
编辑于 2023-01-10 19:00・IP 属地北京
目录
收起
摘要
1. 引言
2. 无人驾驶汽车的决策层综述
A. 路线规划
B. 行为决策
C. 运动规划
D. 车辆控制
3. 规划与控制的建模
A. 单轨(Single-Track)运动学模型
B. 惯性效应
4. 运动规划
A. 路径规划
B. 轨迹规划
C. 变分法
D. 图搜索算法
E. 增量搜索技术
F. 实际部署
5. 车辆控制
A. 基于运动学模型的路径稳定
B. 基于运动学模型的轨迹跟踪控制
C. 预测控制方法
D. 线性变参数控制
6. 结论
7. 参考文献,
本文是2016年的综述论文《A Survey of Motion Planning and Control Techniques for Self-driving Urban Vehicles》的中文稿。该篇文章共3万1千字,最初作为深蓝学院自动驾驶控制与规划在线课程的内部资料,受到同学们的广泛好评,现将其公开,希望帮助更多同行。特别感谢深蓝学院的石卓凡同学(就读于苏黎世联邦理工学院)对论文的翻译及解读。
摘要
自动驾驶汽车是一项成熟的技术,有潜力通过提高汽车运输的安全性、可达性、效率和便捷性来重塑其机动性。必须由自动驾驶车辆执行的安全关键任务包括在与其他车辆和行人共享的动态环境中规划运动,以及通过反馈控制实现鲁棒的执行力。本文的目的是综述城市环境中车辆规划和控制算法的现状。我们将回顾一些公开的技术,并对其有效性进行讨论。根据使用的车辆移动模型、对环境结构的假设以及计算要求,我们分别采用了不同的综述方法。本综述通过并排比较来讨论不同的技术方法,这有助于读者深入了解各种方法的优势和局限性,同时有助于系统级的设计选择。
1. 引言
过去三十年,学术界和工业界对开发无人驾驶汽车技术的研究力度稳步增加。这些发展得益于传感和计算技术的最新进展,以及对汽车运输的潜在变革性影响和已经被见证的社会效益:2014年,32675人因交通事故死亡,230万人受伤,610万人遭遇碰撞事故[1]。其中估计有 94% 的事故是因为驾驶员的错误,例如有 31% 的事故涉及法律上被判定为醉酒的驾驶员,有 10% 的事故涉及驾驶员的分心[2]。
自动驾驶汽车有望大大减少由于驾驶员错误和疏忽而导致的车辆碰撞事故,同时为由于身体或视觉残疾而无法驾驶的人提供个人移动的方式。最后,考虑到 86% 的美国劳动力每天平均需要花费25分钟在驾驶通勤(单程)上[3],自动驾驶汽车将有助于更有效地利用交通时间,或者至少减少驾驶压力带来的可衡量的不良影响[4]。考虑到这项新技术的潜在影响,自动驾驶汽车拥有长久的历史并不奇怪。
早在20世纪20年代,这种想法就已经存在,但是直到20世纪80年代,无人驾驶汽车似乎才真正成为可能。Ernst Dickmanns在20世纪80年代领导的开创性工作(例如[5])为自动驾驶汽车的发展铺平了道路。当时一项大规模的研究(PROMETHEUS项目)被资助于开发一种自动驾驶汽车。1994年,这项工作发布了一个引人注目的演示,其中VaMP无人驾驶汽车行驶了1600公里,并且有 95% 的路程是自动驾驶的[6]。与此同时,卡内基梅隆大学NAVLAB也取得了进展,它于1995年在美国境内完成了5000公里的行驶,其中 98% 的路程是自动驾驶的[7]。
无人驾驶汽车技术的下一个重大里程碑是2004年的第一次DARPA大挑战(DARPA Grand Challenge)。竞赛目标是让无人驾驶汽车在150英里的越野道路上尽可能快速地行驶。与之前的演示相比,这是一个重大挑战,因为在比赛期间没有人为干预。尽管先前的研究工作演示了几乎完全的自动驾驶,但在关键时刻不进行人为干预被证明是一项重大挑战。参加比赛的15辆车中没有一辆完成比赛。
2005年举行了类似的活动,这一次23支车队中有5支到达了终点[8]。后来在2007年,DARPA城市挑战赛(DARPA Urban Challenge)举行,要求车辆在模拟的城市环境中自动驾驶。六支队伍完成了比赛,这证明完全自主的城市驾驶是可能的[9]。自DARPA挑战以来,已经开展了许多活动和大型自动驾驶车辆系统测试。
值得注意的例子包括2009年至2013年的智能汽车未来挑战赛(Intelligent Vehicle Future Challenges)[10]、2010年的现代自动驾驶挑战赛(Hyundai Autonomous Challenge)[11]、2010年的VisLab洲际自动驾驶挑战赛(VisLab Intercontinental Autonomous Challenge)[12]、2013年的公共道路城市无人驾驶汽车测试(Public Road Urban Driverless-Car Test)[13],以及伯莎-奔驰历史路线(Bertha-Benz historic route)的自动驾驶[14]。同时,学术界和工业界的研究都在加速进行。
谷歌的自动驾驶汽车[15]和特斯拉的自动驾驶系统(Autopilot system)[16]是两个商业成果的例子,它们受到了媒体的广泛关注。汽车的自动化程度从完全人工操作到完全自主。SAE J3016标准[17]引入了从0到5的等级,用于对车辆自动化进行分级。在该标准中,0级表示所有驾驶任务均由人类驾驶员负责的车辆。
1级包括基本驾驶辅助,如自适应巡航控制、防抱死制动系统和电子稳定控制[18]。
第2级包括先进的辅助措施,如危险最小化纵向/横向控制[19]或紧急制动[20][21]。这些辅助措施的基础通常是基于集的形式控制理论方法,用来计算可证明的无碰撞(安全)状态的“最坏情况”集[22–24]。
