
当下各类视频网站应用了各种时序动作提取和多模态信息匹配的技术,用于自动化的视频分类、标签生成以及视频指纹(用于视频细节的相似度比较)等应用,极大提高了应用的便利性和可玩性。同样在自动驾驶领域,我们也可以利用类似的技术,对于时序类型的自动驾驶数据进行场景提取、分类等处理。
具体过程如下(以视频数据举例):
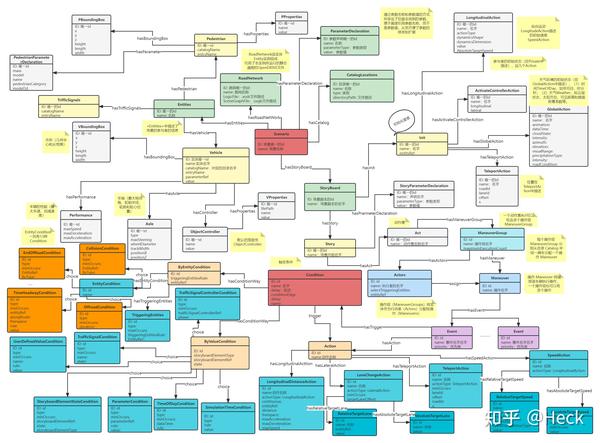
第一步,根据对智能驾驶场景的理解构建知识图谱,通过知识图谱丰富对场景内容的理解,比如参考OpenDrive和OpenScenario:
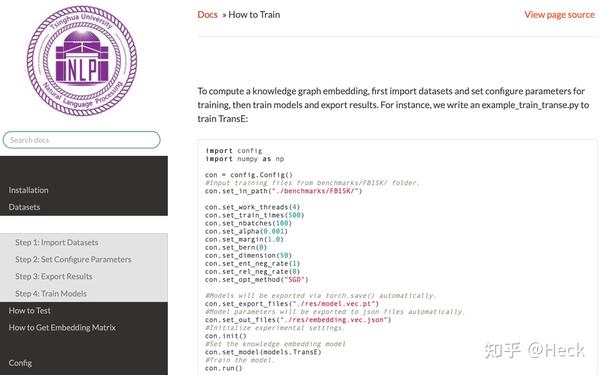
 第二步,利用OpenKE(知识表示学习框架),根据构建的知识图谱为背景,进行知识表示学习。(1)需要将知识图谱转换为三元组和OpenKE所需要的数据格式。(2)选择合适的模型(TransX)进行训练。(3)训练完成后,可以实现将知识图谱中的所有实体和关系转换为低维稠密向量embedding。(4)利用学习到的实体和关系的embedding进行下游任务的实现。
第二步,利用OpenKE(知识表示学习框架),根据构建的知识图谱为背景,进行知识表示学习。(1)需要将知识图谱转换为三元组和OpenKE所需要的数据格式。(2)选择合适的模型(TransX)进行训练。(3)训练完成后,可以实现将知识图谱中的所有实体和关系转换为低维稠密向量embedding。(4)利用学习到的实体和关系的embedding进行下游任务的实现。
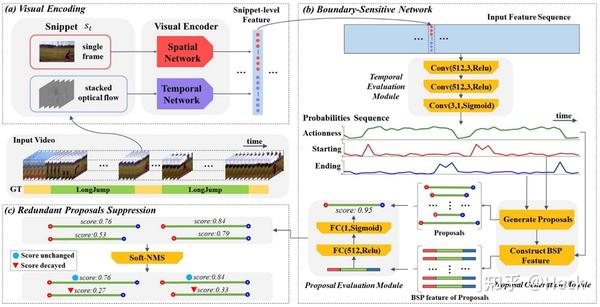
第三步,BSN的提出用来解决一个视频片段中动作开始的位置、结束的位置以及该Snippet是否包含动作。这样可以将所有包含动作片段的视频片段筛选出来。该部分单独依靠视频等时序类数据进行。
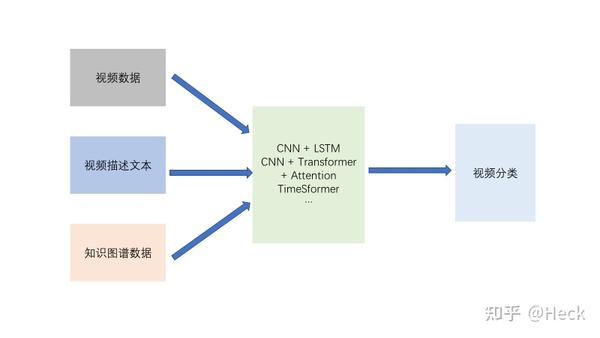
再看我们的最终任务是一个多源数据分类任务,即将通过BSN得到的视频片段进行分类,多源数据包括:1)原始视频数据,2)视频描述/标题(文本数据),3)视频辅助描述数据(知识图谱得到的实体和关系的embeddings),这样利用该视频里面所包含的实体和关系信息辅助实现视频分类。
基于上述三类(多源)数据源特点应用相应的特征工程并将特征融合后输入到神经网络中,实现视频分类:1)特征融合可以使用Concat操作将三者特征进行融合;2)将融合后的特征输入到神经网络中,并通过最后的全链接层实现视频分类,全链接层的输出层为视频类别数,通过softmax激活函数即可判断视频所属类别。
整个任务的关键包括:
1)知识图谱的构建,以知识图谱作为背景知识用于下游视频分类
2) 知识图谱构建时实体的定义问题
3)数据集的构造,视频——>标题——>知识图谱——>分类标签,训练集,验证集,测试集划分
4)BSN和多源视频分类任务类似Pipeline的方式进行,因此一定会存在错误的累积,所以最好是一段视频中包含一段动作,并进行分类
5)数据标注(工程比较大)
6)数据的分析,视频大小,抽取帧的大小,标题的长短,类别的设定
发表回复