
核心:
CVPR 2023 Tesla和Wayve展示的所谓World Model。凭借自动驾驶车辆采集的大量实景视频数据,可以利用生成模型去生成未来场景来和真实的未来时刻数据对比,从而构建loss,这样就可以不依赖标注信息对模型进行训练。这个任务非常接近文字接龙,而它最巧妙的地方则在于要想成功预测未来时刻的场景,你必须对现在时刻场景的语义信息以及世界演化的规律有着深刻的了解。
应用:
显而易见生成式的World Model可以被用来当作一种仿真工具来生成仿真数据,特别是极为少见的Corner Case的数据。
然而World Model更有潜力的应用方向我认为是World Model可能会成为像GPT一样的自动驾驶领域的基础模型,而其他自动驾驶具体任务都会围绕这个基础模型进行研发构建。
模型:
恰巧的是最近Elon Musk在Twitter上两次提到Tesla正在研究Diffusion Model,而且他们发现Diffusion可能比Attention更加高效。这次CVPR 2023 Phil Duan明确说明Tesla不仅在图像转BEV的时候使用了Transformer,还在很多其他模块中也大量使用Transformer,而这次CVPR上Tesla和小鹏的Patrick都提到Transformer的部署优化至关重要,Tesla在实验Diffusion Model的性能效率,这说明Tesla很可能在努力尝试将FSD模型中大量使用的基于Transformer的特征提取层部分甚至全部用Diffusion Model的模型进行替代。
Tesla
Tesla的世界模型,是以OCC占据栅格网络为基础的。
整体网络构架
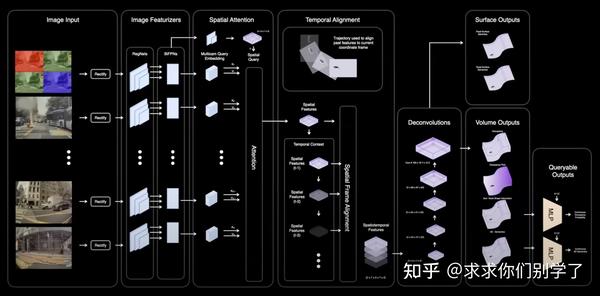
特斯拉的网络架构:
原始图片数据
移除ISP循环并且不进行色调映射
使用相机校准矫正图像
特征提取器
图像特征提取器:使用RegNet + BiFPN提取多层次的图像特征
视图转换器
构建一组3D位置查询,同时使用图像空间特征作为键和值,然后将它们输入到注意力模块中,得到高维空间特征的输出。
空间对齐
将空间特征与车辆运动测量数据对齐,以捕获运动效应,并创建丰富的时空特征。
网络输出
通过一系列的反卷积来输出体积占用/语义/流。
体积OCC输出是在固定大小的网格中,有时对于控制来说不够精确。
每个体积网格都有特征图。我们使用3D位置查询和MLPs来获得更精细的输出。
Lane
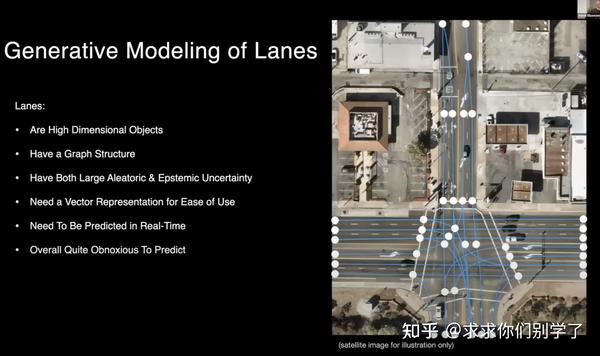
车道预测是非常难的:车道是高维的。车辆是独立的,但是车道可以横跨在整个道路上。多条道路、分叉、合并、不确定性(掉漆、破坏)、遮挡、不可见、建模困难、人类有时也无法区分是一条还是两条车道、最好预测成矢量(折线、多项式) 。
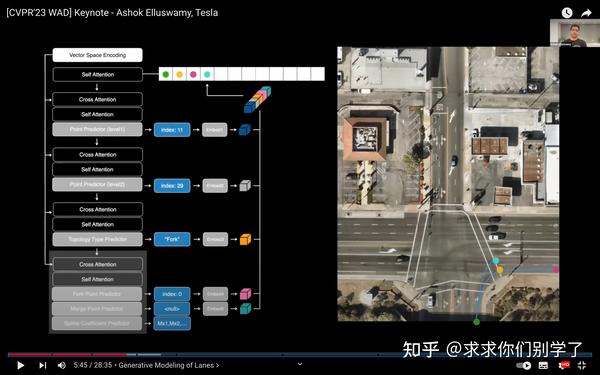
车道建模方法:自回归的transformer,类似GPT。必须预测完整的图形结构。
Object
