
原文链接:https://zhuanlan.zhihu.com/p/1903467090184242640
Safety-Critical Traffic Simulation
- 论文标题:Safety-Critical Traffic Simulation with Guided Latent Diffusion Model
- 论文链接:https://arxiv.org/abs/2505.00515
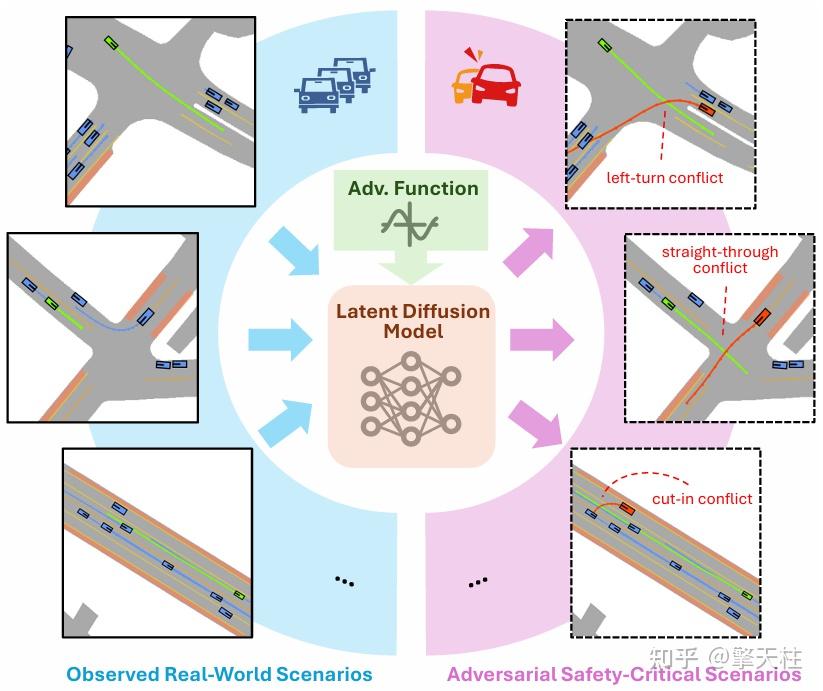
核心创新点:
1. 基于图神经网络的潜在扩散模型架构
- 提出融合图变分自编码器(GNN-VAE)与扩散模型的框架,在潜在空间中建模多智能体交互关系。通过图编码器将交通场景的时空拓扑映射到紧致潜在表征,利用U-Net结构在潜在空间执行扩散去噪过程,显著提升计算效率(相比轨迹空间操作)并保留复杂交互特征。
2. 对抗性引导目标函数设计
引入可微分的复合引导项,实现可控的安全临界场景生成:
- 行为真实性约束:通过车辆间碰撞惩罚与路权约束确保非对抗/对抗车辆的行为合理性;
- 对抗性目标:定义与自车中心距离的负阈值函数,驱动对抗车辆主动制造冲突;
- 采用梯度注入策略在DDIM采样过程中动态调整潜在变量,实现对抗性与物理可行性的协同优化。
3. 物理可行性感知的样本选择机制
- 构建包含纵向/侧向加速度约束的可行性指标 Φ(τ),通过加权评分函数筛选生成轨迹,从运动学层面保障输出场景的物理可实现性,解决传统方法中常见的不切实际轨迹问题。
4. 高效扩散采样与端到端训练策略
- 采用DDIM(去噪扩散隐式模型)加速推理过程,通过预定义方差调度建立非马尔可夫逆扩散过程,支持跳步采样而不损失质量;固定预训练VAE参数,仅优化扩散模型噪声预测网络,降低训练复杂度。
Inconsistency-based Active Learning
- 论文标题:Inconsistency-based Active Learning for LiDAR Object Detection
- 论文链接:https://arxiv.org/abs/2505.00511

核心创新点:
1. LiDAR域特异性增强不一致主动学习框架
- 提出首个针对LiDAR点云的主动学习策略,通过水平镜像增强生成样本对(原始点云与镜像点云),量化模型预测不一致性作为样本价值评估指标。该方法突破了传统图像域主动学习对颜色/亮度变换的依赖,适配点云数据特性。
2. 检测框数量驱动的不一致评分机制(NoB Score)
创新性地采用检测框数量差异作为核心不一致度量:
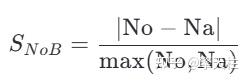
其中No/Na分别为原始/增强点云的检测框数。该评分通过归一化处理弱化绝对数量影响,在低数据量场景下展现出更强的样本判别能力(如20%-40%数据区间相对不一致度达0.5 vs. 0.09)。
3. 训练范式优化与实证分析
- 提出「自底向上」(Scratch)与「迭代重训练」(Retrain)双训练策略:
- Scratch模式在完整数据范围实现2.58%的mAP提升,验证了增量学习的有效性
