逐点语义标签 (inlier/outlier/unlabeled)及实例级标注 ,支持全景分割评估。
- 现实场景适配 :通过分析SemanticKITTI与nuScenes标签体系,确保异常物体(如路障、碎片)与训练集无重叠,避免开放集分割的标签污染问题。
2. 多模态数据采集与标注框架
- 硬件配置 :采用128线Ouster LiDAR (垂直分辨率45°,量程200米)与8个硬件触发相机(覆盖360°视场),实现同步多模态数据采集 。
- 标注策略 :基于SemanticKITTI标签体系扩展,定义三类标签:
- Inlier :常规道路物体(车辆、行人、基础设施);
- Outlier :异常物体(非道路固有物体);
- Unlabeled :训练集中存在的弱监督类别(如路灯、垃圾桶),避免模型偏差。
- 后处理技术 :应用KISS ICP算法进行点云配准,结合Patchwork++实现地面分割;采用DashcamCleaner与DeepPrivacy2完成图像隐私保护。
3. 3D异常分割基线模型与评估体系
- 基线迁移 :将2D异常分割方法(如MaxLogit、RbA)适配至3D领域,基于Mask4Former-3D架构构建首个3D LiDAR异常分割基线 。
- 性能分析 :实验表明,现有方法在3D域表现显著下降(如Deep Ensemble在50米内AUROC=86.74,AP=5.17),揭示点云稀疏性 与长尾分布 带来的挑战。
- 评估指标 :融合点级(AUROC/FPR@95/AP)与实例级(Unknown Quality, UQ)指标,量化模型对微小异常物体(如<50点/实例)的检测能力。
DriveNetBench
- 论文标题:DriveNetBench: An Affordable and Configurable Single-Camera Benchmarking System for Autonomous Driving Networks
- 论文链接:https://arxiv.org/abs/2505.01893
- 代码:https://github.com/alibustami/DriveNetBench
核心创新点:
1. 低成本单摄像头基准测试架构
- 创新性 :首次提出基于单摄像头(单目视觉)的标准化基准测试系统,突破传统多传感器(LiDAR/雷达)系统的高成本限制。
- 技术实现 :采用现成消费级硬件(如低功耗相机、嵌入式设备)与开源软件栈,构建可复现的闭环测试环境。
- 优势 :将自动驾驶网络验证成本降低至传统方案的1/10以下(文中示例硬件清单总价约200美元)。
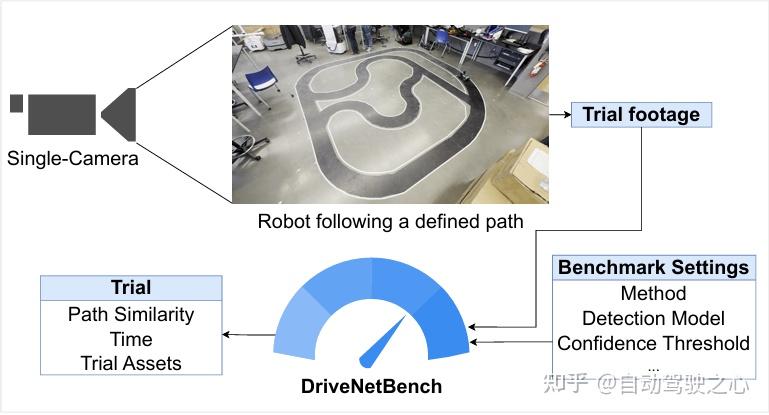
2. 模块化基准测试流水线
- 架构设计 :
- 四层解耦结构 :输入数据源 → 网络待测模块(Network Under Test) → 变换模块(Homography投影) → 评估模块。
- 黑箱兼容性 :支持任意视觉模型(如YOLO目标检测、端到端车道保持模型)即插即用,无需修改代码。
- 关键模块 :
- 数字孪生对齐 :通过Keypoints Definer与View Transformer实现物理轨迹与数字轨道坐标系的精确映射(平均重投影误差<5像素)。
- 动态路径生成 :TrackProcessor自动提取中心线作为参考路径,支持任意二维轨道设计。
