
原文链接:https://zhuanlan.zhihu.com/p/1890419779791209015
端到端自动驾驶目前是有望实现完全自动驾驶的一条有前景的途径。然而,现有的端到端自动驾驶系统通常采用主干网络与多任务头结合的方式,但是它们存在任务协调和系统复杂度高的问题。为此,本文提出了DiffAD,它统一了各种驾驶目标并且联合优化所有驾驶任务。实验结果证明了该方法的优越性。
01 论文摘要
端到端自动驾驶(E2E-AD)已经快速成为实现完全自主驾驶的一种有前景的方法。然而,现有的E2E-AD系统通常采用传统的多任务框架,通过单独的特定任务头来解决感知、预测和规划任务。尽管这些系统以完全可微分的方式进行训练,但是它们仍然会遇到任务协调问题,系统复杂度仍然很高。本项工作引入了DiffAD,这是一种新的扩散概率模型,它将自动驾驶重新定义为一种条件图像生成任务。通过将异构目标在统一的鸟瞰图(BEV)上进行栅格化并且对其潜在分布进行建模,DiffAD统一了各种驾驶目标并且在单个框架内联合优化了所有驾驶任务,这显著降低了系统复杂度并且实现了任务协调。反向过程迭代地细化生成的BEV图像
,从而产生更鲁棒、更逼真的驾驶行为。在Carla中的闭环评估证明了所提出方法的优越性,实现了最佳的成功率和驾驶得分。
02 论文介绍
实现完全自动驾驶不仅需要对复杂场景进行深入理解,还需要与动态环境实现有效交互和对驾驶行为进行全面学习。传统的自动驾驶系统建立在模块化架构的基础上,其中感知、预测和规划是单独开发的,然后集成到车载系统中。虽然这种设计提供了可解释性并且便于调试,但是不同模块的单独优化目标往往会导致信息丢失和误差累积。
最近的端到端自动驾驶(E2E-AD)方法试图通过实现所有组件的联合、完全可微分的训练来克服这些局限性,如图1(a)所示。
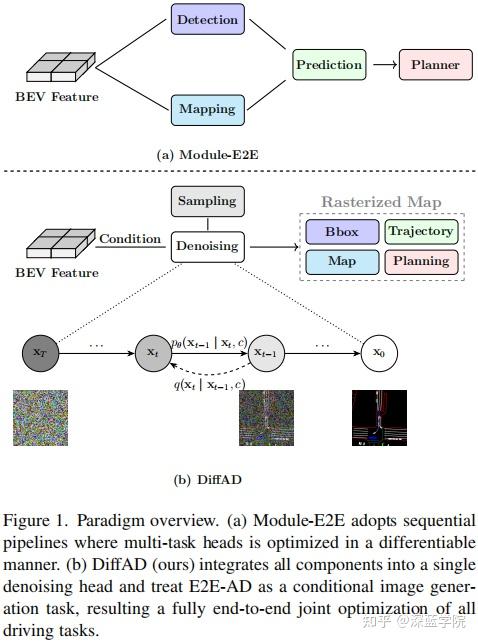
然而,目前仍然存在几个关键问题:
1)次优优化:UniAD和VAD等方法仍然依赖于顺序流程,其中规划阶段依赖于前面模块的输出结果。这种依赖性会放大整个系统的误差;
2)低效的查询建模:当前基于查询的方法部署了数千个可学习的查询来捕获潜在的交通元素。这种方法导致计算资源的分配效率低下,过度关注上游辅助任务而不是核心规划模块。例如,在VAD中,感知任务消耗了总运行时间的34.6%,而规划模块的运行时间仅占5.7%;