- Retrain模式在低数据量(30%数据)时即可达到随机采样60%数据的性能,证明模型鲁棒性提升
- 发现IoU基线方法存在局限性:其对远距离目标定位误差敏感,导致不一致信号被噪声淹没,而NoB评分通过平滑处理保留了有效训练信息。
4. 类间性能异质性建模
- 揭示主动学习对不同目标类别的差异化增益:
- 行人检测在全数据范围持续优于基线(+2.5% AP)
- 自行车类虽样本稀缺(仅4.67%标注),但在高数据量区间仍保持1-2% AP增益
- 汽车类(占比82.5%)在中低数据量实现>1% AP提升,证明方法对长尾分布的适应性
HeAL3D
- 论文标题:HeAL3D: Heuristical-enhanced Active Learning for 3D Object Detection
- 论文链接:https://arxiv.org/abs/2505.00507

核心创新点:
1. 启发式增强的不确定性估计框架
首创性地将物理场景中的先验知识(目标距离衰减特性与点云密度分布)引入3D检测主动学习(AL)体系,通过距离归一化因子和对数点密度因子对高斯混合模型(GMM)协方差矩阵进行动态加权修正,实现了物理特征与深度学习不确定性的跨模态融合。
2. 多维度不一致性度量架构
- 构建基于KL散度的联合优化目标,通过:
- 空间维度:对比原始点云与180°旋转增强后的3D高斯概率图
- 类别维度:建立类感知GMM网络,计算类级KL散度
- 最终融合公式:
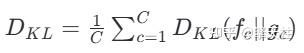
实现检测置信度、定位精度和类别判别力的三重不确定性量化。
3. 渐进式主动学习策略
- 提出数据域自适应的两阶段采样机制:
- 初始阶段采用KECOR方法快速建立基础性能(图3显示前3轮KECOR优于随机采样)
- 中后期切换为HeAL策略,通过GMM-KL准则在8轮AL中实现mAP 3%的持续提升(超越现有SOTA方法CRB 4.9%)
4. 可解释性增强的采样优先级生成
- 设计层次化不确定性图谱:
- 底层:基于点云几何特性的物理不确定性建模
- 中层:GMM表征的空间分布不一致性检测
- 高层:类别语义空间的判别矛盾分析
- 通过消融实验验证各模块贡献(表1显示完整方案在Easy/Moderate/Hard难度分别达79.3/66.2/62.3 mAP),证明多源信息融合的有效性。
FedEMA
- 论文标题:FedEMA: Federated Exponential Moving Averaging with Negative Entropy Regularizer in Autonomous Driving
- 论文链接:https://arxiv.org/abs/2505.00318
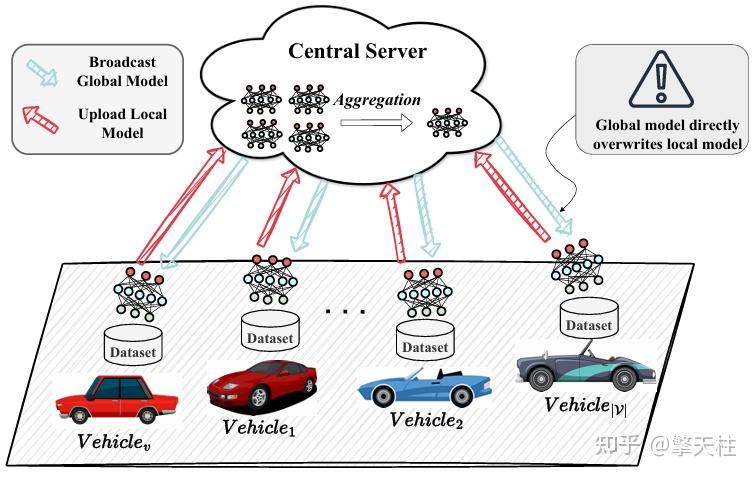
核心创新点:
1. 服务器端指数移动平均(EMA)历史模型融合机制
- 提出联邦指数移动平均(FedEMA)框架 ,通过递归融合当前联邦学习(FL)回合的聚合模型与历史EMA模型,保留历史模型的拟合能力。
- 解决传统联邦自动驾驶(FedAD)系统中因模型覆盖更新导致的灾难性遗忘问题 ,平衡历史知识保留与新环境适应性。