在第3级,系统监控环境,并可以在特定条件下完全自主驾驶,但如果驾驶任务超出自主系统的操作范围,则仍需要操作员进行控制。
具有4级自动化的车辆能够在某些条件下完全自动驾驶,并且如果操作员未能在请求干预时采取控制措施,系统仍然可以安全地控制车辆。
5级系统在所有驾驶模式下都是完全自主的。
车载计算和无线通信技术的可用性使汽车能够与其他汽车和道路基础设施交换信息,从而产生了一个与联网智能汽车密切相关的研究领域[25]。
该研究旨在通过各车辆之间的信息共享和协调,提高道路运输的安全性和性能。例如,联网车辆技术有可能提高交叉路口的吞吐量[26]或防止车流冲击波的形成[27]。为了限制这篇综述的范围,我们将重点放在自动驾驶汽车的决策、运动规划和控制方面,特别是自动化级别为3级及以上的系统。出于同样的原因,这篇综述不讨论自动驾驶的感知领域;读者可以参考许多该方面的综述和最近的主要成果[28–31]。现代自动驾驶系统中的决策通常分为路线规划、行为决策、局部运动规划和反馈控制。
然而,由于文献中报道了决策方案的不同变体,因此这些级别的划分相当模糊。本文概述了为解决自动驾驶核心问题而已经提出的方法,并且将侧重于局部运动规划和控制的方法。
本文的其余部分结构如下:
在第2节中,对决策过程的层次结构及其设计方法进行了高层次的概述。第3节回顾了为了实现运动规划和反馈控制而提出的用于近似城市环境中汽车的机动性的模型。第4节综述了运动规划的大量文献,并讨论了运动规划对自动驾驶汽车的可用性。同样,第5节讨论了无人驾驶汽车的路径和轨迹稳定问题以及具体的反馈控制方法。最后,第6节总结了最新技术和未来研究的潜在领域。
2. 无人驾驶汽车的决策层综述
在本节中,我们将描述典型的自动驾驶汽车的决策层架构,并讨论其中每个组成部分的作用。无人驾驶汽车本质上是一种自主决策系统,它处理来自雷达、激光雷达(LIDARs)、相机、GPS/INS(全球定位系统/惯性导航系统)单元和里程计等车载传感器的观测流。这些观测结果与关于道路网络、道路规则、车辆动力学和传感器模型的先验知识一起,用于自动选择控制车辆运动的受控变量的取值。智能汽车研究旨在尽可能多地实现驾驶任务的自动化。解决这个问题的常用方法是将感知和决策任务划分并组织成一个层次结构。感知系统使用先验信息和收集的观测数据,来提供车辆及其周围环境的状态估计。
决策系统随后使用这些估计来控制车辆,从而实现驾驶目标。典型的自动驾驶汽车的决策系统依据层级分解为四个组成部分(参考图2.1):在最高层,系统通过道路网络规划出一条路线;随后的行为层指定一个局部驾驶任务,使汽车朝着目的地前进同时遵守道路规则;随后,运动规划模块选择一条通过环境的连续路径,以完成局部导航任务;最后,控制系统反应性地修正执行规划运动时的误差。本节的其余部分将更详细地讨论每个组成部分的作用。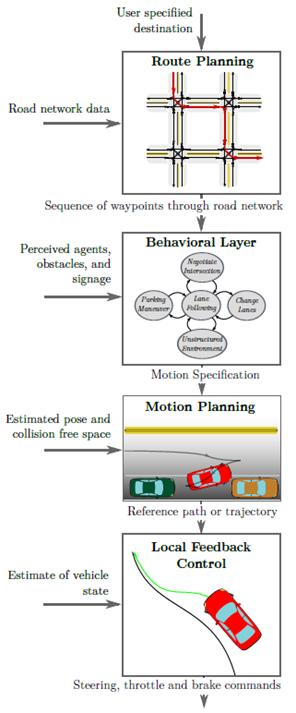
图2.1:决策过程的层级
根据目的地,路线规划器通过道路网络生成一条路线。行为层对环境进行推理,并生成沿着所选路线前进的运动规范。运动规划器随后求解实现规范的可行运动。反馈控制对致动变量进行调参,以修正执行参考路径时的误差。
A. 路线规划在最高层上,车辆的决策系统必须选择一条从当前位置到请求的目的地的、通过道路网络的路线。通过将道路网络表示为一个有向图(有向图的边的权重对应所穿过的道路段的成本),可以将路线规划问题构造为在道路网络图上找到一条最小成本路径的问题。然而,表示道路网络的图可以包含数百万条边,使得经典的最短路径算法(如Dijkstra [32]或A* [33])不再实用。交通网络中的高效路线规划问题引起了交通科学界的极大兴趣,催生了一系列算法。这些算法经过一次性的预处理步骤后,能够在毫秒时间内返回大陆规模的道路网络上的一条最优路线[34][35]。有关可用于高效的人类驾驶和自动驾驶车辆路线规划的实用算法的全面综述和比较,请参考[36]。
B. 行为决策找到一条路线计划后,自动驾驶车辆必须能够根据驾驶惯例和道路规则来导航选定的路线并与其他交通参与者进行交互。当给定了指定所选路线的一系列路段时,行为层基于感知到的其他交通参与者的行为、道路状况和基础设施信号,负责在任何时间点选择适当的驾驶行为。例如,当车辆在交叉路口前到达停车线时,行为层将命令车辆停车,观察交叉路口的其他车辆、自行车和行人的行为,并在轮到车辆行驶时让车辆继续前进。驾驶手册规定了特定驾驶环境下的定性行动。由于驾驶环境和每个环境中可用的行为都可以被建模为有限集,因此自动化这种决策的一种自然方法是将每个行为建模为有限状态机中的状态,其中状态的转移受感知到的驾驶环境的控制,这些驾驶环境包括相对于规划的路线和附近车辆的相对位置。
事实上,在DARPA城市挑战赛中,大多数团队采用了有限状态机和特定于所考虑驾驶场景的不同启发式,作为行为控制的机制[9]。然而,现实世界(尤其是城市环境)的驾驶的特点是,其他交通参与者的意图(intentions)具有不确定性。因此,学界还研究了对其他车辆、自行车和行人的未来轨迹的意图预测和估计。提出的解决方案包括基于机器学习的技术,例如高斯混合模型[37]、高斯过程回归[38]、被报道的在谷歌自动驾驶系统中用于意图预测的学习技术[39],以及用于从传感器测量值中直接估计意图的基于模型的方法[40][41]。其他交通参与者行为的这种不确定性通常在使用概率规划形式(如马尔可夫决策过程(MDPs)及其推广形式)进行决策的行为层中被考虑。例如,文章[42]在MDP框架中构造了行为决策问题。一些工作[43–46]使用部分可观察马尔可夫决策过程(POMDP)框架,以显式地模拟未观察到的驾驶场景和行人意图,并提出了具体的近似解决策略。
