
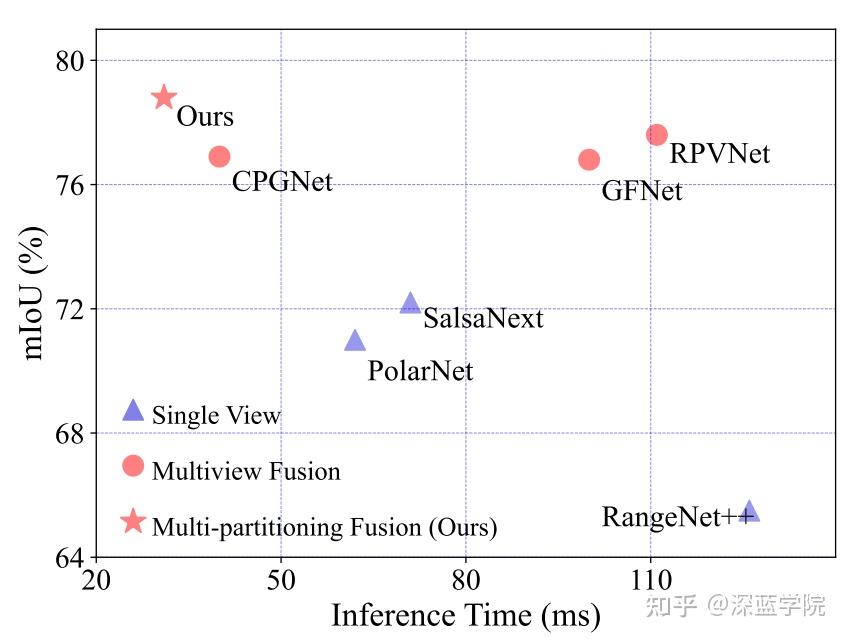
引言:本文提出了一种基于鸟瞰图(BEV)空间的激光雷达点云分割方法,该方法通过融合极坐标和笛卡尔分区策略,实现了快速且高效的特征融合。该方法利用固定网格对应关系,避免了传统点云交互中的计算瓶颈,并通过混合Transformer-CNN架构增强了场景理解能力。实验结果证明,该方法在性能和推理速度方面均优于现有的多视图融合技术。
论文标题:PC-BEV: An Efficient Polar-Cartesian BEV Fusion Framework for LiDAR Semantic Segmentation
论文作者:Shoumeng Qiu, Xinrun Li, Xiangyang Xue, Jian Pu
论文链接:https://arxiv.org/pdf/2412.14821
1、背景介绍