2. 车辆端负熵正则化训练策略
- 引入负熵正则化项(Negative Entropy Regularizer) ,对本地模型损失函数进行优化,其中衡量输出概率分布的负熵。
- 抑制因历史EMA模型引入的时间模式导致的时间过拟合(Temporal Overfitting) ,提升模型跨场景泛化能力。
3. 理论收敛性分析与双目标优化
- 理论证明FedEMA在非凸损失下的收敛率,与标准联邦优化一致。
- 分析表明负熵正则化项λ可降低客户端漂移(Client Drift)、加速收敛,并缓解数据异构性影响。
- 实验验证FedEMA在Cityscapes和CamVid数据集上实现7.12% mIoU提升 ,显著优于现有联邦学习算法(如FedProx、FedDyn等)。
V3LMA
- 论文标题:V3LMA: Visual 3D-enhanced Language Model for Autonomous Driving
- 论文链接:https://arxiv.org/abs/2505.00156

核心创新点:
1. V3LMA框架设计
- 提出首个零样本 (zero-shot)的多模态3D场景理解框架,通过无参数微调 (parameter-efficient)的LLM(Large Language Model)与LVLM(Large Vision Language Model)融合架构,突破传统方法对领域微调的依赖。该框架通过模块化预处理管道 (modular preprocessing pipeline)将3D目标检测(基于Grounded SAM、YOLOv5、MiDAS等)转化为结构化文本描述,为LLM提供空间关系推理所需的语义信息。
2. 多粒度特征融合机制
创新性地实现跨模型特征级联:
- 层级融合策略 (layer-wise fusion):在LLM与LVLM的Transformer解码块(decoder blocks)间动态融合特征,经消融实验证实融合最后4层(layers 25-28)效果最佳;
- 动态权重分配 (adaptive weighting):采用可调节的特征权重(如LLM:LVLM=0.9:0.1)平衡多模态信息流,避免传统融合中的分布偏移问题;
- 分支隔离处理 (branch isolation):仅通过LLM分支处理融合特征,保留LVLM独立处理视觉特征的能力,充分发挥LLM对复杂提示的处理优势。
3. 3D增强的场景理解模块
构建端到端3D感知增强系统:
- 多传感器融合 :集成单目深度估计(MiDAS)、实例分割(Grounded SAM)与目标检测(YOLOv5),生成精确的3D定位(depth value from detection mid-pixel);
- 上下文感知标注 :通过CLIP-for-GTSRB模型实现交通标志的细粒度分类与描述生成,结合余弦相似度匹配机制(cosine similarity thresholding)提升识别鲁棒性;
- 时空一致性维护 :采用跨帧ID跟踪(cross-frame ID assignment)与深度归一化(depth normalization),解决动态场景下的时序连贯性问题。
4. 自动驾驶场景验证