3)协调的复杂性:每个任务头都使用不同的目标函数进行单独优化,目标的形状和语义也各不相同,整个系统变得分裂并且难以连贯训练。
为了解决这些局限性,本文提出了一种新的范式DiffAD,它将所有驾驶任务的优化统一在单个模型中,如图1(b)所示。具体而言,本文将来自感知、预测和规划的异构目标在统一的鸟瞰图(BEV)空间上进行栅格化,从而将自动驾驶问题重新定义为条件图像生成问题。本文采用一种去噪扩散概率模型来学习由环视图生成的BEV图像的分布。该方法不仅能够同时优化所有任务,从而缓解了误差传播问题,还通过共享解码头在潜在空间中利用计算高效的生成建模策略替代了低效的基于矢量的查询方法。此外,通过仅关注噪声预测,而不需要多个损失函数或者复杂的二分匹配,本文方法显著地简化了整个训练过程。
总之,DiffAD通过将任务统一到单个端到端框架中,克服了现有基于查询的顺序方法的局限性,该框架增强了协调,减少了误差传播,并且更高效地分配计算资源,以实现安全且有效的规划。
本文的主要贡献总结如下:
1)本文引入了一种端到端的自动驾驶范式,该范式利用统一的、完全栅格化的BEV表示将各种驾驶任务集成到单个模型中;
2)本文将驾驶任务重新表述为条件图像生成问题,并且提出了DiffAD,这是一种扩散模型
,它可以学习由环视图生成的BEV图像的潜在分布。此外,本文还提出了一种数据驱动方法,它从生成的BEV图像中提取矢量化规划轨迹;
3)本文证明,DiffAD在端到端规划方面实现了最先进的性能,其在闭环评估方面明显优于先前的方法。
03 DiffAD
概述:如图2所示,DiffAD由三个主要部分组成:潜在扩散模型、BEV特征生成器和轨迹提取网络(TEN)。
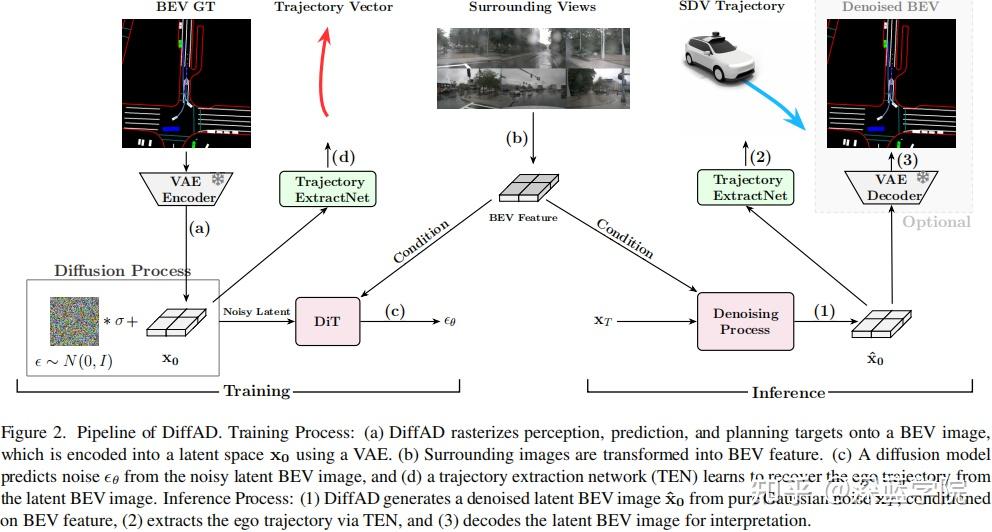
训练过程:
1)栅格化和潜在空间编码:DiffAD首先将感知、预测和规划目标在BEV图像中进行栅格化。然后,使用现成的VAE编码器将BEV图像压缩到潜在空间中以进行降维;
2)特征提取和转换:将环视图像传入特征提取器,它将得到的透视图特征转换为统一的BEV特征;
3)噪声预测的扩散模型:将高斯噪声加入潜在的BEV图像中,以获得带有噪声的潜在BEV图像。基于边界元法特征,训练扩散模型以从带有噪声的潜在表示中预测噪声;
4)轨迹提取:训练基于查询的TEN,从潜在BEV图像中恢复自车的矢量化轨迹。
推理过程:
1)条件去噪:DiffAD首先根据BEV特征,从纯高斯噪声中生成去噪的潜在BEV图像;