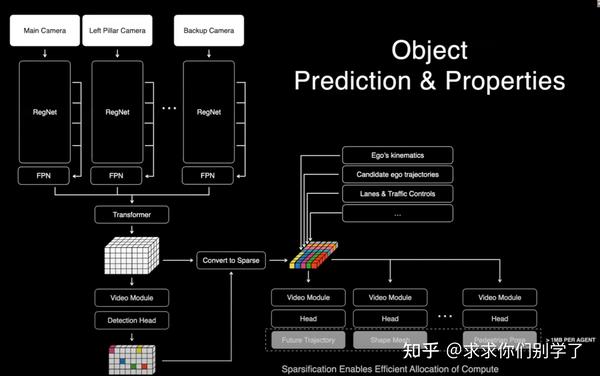
多模态:图片、车辆运动学(速度、加速度、导航指令)端到端:没有跟踪
World model
核心:过去的数据来生成未来的数据。也是在占用网络的基础上进行的。目的:占据栅格网络很通用,但是有些东西也很难表达。所以学习一个更通用的模型来表示任意事物。(预测运动规律、物理规律等)
亮点:• 受到生成模型和扩散的启发。• 根据过去的场景和动作,对所有摄像机一致地以 3D 方式预测未来。使用极其多样化的 3D 数据进行训练,RGB非常通用,可以从视频剪辑、YouTube。都可以用来训练通用的世界模型。* 没有任何先验,让网络自己去理解深度和运动。

亮点:①Tesla可以做到多个摄像头同步联合预测。②支持prompt嵌入,可以提出要求生成车辆直行或者对向车道视角的未来数据。(同样的过去数据输入,不同prompt,生成符合要求的输出数据。这个还是挺震撼的)
Wayve
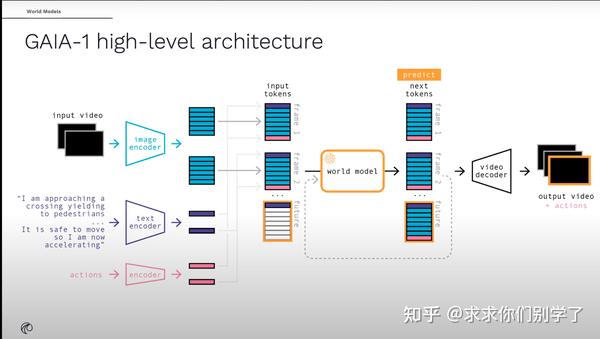
目的:
自监督的、自回归的世界模型。
利用视频、文本和动作输入来生成逼真的驾驶视频,并为自车行为和场景特征提供细粒度的控制。
学习到如何安全驾驶。
网络:
输入:多模态输入video、text、action,对所有输入进行编码,文本和视频编码器离散化并嵌入输入,而代表动作的标量独立地投影到共享表示中。编码在时间线上对齐,实现连贯性。
世界模型:自回归的transformer,根据过去的图像以及文本和动作token提供的上下文信息来预测序列中的下一组图像token。能实现不仅视觉连贯,且能够基于文本和动作的指导生成图像token。
视频解码:扩散模型,将图像token转回图像像素。
感想:
GPT的成功,在于文本的训练数据和模型可以非常大,采用根据前文,mask到后文来预测后文的方式,能够不需要标注即可生成大量的训练数据。当数据量达到一定程度时,会发现大的语言模型在所有的子任务中,甚至不加微调都可以达到很好的效果,模型的确可以学到更高维度的信息。图像也希望做到这一点,有从MAE去mask图像像素来训练。world model是更加类似GPT的思想。
世界模型想要通过视频,来尝试理解整个场景,对运动规律、物理规则去进行理解,无疑是非常困难的。世界模型也不仅仅用于自动驾驶或者感知,这是个通用的人工智能。如果能做得很好,或许我们将逐步踏入真正的人工智能时代。
目前的世界模型生成的未来数据效果还比较一般,在wayve展示的视频中,很多若隐若现,或者中途车辆不断变化的情况。
prompt大模型在自动驾驶的应用,可谓是未来可期。未来的自动驾驶大模型一定是多模态的。可以结合人类指令、导航地图信息(甚至给一张场景图片,chatgpt也能给出这个图片的潜在危险),这些都是可以辅助自动驾驶的。
世界模型训练还是挺耗时的。wayve的世界模型,需要在64张A100训练15天,有65亿参数。视频解码模块也需要在32张A100训练15天,26亿参数量。
笔者水平有限,作为学习记录,后续再补充,未完待续
发表回复