激光雷达点云分割是自动驾驶领域的核心任务,其目标在于精细地理解周围环境的语义信息。目前,该领域的方法主要分为三类:基于点的方法、基于体素的方法和基于投影的方法。
其中,基于投影的方法因其能够利用2D卷积神经网络
(CNN)高效处理投影点云而受到青睐。但是,相比于计算量大的基于体素方法,从3D到2D的投影过程中不可避免地丢失信息,这限制了这种算法的性能。
为了缩小这一性能差距,多视图融合技术应运而生,通过整合不同投影技术捕获的互补信息。近期的多视图融合方法,如AMVNet、GFNet和CPGNet,通过基于点的特征交互增强了表示学习。
然而,由于缺乏视图间的固定对应关系,这些方法需要进行高成本的网格采样和散射操作,影响了实时性能。此外,特征融合通常仅限于点存在的区域,可能会忽略周围区域中有价值的上下文信息。
2、方法提出
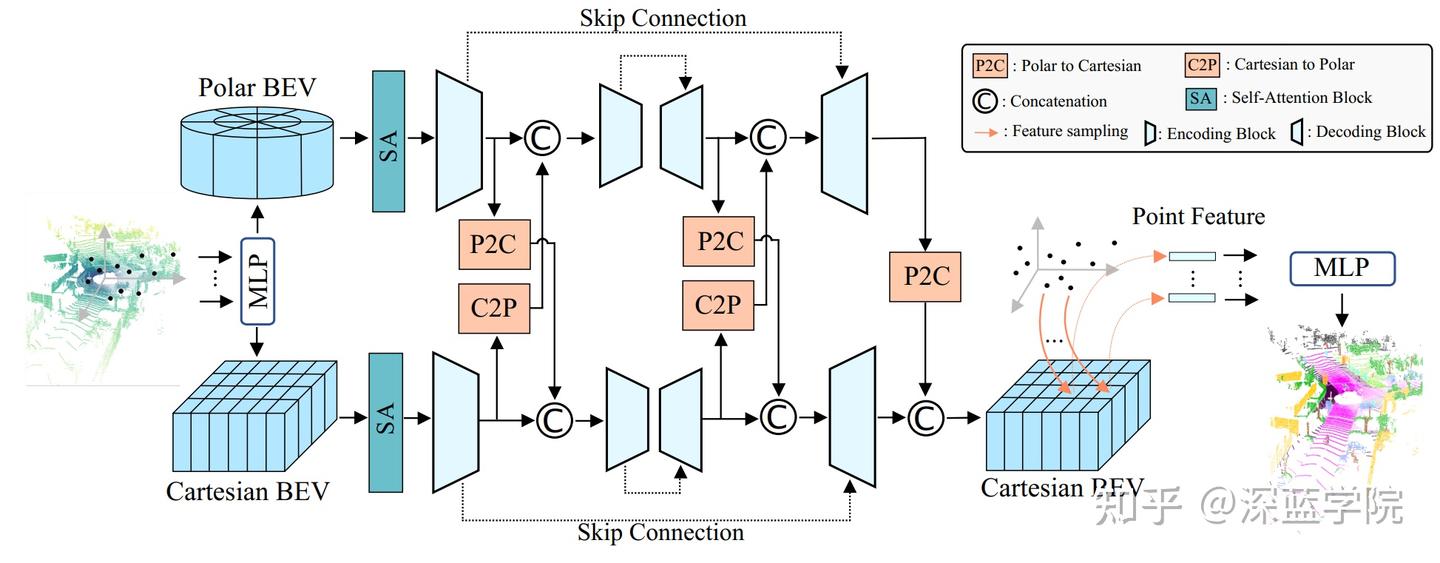