2)规划提取:TEN从潜在BEV图像中提取自车的规划轨迹;
3)BEV解码:通过将潜在BEV图像解码回像素空间,可以获得预测的BEV图像,用于解释和调试。
3.1. 栅格化BEV表示

3.2. 去噪扩散学习


3.3 轨迹提取网络

3.4 端到端学习

04 实验
4.1. 数据集
对于E2E模型,开环评估是不够的。为了解决这个问题,本文在CARLA仿真器
中使用Bench2Drive数据集进行训练和闭环评估。Bench2Drive提供了三个数据子集:mini(10个片段用于调试)、base(1000个片段)和full(10000个片段用于大规模研究)。本文使用base子集进行训练。
4.2. 指标
1)成功率(SR):该指标计算了在分配的时间内成功完成且没有违反交通的路径比例;
2)驾驶评分(DS):该指标考虑了路径完成率和违规处罚;
3)FID:本文使用Frechet Inception Distance(FID)来评估缩放性能,这是评估图像生成模型的标准指标。
4.3. 基线
1)UniAD:一种经典的基于模块的E2E方法,它采用基于查询的架构来显式地连接感知、预测和规划任务;
2)VAD:另一种基于模块的E2E方法,它通过利用Transformer查询与矢量化场景表示来提高计算效率;
3)AD-MLP:一种基线模型,它通过简单地将自车的历史状态传入MLP来预测未来的轨迹;
4)TCP:一种简单但有效的基线,它仅使用前视相机和自身状态来预测轨迹和控制命令;
5)ThinkTwice:一种促进由粗到精框架的方法,迭代地细化规划路径,并且利用专家特征蒸馏;
6)DriveAdapter:Bench2Drive排行榜上表现最佳的方法,它通过解耦感知和规划,充分利用专家特征蒸馏来提升性能。
4.4. 实现细节
训练:本文使用来自稳定扩散的现成预训练变分自动编码器(VAE)模型。VAE编码器的下采样系数为8。在本节的所有实验中,扩散模型都在潜在空间中运行。本文保留了DiT中的扩散超参数。为了促进学习过程,本文在第一阶段从单张图像学习开始用于感知部分,即检测和建图,而预测和规划中的BEV图像则填充为零。然后将模型与所有感知、预测和规划部分联合训练。
推理:本文利用DDIM-10采样器进行推理,并且使用官方的评估工具来计算闭环指标。对于车辆控制,本文采用官方提供的PID控制器。
4.5. 主要结果