C. 运动规划行为层决定的要在当前环境中执行的驾驶行为(例如车道巡航、变道或右转)必须被转换为一条可由低级反馈控制器跟踪的路径或轨迹。生成的路径或轨迹对于车辆必须是动态可行的,同时可以保证乘客的舒适,并避免与车载传感器检测到的障碍物发生碰撞。找到这样的一条路径或轨迹是运动规划系统的工作。自动驾驶车辆的运动规划任务对应于求解机器人文献中讨论的标准运动规划问题。运动规划问题的精确解在大多数情况下都是难以计算的。
因此,实践中通常使用数值近似方法,最流行的包括:(1)变分法,其将问题视为在函数空间中进行非线性优化;(2)图搜索方法,其构造车辆状态空间的图的离散化,并用图搜索算法来搜索最短路径;(3)基于增量树(incremental tree)的方法,其从车辆的初始状态开始,增量地构造一个可到达状态树,并选择树的最佳分支。第4节将更详细地讨论与自动驾驶相关的运动规划方法。
D. 车辆控制为了执行来自运动规划系统的参考路径或轨迹,使用反馈控制器来选择适当的致动器输入。执行规划运动期间会产生跟踪误差的部分原因是车辆模型不够准确。因此,闭环系统的鲁棒性和稳定性受到了极高的重视。当前,已经提出了许多有效的反馈控制器,用于执行由运动规划系统提供的参考运动。第5节详细讨论了相关技术的概况。
3. 规划与控制的建模
在本节中,我们将综述最常用的类车车辆(car-like vehicles)的移动模型。此类模型被广泛用于控制和运动规划算法,来近似在相关操作条件下响应于控制动作的车辆行为。高保真模型可以准确地反映车辆的响应,但增加的细节可能会使规划和控制问题复杂化。这要求在所选模型的准确性和决策问题的难度之间做出权衡。本节将对通用的建模概念进行概述,同时将综述用于运动规划和控制的模型。建模的第一步是车辆构型/配置(configuration)的概念,它表示车辆在世界中的位姿或位置。例如可以用汽车上某一点的平面坐标以及汽车的方向来表示其构型,这便是汽车的构型空间/配置空间(configuration space / C-space)的坐标系。该坐标系描述平面刚体运动(表示为二维的特殊欧氏群 SE(2) ),是常用的构型空间[47-49]。随后,对车辆运动进行规划和控制,以完成驾驶任务,同时必须满足所选模型引入的约束。
A. 单轨(Single-Track)运动学模型实践使用的最基础的汽车模型由两个通过刚性连杆连接的车轮组成,并且被限制在平面内移动[48-52]。该模型假设车轮在其与地面的接触点处不会滑动,但可以绕其旋转轴自由旋转。前轮具有额外的自由度,允许其绕垂直于运动平面的轴旋转,以模拟转向。这两个建模特征反映了大多数乘客的体验,即汽车无法在不向前移动的同时实现横向位移。更正式地,这种机动性限制被称为非完整约束[47][53]。非完整约束表示为汽车运动的微分约束,约束的表达式随坐标系的选择而变化。这种汽车模型的变体被称为类车机器人、自行车模型、运动学模型或单轨模型。接下来我们将推导这种构型在几种常用坐标系中的微分约束。
参考图3.1,向量 p_r 和 p_f 分别表示静止坐标系或惯性坐标系中后轮和前轮的位置,坐标系由三个基向量 left(hat{e}_x, hat{e}_y, hat{e}_zright) 所决定。航向 theta 是描述车辆朝向的角度,定义为向量 hat{e}_x 和 p_f-p_r 的夹角。一个坐标系下的微分约束的表达式包括该坐标系下的角度 theta 以及车辆上一点的运动,如向量 p_r(参考[54])或 p_f(参考[55])。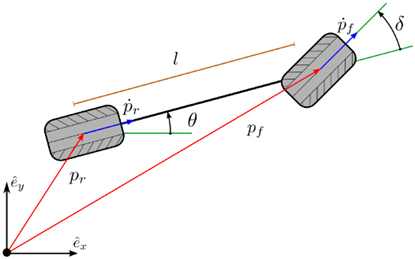
图3.1:单轨模型的运动学
图3.1:单轨模型的运动学,其中 p_r 和 p_f分别是后轮和前轮与地面的接触点, theta 是车辆航向, delta 是前轮的转向角。由于非完整约束,p_r 和 p_f 的时间导数被限制在蓝色箭头指示的方向上。点p_r 和 p_f 的运动必须与车轮的朝向共线,以满足无滑移假设。
对于后轮的该约束可以表示为left(dot{p}_r cdot hat{e}_yright) cos theta-left(dot{p}_r cdot hat{e}_xright) sin theta=0 (3.1)
对于前轮的该约束可以表示为left(dot{p}_f cdot hat{e}_yright) cos (theta+delta)-left(dot{p}_f cdot hat{e}_xright) sin (theta+delta)=0 (3.2)
利用每个点沿基向量的运动分量,可以重写上式。
后轮沿 hat{e}_x 方向的运动可以写作 x_r:=p_r cdot hat{e}_x ,相似地,沿hat{e}_y 方向的运动写作 y_r:=p_r cdot hat{e}_y 。前向速度 v_r:=dot{p}_r cdotleft(p_f-p_rright) /left|left(p_f-p_rright)right| ,表示 dot{p}_r 的大小,同时带有正确的正负号,该正负号用于描述当前的行驶是正向或反向驾驶。利用 x_r, y_r, theta 这几个标量,微分约束可以写作begin{aligned} dot{x}_r =v_r cos theta \ dot{y}_r =v_r sin theta \ dot{theta} =frac{v_r}{l} tan delta end{aligned} (3.3)
类似地,也可以利用 p_f 的运动将微分约束写作begin{aligned} &dot{x}_f=v_f cos (theta+delta) \ &dot{y}_f=v_f sin (theta+delta) \ &dot{theta}=frac{v_f}{l} sin delta end{aligned} (3.4)