3. 闭环场景下的标准化评估指标
- 核心指标 :
- 路径相似度(Path Similarity) :采用动态时间规整(DTW)与Fréchet距离双度量,量化轨迹与参考路径的匹配程度(公式1归一化处理)。
- 完成时间(Completion Time) :引入失败惩罚机制(如脱轨事件),反映算法鲁棒性。
- 误差诊断 :通过Homography关键点残差分析(图4显示5点校准后误差下降82%),保障评估可信度。
4. 可配置化实验框架
- 参数化控制 :通过YAML配置文件实现轨道布局、置信度阈值、评估指标的动态调整(无需代码修改)。
- 跨平台兼容性 :支持F1TENTH、DeepRacer等异构硬件平台的横向对比。
Learning to Drive
- 论文标题:Learning to Drive from a World Model
- 论文链接:https://arxiv.org/abs/2504.19077
核心创新点:
1. 端到端驾驶策略架构
- 提出无需手工编码感知模块或驾驶规则的端到端(E2E)训练框架,直接从人类驾驶数据学习控制策略。策略基于原始传感器输入(如图像)直接输出驾驶动作,简化系统架构并提升可扩展性。
2. 双数据驱动模拟器方法
- 重投影模拟器(Reprojective Simulation):通过深度图与姿态信息生成新视角图像,但受限于静态场景假设、深度误差及光照伪影等问题。
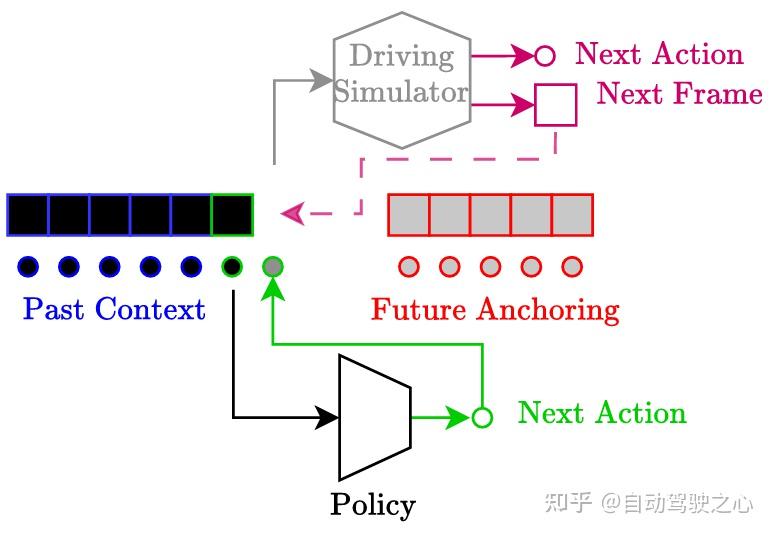
- 世界模型模拟器(World Model Simulation):基于扩散变换器(Diffusion Transformer, DiT)和未来锚定(Future Anchoring)技术,预测动态场景的未来状态与轨迹,支持策略在非独立同分布(non-i.i.d.)数据下的训练,并生成符合人类驾驶行为的视频序列。
3. 未来锚定机制(Future Anchoring)
- 在World Model中引入未来目标状态F作为条件,通过规划头(Plan Head)生成收敛于目标的轨迹,解决策略在错误状态下的恢复问题(Recovery Pressure),提升闭环模拟的稳定性。
4. 在策略训练(On-Policy Learning)与信息瓶颈
- 采用类IMPALA架构,通过并行执行器(Actors)与中心学习者(Learner)交互,使策略从自身交互中学习纠错。
- 引入信息瓶颈(Information Bottleneck),通过添加高斯噪声限制特征提取器的信息容量(约700 bits),抑制策略对模拟器伪影的过拟合。
5. 扩散建模与噪声增强技术
- 基于Rectified Flow目标的扩散模型生成环境状态,结合多假设规划损失(MHP Loss)优化轨迹预测。
- 采用噪声水平增强(Noise Level Augmentation),缓解自回归漂移(Auto-regressive Drift)问题,提升模型对累积误差的鲁棒性。
6. 实际部署验证
- 在开源ADAS系统(openpilot)中部署策略,实现真实车辆的横向控制(如车道保持、变道)。实验表明,World Model策略在闭循环测试(MetaDrive)中通过率超90%,并在真实路测中达到52.49%的连续介入里程占比,验证了方法的实用性与可扩展性。
发表回复