表格1中的总体结果表明,DiffAD明显优于包括UniAD和VAD在内的基线方法,并且超过了ThinkTwice和DriveAdapter等基于蒸馏的方法的性能。
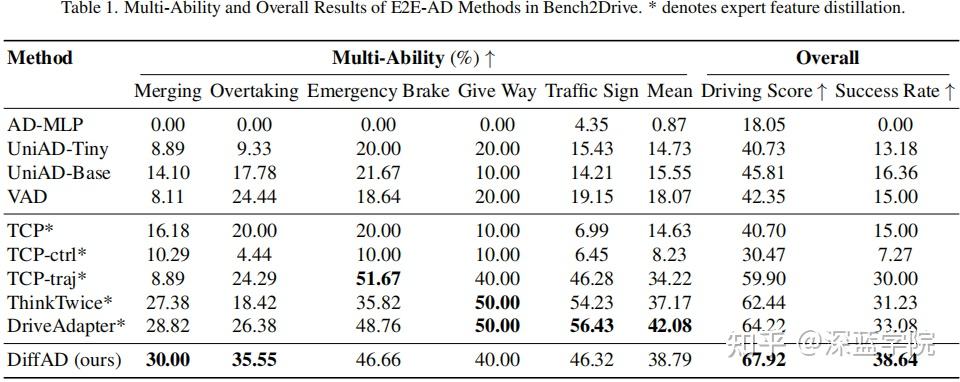
在多项能力评估中,DiffAD在并道和紧急制动等交互式场景中比UniAD和VAD具有显著优势。这一改进归功于其集成的学习框架,该框架使任务目标之间能够显式地交互,从而实现了更连贯、更有效的规划。由于训练数据集的规模相对较小,与利用专家特征蒸馏的方法相比,DiffAD在交通标志方面的性能略低。结合专家特征(提供了有价值的驾驶知识)可以帮助缓解潜在的过拟合问题。因此,利用专家特征蒸馏的模型(例如TCP、ThinkTwice和DriveAdapter)通常优于没有利用它的模型(例如VAD和UniAD)。
本文对DiffAD进行失效案例分析,如图3所示。
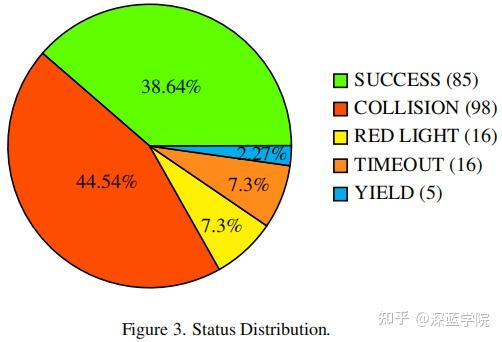
分析表明,很大一部分路径失效是由与交通智能体发生碰撞导致的,这表明在CARLA v2中的交互存在挑战。此外,少数失效是由于超时造成的,通常是由于规划模块在停止后偶尔无法恢复运动引起的,通过利用专家蒸馏或者加入更多的交通信号灯交互数据可以有效地缓解这个问题。一小部分失效发生在智能体闯红灯时,可能是由于CARLA中交通信号灯的渲染质量低或者存在具有挑战性的光照条件使其难以检测。
4.6. 消融研究
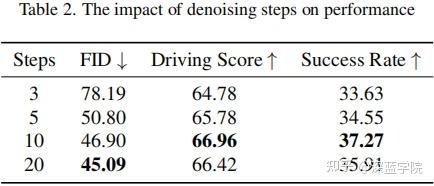
去噪步数对性能的影响:DiffAD的迭代去噪遵循由粗到精的细化过程,逐步地改进感知和规划。如表格2所示,将去噪步数从3增加到10可以显著降低FID(-53.5%),同时提高驾驶得分(+2.18)和成功率(+3.64),这表明多步细化有助于解决轨迹模糊问题。然而,将步数扩展到10以上(例如,扩展到20)会导致性能饱和,这表明计算开销和规划精度之间达到了最佳平衡。
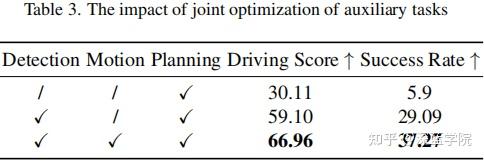
任务联合优化的影响:本文研究了联合优化辅助任务对规划性能的影响。如表格3所示,三个任务的联合优化实现了最佳的结果,突显了任务联合优化在提高规划性能方面的重要性。
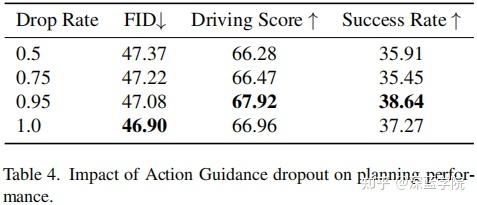