其中 v_f 是前轮的前向速度,它与后轮速度 v_r 满足关系frac{v_r}{v_f}=cos delta (3.5)利用这个模型求解规划和控制问题涉及在车辆的机械限制范围内选择转向角 delta inleft[delta_{min }, delta_{max }right] ,以及在合适的范围内选择前向速度 v_r inleft[v_{min }, v_{max }right] 。
一种经常采用的简化方式是选择一个航向率 omega 而非选择一个转向角 delta 。这些变量满足关系delta=arctan frac{l omega}{v_r} (3.6)并随之得以将转向动力学简化为dot{theta}=omega, quad omega inleft[frac{v_r}{l} tan delta_{min }, frac{v_r}{l} tan delta_{max }right] (3.7)
此时的模型经常被称为单轮(unicycle)模型,因为它的推导相当于只考虑了一个轮子的运动。该模型的一个重要变体是 v_r 固定时的情况,此时的模型又被称为Dubins车(Dubins Car),以纪念Lester Dubins推导出了具有指定切线的两点之间的最小时间运动[57]。另一个值得注意的变体是Reeds-Shepp车,此时对于最短路径的求解允许 v_r 是正向或者反向行驶的速度[58]。这两种模型已被证明对运动规划具有一定的重要性,因此将在第四节中作进一步讨论。运动学模型适用于低速(例如泊车和城市驾驶)下的路径规划。在这些低速行驶的场景中,相比于无滑移假设对移动性的限制,惯性效应较小。该模型的主要缺点是它允许瞬时的转向角变化:如果运动规划模块生成具有这种瞬时变化的解,可能将带来很多麻烦。转向角的连续性可以通过增强方程(3.4)来实现,其中转向角被处理为指定速率的积分,参考[49]。
方程(3.4)进而变为begin{aligned} &dot{x}_f=v_f cos (theta+delta) \ &dot{y}_f=v_f sin (theta+delta) \ &dot{theta}=frac{v_f}{l} sin delta \ & dot{delta}=v_delta end{aligned} (3.8)
此时除了限制转向角,还要约束转向率 v_delta inleft[dot{delta}_{min }, dot{delta}_{max }right] 。同样的问题也可能发生在车速 v_r上,但可以通过与转向角相同的方式来解决。这种方法的缺点是增加了模型的维度,使得运动规划与控制问题被复杂化了。 坐标系的选择并不限定必须选择一个轮子的位置作为车辆的位置坐标。对于通过经典力学原理推导得到的模型,使用质心作为位置坐标可能更加方便,参考[59][60],或者使用摆心,参考[61][62]。B. 惯性效应当车辆的加速度足够大时,轮胎与地面之间的无滑移假设不再成立。此时,一个更加准确的模型是将车辆视为一个满足动量定理的刚体,即,加速度正比于地面施加在轮胎上的力。
取 p_c 作为车辆的质心以及构型坐标(参考图3.2),车辆的运动服从以下关系begin{aligned} &m ddot{p}_c=F_f+F_r \ & I_{z z} ddot{theta}=left(p_c-p_fright) times F_f+left(p_c-p_rright) times F_r end{aligned} (3.9)
其中 F_r 和 F_f 是地面通过与轮胎的接触而施加于车辆的力,m 是车辆的总质量, I_{Z Z} 是在 hat{e}_z 方向上关于质心的极惯性矩。在接下来的推导中,我们将基于平坦地面、刚体悬架以及车辆保持在道路上的假设,默认忽略 p_c在hat{e}_z方向上的运动。
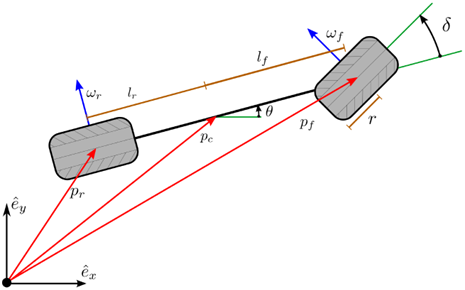
图3.2:没有无滑移假设的单轨模型的运动学图解其中 omega_{{r, f}} 是车轮相对于车辆的相对角速度(relative angular velocities)。F_r 和 F_f 的表达式随建模假设[18][59][60][62]而变化,但在任何情况下,推导该表达式都可能很繁琐。因此,方程(3.10)-(3.15)提供了详细的推导作为参考。地面与轮胎之间的力被建模为与轮胎在地面上滑动的速率有关。
尽管选择质心作为构型的坐标,但仍然需要每个车轮相对于地面的速度,以确定该相对速度。这三个点之间的运动学关系为begin{aligned} &p_r=p_c+left(begin{array}{c} -l_r cos theta \ -l_r sin theta \ 0 end{array}right) \ & dot{p}_r=dot{p}_c+left(begin{array}{c} 0 \ 0 \ & dot{theta} end{array}right) timesleft(begin{array}{c} -l_r cos theta \ -l_r sin theta \ 0 end{array}right) \ &p_f=p_c+left(begin{array}{c} l_f cos theta \ l_f sin theta \ 0 end{array}right) \ &dot{p}_f=dot{p}_c+left(begin{array}{c} 0 \ 0 \ dot{theta} end{array}right) timesleft(begin{array}{c} l_f cos theta \ l_f sin theta \ 0 end{array}right) end{aligned} (3.10)