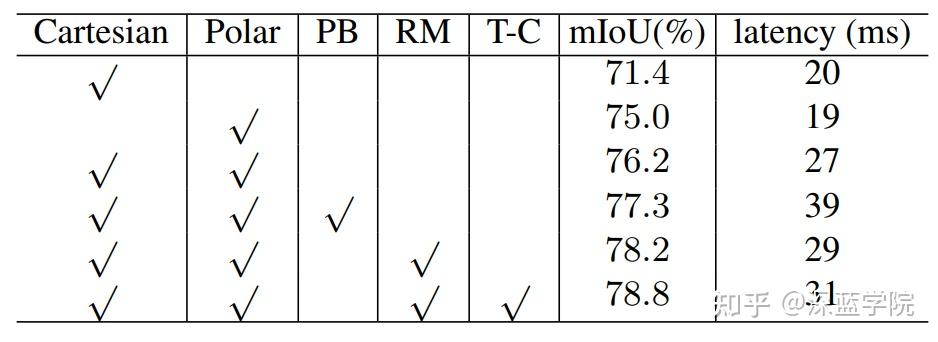
为了克服这些限制,作者提出了一种创新的多分区特征融合框架,完全在BEV空间内操作,充分利用了极坐标和笛卡尔分区方案之间的固定对应关系。该方法受到BEV中极坐标分区与范围视图中球坐标分区相似性的启发,并且实验表明不同分区方法的性能具有互补性。
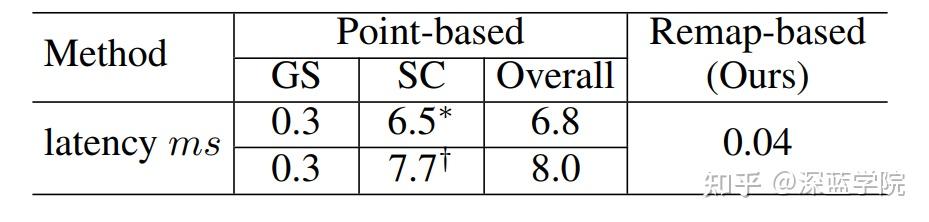
为了促进极坐标和笛卡尔分支之间的特征融合,作者引入了一种高效且有效的基于重映射的融合方法。利用极坐标和笛卡尔空间分区在相同BEV空间内固有的固定坐标对应关系,预先计算对应参数,再通过精心设计的重映射操作实现高效特征融合。这种方法比以往的基于点的特征交互方法快170倍。此外,所有的特征融合在BEV空间位置操作,不仅实现了密集融合,还保留了比以往基于点的方法更多的宝贵上下文信息。