行为引导dropout的影响:直观上,过度依赖先前的决策会增加关键紧急情况下的响应延迟。相反,在不考虑先前行为的情况下做出决策可能会导致突发的感知错误,从而导致不切实际的规划结果。为了更好地理解这种权衡,本文分析了行为引导模块中不同dropout率对规划性能的影响。表格4展示了不同dropout率的结果。0.95的dropout率实现了最佳平衡,这表明保留一小部分先前的行为引导有利于鲁棒的规划。
统一生成建模的效率:如表格5所示,尽管DiffAD的参数规模更大(545.6M vs VAD的58.1M),但是它实现了具有竞争力的延迟(258ms vs 140ms)和实时FPS(3.9)。
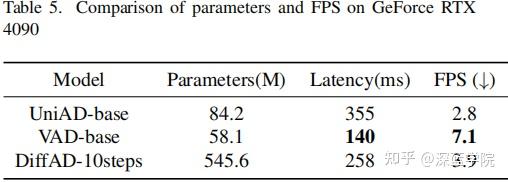
该效率归功于两项关键创新:
1)任务无关压缩:VAE有效地压缩了BEV图像,同时保留了关键信息,大大减少了用于交互和细化的tokens数量;
2)并行扩散头:与顺序多任务流程不同,DiffAD采用共享的去噪网络来联合优化所有驾驶任务,消除了级联推理的低效问题。
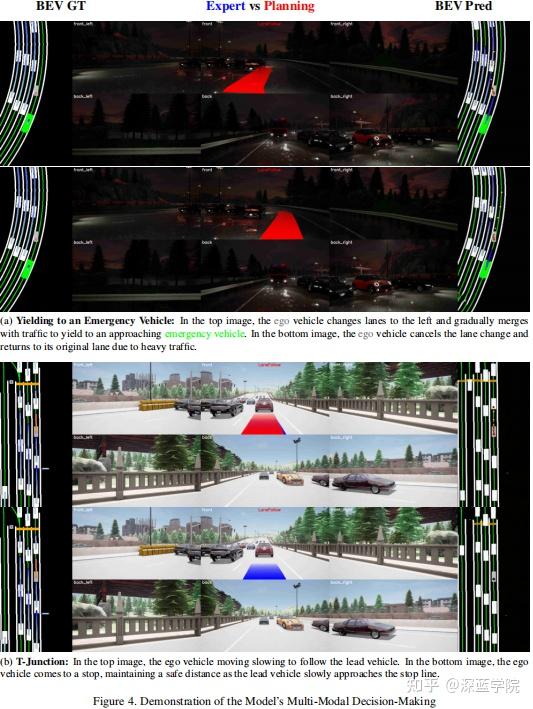
生成建模的多模态:在图4中,本文展现了定性结果,其展示了DiffAD强大的生成能力及其产生不同规划结果的能力。对于每种场景,本文通过采样不同的潜在变量来生成两个决策。本文将规划轨迹(红色)和专家轨迹(蓝色)叠加到环视相机的原始前视图像上。BEV真值(GT)显示在左侧,而预测的BEV显示在右侧。值得注意的是,生成的BEV与真值密切对齐,并且各种规划的轨迹始终是安全且合理的。这展现了DiffAD准确感知环境和有效学习交互行为的能力。
05 总结和未来工作
本项工作提出了DiffAD,这是一种基于扩散框架的端到端自动驾驶模型。本文的主要贡献在于将驾驶任务的异构目标转化为统一的栅格化表示,将E2E-AD表述为条件图像生成任务。该方法简化了问题,并且为利用各种生成模型(例如扩散模型、GANs、VAE和自回归模型)提供了明确的途径。本文认为,DiffAD的强大性能突显了生成模型在推进自动驾驶研究方面的潜力,并且希望它能够激发该领域的进一步探索。
局限性和未来工作:尽管本文框架具有前景,但是在Carla v2中的成功率仍然远未达到完美。有效地利用多模态生成预测进行规划以及使模型输出与人类偏好相一致是值得进一步探索的方向。此外,Carla中的交通仿真与现实世界条件之间存在显著差距。为了解决这个问题,未来工作将在实车上部署该系统,以评估其在现实交通场景中的性能。
发表回复