这些运动学关系用于确定每个轮胎与地面的接触点的速度 s_r 和 s_f 。这些点的速度又被称为轮胎滑动速度。通常,由于存在轮胎的角速度,因此s_r 和 s_f不同于 dot{p}_r 和 dot{p}_f 。它们之间的运动学关系如下:begin{aligned} & s_r=dot{p}_r+omega_r times R \ & s_f=dot{p}_f+omega_f times R end{aligned} (3.11)
其中车轮的角速度由下式给出:omega_r=left(begin{array}{c} Omega_r sin theta \ -Omega_r cos theta \ 0 end{array}right), quad omega_f=left(begin{array}{c} Omega_f sin (theta+delta) \ -Omega_f cos (theta+delta) \ 0 end{array}right) (3.12)且 R=(0,0,-r)^T 。
车轮半径用标量 r 表示,每个轮胎相对于汽车的角速率用 Omega_{{r, f}} 表示。图3.3描绘了后轮上的各个变量之间的关系。
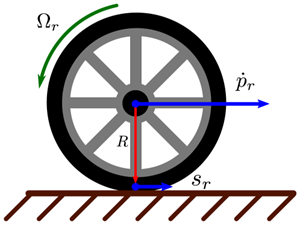
图3.3:二维的后轮运动学图解
图3.3:二维的后轮运动学图解表明了车轮滑移 S_r 与后轮速度 dot{p}_r 以及角速率(angular speed)Omega_r 均存在关联。通常, S_r和 dot{p}_r不共线,并且可能在垂直于所示平面的方向上具有非零分量。 在静态条件下,或者当质心的高度可以近似满足 p_c cdot hat{e}_z approx 0 时,地面施加给轮胎的力在垂直于地面的方向上的分量 F_{{r, f}} cdot hat{e}_Z 可以通过静力学的力矩平衡而给出:F_f cdot hat{e}_z=frac{l_r m g}{l_f+l_r}, quad F_r cdot hat{e}_z=frac{l_f m g}{l_f+l_r} (3.13)法向力随后同滑移以及一个描述轮胎特性的摩擦系数模型 mu 一起,用于计算每个轮胎上的牵引力。
后轮上的牵引力的分量给出如下:
begin{aligned} & F_r cdot hat{e}_x=-frac{left(F_r cdot hat{e}_zright) muleft(frac{left|s_rright|}{Omega_r r}right) s_r}{left|s_rright|} cdot hat{e}_x \ & F_r cdot hat{e}_y=-frac{left(F_r cdot hat{e}_zright) muleft(frac{left|s_rright|}{Omega_r r}right) s_r}{left|s_rright|} cdot hat{e}_y end{aligned} (3.14)
将上式中的下标r 替换为 f ,就可以得到前轮上的牵引力的表达式。上式将牵引力建模为反向平行于滑移,且其大小正比于法向力,同时与滑移率非线性相关(滑移率由滑移经过后轮的 Omega_r r 或前轮的 Omega_f r 的归一化而给出)。结合公式(3.10)-(3.15),可以得到关于控制变量、广义坐标以及轮胎速度的每个车轮上的合力的表达式。将方程(3.14)以及如下有关 mu 的模型结合起来,是一种常用的、处理车轮和地面接触的情况的模型。方程(3.15)是Pacejka提出的知名模型的一种简化版本。
muleft(frac{left|s_rright|}{Omega_r r}right)=D sin left(C arctan left(B frac{left|s_rright|}{Omega_r r}right)right) (3.15)
方程(3.14)的旋转对称性以及方程(3.15)存在的峰值将导致轮胎产生一个能在任何方向上施加的范数最大的力。该峰值又被称为摩擦圆(friction circle),如图3.4所示。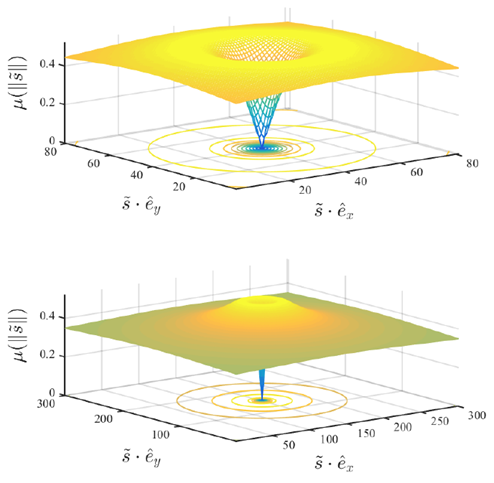
图3.4
图3.4:顶部的图是放大视图,其描绘了每个轮胎上的车轮滑移到牵引力的映射;底部的图是缩小视图,其重点描绘了定义摩擦圈的峰值。参考方程(3.15)。本节讨论的模型经常出现在无人驾驶汽车的运动规划和控制的文献中。这些模型适用于本综述所讨论的运动规划和控制任务。然而,诸如电子稳定控制和主动悬架系统等较低级别的控制任务通常使用更复杂的模型来对底盘、转向和传动系统进行建模。
4. 运动规划根据决策层的行为层给出的目标构型,运动规划层负责计算出一条从车辆的当前构型到目标构型的安全、舒适且动力学可行的轨迹。在不同的情境中,目标构型可能有所不同。例如,目标位置可能是行驶方向上前方数米处的当前车道的中心点、下一个十字路口处的停车线的中心或者下一个期望的泊车点。运动规划组件接受关于车辆周围的静态和动态障碍物的信息,并生成满足车辆运动的动力学和运动学约束的无碰撞轨迹。通常,运动规划器最小化一个给定的目标函数。除了行程时间外,目标函数还可能包含有关危险运动或导致乘客不适的运动的惩罚项。在典型的设置中,运动规划器的输出传递给局部反馈控制层。反馈控制器随后产生一个输入信号以控制车辆跟随这个给定的运动计划。车辆的运动计划可能是路径形式或轨迹形式。