作者还提出了一种混合Transformer-CNN架构,用于BEV特征提取。Transformer块中的自注意力捕获全局场景信息,然后是一个轻量级的U-net样式CNN用于详细特征提取。实验结果表明,这种架构在保持实时推理能力的同时增强了模型性能。



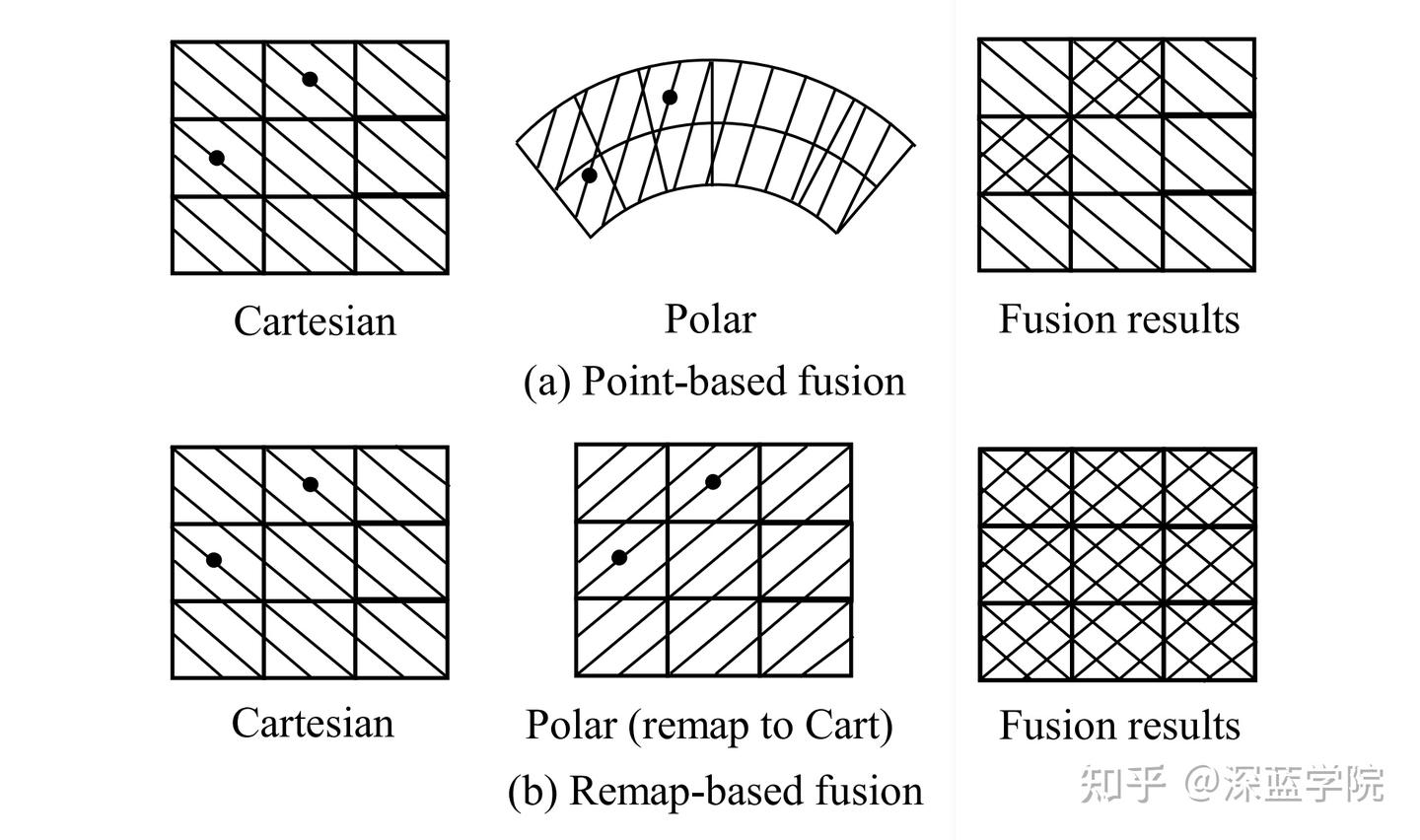
▲图3 | 在不同设置下,比较先前的基于点的方法和基于重映射的方法的特征交互操作过程。©️【深蓝AI】编译

如图4所示,基于点的方法仅在存在点的区域进行融合,丢弃了没有点的特征,作者称之为稀疏融合。相比之下,基于重映射的方法使整个BEV空间内的融合成为可能,实现了密集融合,丰富了来自另一分支的特征信息。

4、实验结果
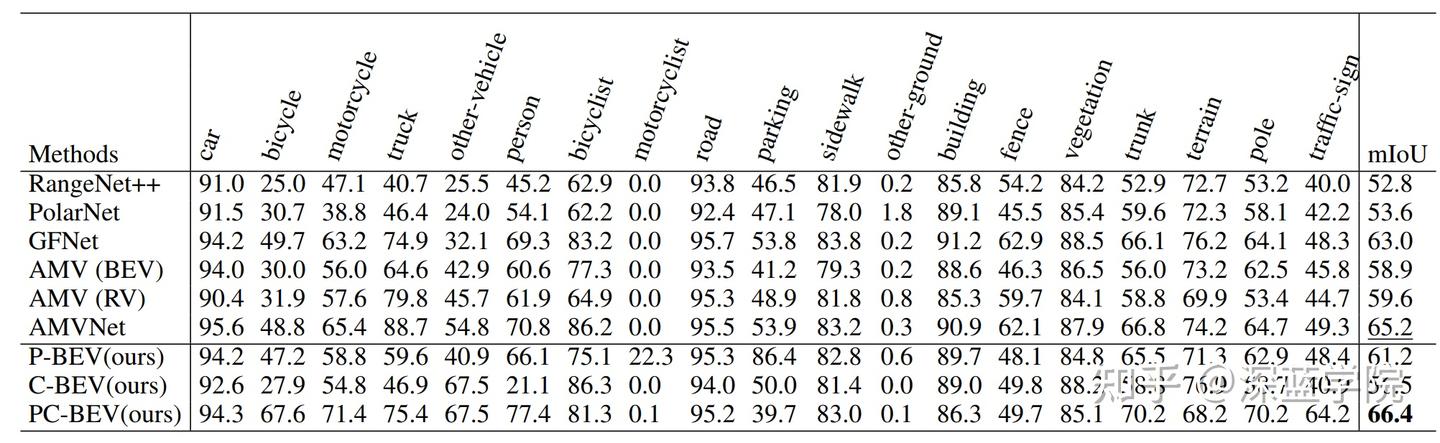
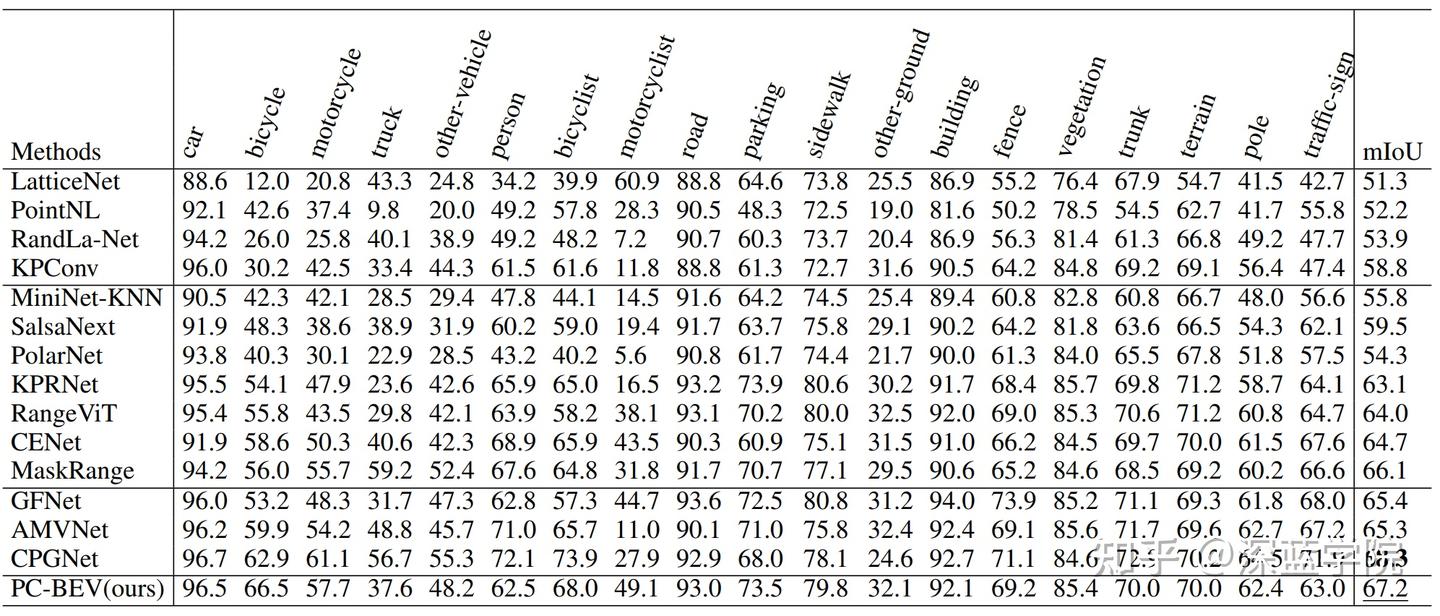