在LingoQA基准测试中,V3LMA以零样本设置达到0.56 Lingo Score,超越未微调基线23%,且参数效率显著(V3LMA-Q-mini仅3.5B参数即达49%性能)。通过系统性消融研究验证了:
- 晚期融合(late fusion)优于早期融合;
- LLM主导的特征融合更适应复杂推理任务;
- 特征权重分配存在跨参数耦合效应(cross-correlation),需联合优化。
A Survey Interactive Generative Video
- 论文标题:A Survey of Interactive Generative Video
- 论文链接:https://arxiv.org/abs/2504.21853
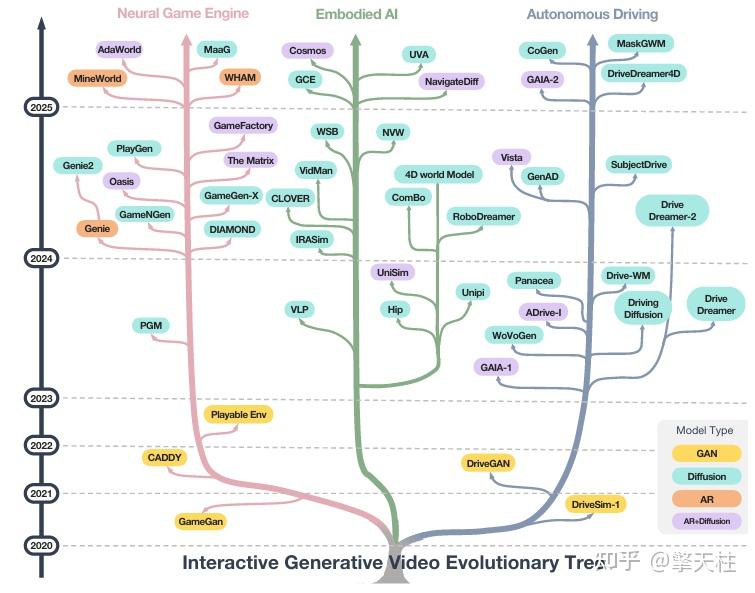
核心创新点:
1. 系统化框架构建
提出交互式生成视频(Interactive Generative Video, IGV)的统一框架,将其分解为五大核心模块:
- 生成(Generation):支持流式生成(Streaming Generation)、实时处理(Real-time Processing)及多模态生成(Multi-modal Generation)。
- 控制(Control):通过导航控制(Navigation Control)与交互控制(Interaction Control)实现用户意图的精准映射。
- 记忆(Memory):结合静态记忆(Static Memory)与动态记忆(Dynamic Memory),保障场景一致性及长期时序连贯性(Long-term Coherence)。
- 动态(Dynamics):模拟物理法则(Physical Laws)并支持参数化物理调参(Physics Tuning)。
- 智能(Intelligence):集成因果推理(Causal Reasoning)与自我演化(Self-Evolution)能力,推动虚拟环境向自进化元宇宙(Self-evolving Metaverse)发展。
2. 跨领域技术整合与应用
- 游戏领域:提出生成式游戏引擎(Generative Game Engine, GGE),通过IGV实现无限探索的开放域游戏内容生成,支持动态场景合成与玩家交互。
- 具身AI(Embodied AI):作为物理感知的环境合成器,生成高保真视频序列用于机器人任务规划(Task Planning)与策略学习(Policy Learning),解决训练数据不足问题。
- 自动驾驶:构建基于视频的闭环仿真系统,模拟复杂交通场景,支持安全关键测试与实时决策优化。
3. 关键技术挑战与未来方向
- 生成模块:优化实时性(Real-time Generation)与开放域控制(Open-domain Control),探索混合架构(如AR+Diffusion)。
- 动态模块:提升物理仿真精度,开发标准化评估指标。
- 智能模块:结合大语言模型(LLMs)实现因果推理与多模态融合(Multimodal Fusion)。
- 系统集成:解决模拟与现实差距(Sim-to-Real Gap),推动轻量化模型与自适应演化机制。
发表回复