在路径规划的框架内,解路径表示为函数 sigma(alpha):[0,1] rightarrow mathcal{X} ,其中 chi 是车辆的构型空间。注意这种解并未规定应该如何跟随该路径,因此跟随的方案可以是选择路径的速度分布,或者是将该任务移交决策层中的低级层。而轨迹规划的框架明确考虑到了控制执行时间,因此可以对车辆动力学和动态障碍物进行直接建模。在这种情况下,解轨迹表示为一个时间参数化的函数 pi(t):[0, T] rightarrow mathcal{X} ,其中 T 是规划范围/区间。与路径不同,轨迹规定了车辆的构型如何随时间变化。
在接下来的两节中,我们将对路径规划和轨迹规划问题进行正式的定义,并综述这两种问题形式的主要复杂度和算法结果。
A. 路径规划路径规划问题是在车辆(或者更一般地说,机器人)的构型空间 chi 中寻找一条从初始构型到目标区域的路径 sigma(alpha):[0,1] rightarrow mathcal{X} ,同时满足给定的全局和局部约束。根据是否考虑解路径的质量,分别用术语“可行(feasible)”和“最优(optimal)”来描述该路径。
可行路径规划是指在不关注解的质量的情况下,确定一条满足某些给定问题约束的路径的问题;而最优路径规划是指在给定约束条件下找到一条优化某个质量标准的路径的问题。最优路径规划问题的一种正式表述如下。
设 chi 是车辆的构型空间,设 sum(mathcal{X}) 表示所有连续函数 [0,1] rightarrow mathcal{X} 的集合;车辆的初始构型为 mathbf{x}_{text {init }} in mathcal{X} ;路径需要在目标区域 X_{text {goal }} subseteq mathcal{X} 内结束。车辆的所有允许的构型的集合称为自由构型空间/自由配置空间,记为 chi_{text {free }} 。
通常,自由构型是那些不会导致与障碍物发生碰撞的构型,但自由构型集也可以表示路径上的其他完整约束。路径上的微分约束由谓词 Dleft(mathrm{x}, mathrm{x}^{prime}, mathrm{x}^{prime prime}, ldotsright) 表示,并且可以用于强制车辆实现一定程度的路径平滑度,例如路径曲率的界限以及/或者曲率变化率。
例如,在 mathcal{X} subseteq mathbb{R}^2 的情况下,微分约束可以使用如下的Frenet-Serret公式来限制路径的最大曲率
kappa :Dleft(mathrm{x}, mathrm{x}^{prime}, mathrm{x}^{prime prime}, ldotsright) Leftrightarrow frac{left|mathrm{x}^{prime} times mathrm{x}^{prime prime}right|}{left|mathrm{x}^{prime}right|^3} leq kappa
如果再进一步地设
J(sigma): sum(mathcal{X}) rightarrow mathbb{R} 为成本泛函,那么最优路径规划问题可以一般地表示如下:
问题 4.1 最优路径规划给定一个五元组 left(mathcal{X}_{text {free }}, mathrm{x}_{text {init }}, X_{text {goal }}, D, Jright) ,找到 sigma^*=arg min _{sigma in sum(X)} J(sigma)
约束条件:begin{aligned} &sigma(0)=mathrm{x}_{text {init }}, quad sigma(1) in X_{text {goal }} \ &sigma(alpha) in mathcal{X}_{text {free }}, quad forall alpha in[0,1] \ & Dleft(sigma(alpha), sigma^{prime}(alpha), sigma^{prime prime}(alpha), ldotsright), quad forall alpha in[0,1] end{aligned}
可行和最优路径规划问题在过去几十年中得到了广泛的研究。此问题的复杂度已经被很好地理解,并且已经开发了许多实用的算法。
复杂度:大量文献致力于研究运动规划问题的复杂度。接下来本文将综述关于这些问题的计算复杂度的一些主要结果。
问题4.1陈述了在完整和微分约束下找到一条最优路径的问题,后者被认为是PSPACE困难的(PSPACE-hard)[64]。这意味着该问题至少与解决任何NP完全问题一样困难。因此,如果假设 mathrm{P} neq mathrm{NP} ,那么就不存在有效的(多项式时间的)算法能够解决此问题的所有实例。因此,研究者此后便将注意力集中在研究近似方法,或研究一般路径规划问题的子集的方法上。
最初的研究主要集中于在多边形/多面体环境中的完整(holonomic)车辆模型的可行(非最优)路径规划。即,假设障碍物是多边形/多面体,且假设在生成的路径上没有微分约束。
1970年,Reif发现,在二维和三维环境中,可以在多项式时间内找到完整车辆的无障碍路径,其足迹可以描述为单个多面体[64]。Canny已经证明,使用多项式表示的自由空间中的可行路径规划问题是PSPACE问题,因此,没有微分约束的可行路径规划的决策问题是PSPACE完全问题[65]。