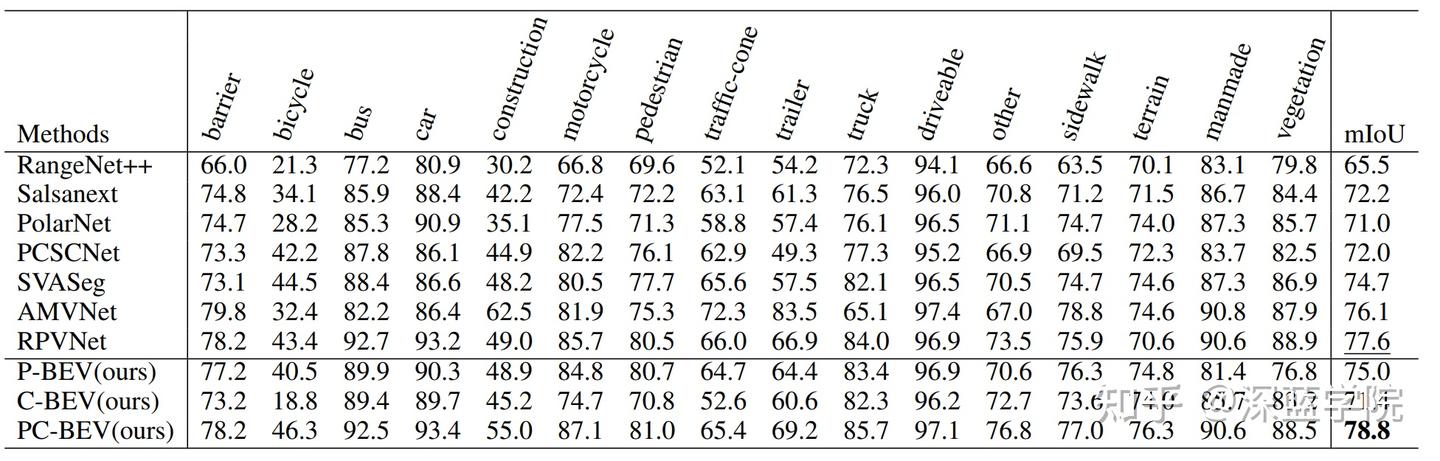
作者在SemanticKITTI和nuScenes数据集上进行了广泛的实验,证明了本方法以更快的推理速度实现了最先进的性能。
5、本文总结
本文介绍了一种新颖的实时激光雷达点云分割方法。该技术采用作者研发的高效重映射空间对齐融合策略,通过优化内存连续性,不仅大幅提升了处理速度,而且在性能上超越了传统的基于点的交互方法,同时还能保留更为详尽的上下文信息。
此外,文章中还介绍了一种Transformer-CNN混合架构,该架构在维持实时处理能力的基础上,进一步增强了模型的整体性能。通过在SemanticKITTI和nuScenes数据集上进行的广泛实验,充分验证了该方法的有效性和高效率。
展望未来,研究者可以会进一步探索将此技术应用于由多相机图像数据生成的BEV(鸟瞰图)表示,以拓展其应用范围。
发表回复