最优路径规划问题的目标是找到一条最短的无障碍路径。学界很早就意识到,可以在多项式时间内找到完整车辆在具有多边形障碍物的二维环境中的最短路径[66][67]。更准确地说,可以在 Oleft(n^2right) 时间内计算得到,其中 n 是多边形障碍物的顶点数[68]。
求解的方法可以是构造和搜索所谓的“可见图(visibility graph)”[69]。相对地,Lazard、Reif和Wang发现,在多边形障碍物中找到二维平面上的曲率有界的最短路径(即类车机器人的路径)的问题是NP难题[70],这表明没有已知的多项式时间算法可以在多边形障碍中找到类车机器人的最短路径。相关的研究成果是,可以在指数时间(EXPTIME)内确定一条在多边形环境中的存在曲率约束的路径[71]。一种能够有效计算解的特殊情况是无障碍环境中的曲率有界的最短路径。
Dubins已经证明[57],给定两个点 p_1, p_2 ,并且给定两个点处的切线 theta_1, theta_2 ,则两点之间的、限制最大曲率 k 的最短路径是一条由最多三个段组成的曲线,每个段是圆弧段或直线。Reeds和Shepp将该方法扩展到能够前后移动的汽车上[58]。
Agraval等人[72]提出的另一种值得注意的情况是 Oleft(n^2 log nright) 算法,其用于在凸多边形内找到一条曲率有界的最短路径。
类似地,Boissonnat和Lazard提出了一种多项式时间算法[73],用于在一种特定的环境中找到一条精确的曲率有界的路径,这种环境中的障碍物的边界都具有有界曲率。由于自动驾驶中受到关注的大多数问题都不存在具有实用的计算复杂度的精确算法[70],因此必须转向更一般的数值求解方法。这些方法通常不会找到一个精确的解,而是试图找到一个满意的解或一系列收敛到最优解的可行解。
这些方法的效用和性能通常通过它们适用的问题类别以及它们是否能保证收敛到最优解来量化。路径规划的数值方法可以大致分为三大类:
(1)变分法(Variational methods)。其将路径表示为一个由有限维向量参数化的函数,并通过非线性连续优化技术对向量参数进行优化,以寻找最优路径。由于能快速收敛到局部最优解,因此备受关注;然而,除非提供一个适当的初始猜测,否则变分法通常难以找到全局最优解。有关变分法的详细讨论,请见第4-C节。
(2)图搜索方法(Graph-search methods)。其将车辆的构型空间离散化为一个图。图的顶点表示车辆构型的有限集合,图的边表示顶点之间的转移。该方法通过在这样的图中搜索一条最小成本路径,来找到期望的路径。图搜索方法不容易陷入局部极小值,但是它们仅限于在有限的路径集上进行优化,这种路径集包含的路径都可以由图中的运动基元(motion primitives)构建得到。有关图搜索方法的详细讨论,请见第4-D节。
(3)增量搜索方法(Incremental search methods)。其对构型空间进行采样,并逐步构造一个可达图(通常是树)。可达图(reachability graph)包含可达构型的一个离散集合以及可达构型之间的可行转移。一旦图已经构造得足够大,使得至少存在一个节点位于目标区域中,则算法通过跟踪从起始构型出发的、最终指向该节点的边,来获得期望路径。相比更基本的图搜索方法,基于采样的方法逐渐增加图的大小,直到在图中找到满意的解。有关增量搜索方法的详细讨论,请见第4-E节。
显然,通过将这些方法结合起来,我们有望充分利用每种方法的优点。例如,可以使用粗略的图搜索来获得[74]和[75]中报告的变分法的初始猜测。表1中给出了路径规划方法的关键性质的比较。本节的剩余部分将详细讨论路径规划算法以及它们的性质。
B. 轨迹规划动态环境的或具有动力学约束的运动规划问题可能更适合表述于轨迹规划的框架中,其中问题的解是一条轨迹,即时间参数化函数 pi(t):[0, T] rightarrow mathcal{X} ,其规定了车辆构型随时间的变化。
记 Pi(x, T) 为所有连续函数 [0, T] rightarrow mathcal{X} 的集合,同时记 x_{text {init }} in mathcal{X} 为车辆的初始构型。目标区域是 X_{text {goal }} subseteq mathcal{X} 。
在时间 t in[0, T] 内的所有允许构型的集合记为 x_{text {free }}(t) ,并被用于编码完整约束,例如路径上的避免与静态以及可能的动态障碍物发生碰撞的要求。轨迹上的微分约束表示为谓词 Dleft(mathrm{x}, mathrm{x}^{prime}, mathrm{x}^{prime prime}, ldotsright) ,并可用于对轨迹施加动力学约束。此外,再设 J(pi): Pi(mathcal{X}, T) rightarrow mathbb{R} 为成本泛函。
在这些假设下,最优轨迹规划问题可以非常一般地表述为:
问题 4.2 最优轨迹规划给定一个六元组 left(X_{text {free }}, mathrm{x}_{text {init }}, X_{text {goal }}, D, J, Tright) ,找到 pi^*=arg min _{pi in Pi(X, T)} J(pi)
约束条件:begin{aligned} &pi(0)=mathrm{x}_{text {init }}, quad pi(T) in X_{text {goal }} \ &pi(t) in X_{text {free }}, quad forall t in[0, T] \ &Dleft(pi(t), pi^{prime}(t), pi^{prime prime}(t), ldotsright), quad forall t in[0, T] end{aligned}
复杂度:由于动态环境的轨迹规划是静态环境的路径规划的推广,因此问题仍然是PSPACE困难的。此外,动态环境的轨迹规划已被证明比路径规划更难,因为当在动态环境中考虑一个类比问题时,在静态环境中易于处理的问题的某些变量会变得难以处理。
典型地,回想一下,在静态的二维多边形环境中的点机器人的最短路径可以在多项式时间内被有效地找到;与此相对,Canny和Reif的结果[76]表明,在移动的多边形障碍物[1]中找到完整点机器人的一条速度有界的无碰撞轨迹是NP困难的。类似地,尽管在三维多面体环境中对具有固定自由度的机器人进行路径规划是容易的,但是Reif和Sharir指出,在平移和旋转三维多面体障碍物中对具有2个自由度的机器人进行轨迹规划是PSPACE困难的[85]。对于自动驾驶中出现的关键轨迹规划问题,不存在易于处理的精确算法,这使得数值方法成为处于该任务的流行选择。轨迹规划问题的求解可以是直接在时域中使用一些变分方法,或者是将轨迹规划问题转换为附加了时间维度的构型空间中的路径规划问题[86]。
轨迹规划问题 left(X_{text {free }}^T, mathrm{x}_{text {init }}^T, X_{text {goal }}^T, D^T, J^T, Tright) 到路径规划问题 left(X_{text {free }}^P, x_{text {init }}^P, X_{text {goal }}^P, D^P, J^Pright) 的转化通常实现如下。定义 X^P:=X^T times[0, T] 为进行路径规划的构型空间。
对于任意 y in mathcal{X}^P ,记 t(mathrm{y}) in[0, T] 为时间分量,记 c(mathrm{y}) in mathcal{X}^T 为点 y 的“构型/配置”分量。
对于一条路径 sigma(alpha):[0,1] rightarrow mathcal{X}^P 以及一条轨迹 pi(t):[0, T] rightarrow mathcal{X}^T ,如果该路径在起点和终点处的时间分量满足begin{aligned} & t(sigma(0))=0 \ & t(sigma(1))=T end{aligned}
并且这条路径是单调递增的,即可以表示为微分约束tleft(sigma^{prime}(alpha)right)>0, quad forall alpha in[0,1]
那么这条路径 sigma(alpha) 就能被转化为这条轨迹 pi(t) 。
再进一步地说,自由构型空间、初始构型、目标区域以及微分约束以如下的形式被映射到路径规划中:begin{aligned} & x_{text {free }}^P=left{(x, t): x in X_{text {free }}^T(t) wedge t in[0, T]right} \ & mathrm{x}_{text {init }}^P=left(mathrm{x}_{text {init }}^T, 0right) \ & X_{text {goal }}^P=left{(x, T): x in X_{text {goal }}^Tright} \ &D^Pleft(mathrm{y}, mathrm{y}^{prime}, mathrm{y}^{prime prime}, ldotsright)=D^Tleft(c(mathrm{y}), frac{cleft(mathrm{y}^{prime}right)}{tleft(mathrm{y}^{prime}right)}, frac{cleft(mathrm{y}^{prime prime}right)}{tleft(mathrm{y}^{prime prime}right)}, ldotsright) end{aligned}
随后,可以利用一个能够处理微分约束的路径规划算法来得到该路径规划问题的解,最终将其转换回轨迹的形式。
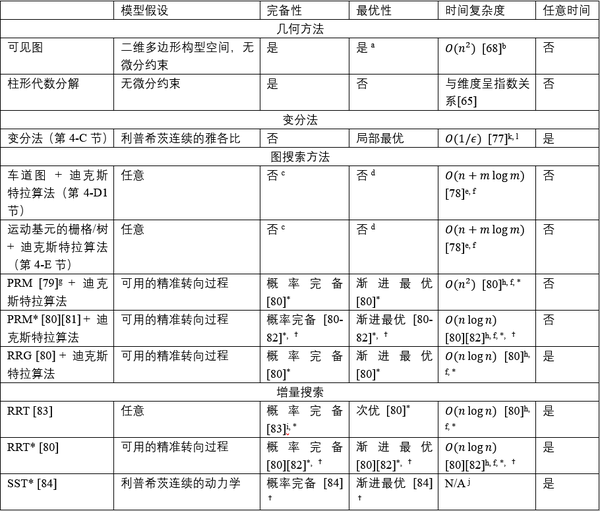 表1:不同路径规划方法的比较说明: a: 最短路径问题; b:n 是用于定义障碍物的点的个数; c: 完备(complete)的概念是仅对于给定的图所产生的路径集而言的; d: 最优的概念是仅对于给定的图所产生的路径集而言的; e: n 和 m 分别是图中边和顶点的数量; f: 假设碰撞检测的时间复杂度为 O(1) ; g: 具有固定半径的连接策略的批版本; h:n 是采样点的数量或算法的迭代次数; i: 对于算法的某些变体而言; j: 未被明确分析; k: ϵ 是距离最佳成本的所需距离; l: 在额外假设的情况下,可能具有更快的速率; *: 对于不具有微分约束的系统,已被证明成立; ✝: 对于某些类别的非完整系统,已被证明成立。
表1:不同路径规划方法的比较说明: a: 最短路径问题; b:n 是用于定义障碍物的点的个数; c: 完备(complete)的概念是仅对于给定的图所产生的路径集而言的; d: 最优的概念是仅对于给定的图所产生的路径集而言的; e: n 和 m 分别是图中边和顶点的数量; f: 假设碰撞检测的时间复杂度为 O(1) ; g: 具有固定半径的连接策略的批版本; h:n 是采样点的数量或算法的迭代次数; i: 对于算法的某些变体而言; j: 未被明确分析; k: ϵ 是距离最佳成本的所需距离; l: 在额外假设的情况下,可能具有更快的速率; *: 对于不具有微分约束的系统,已被证明成立; ✝: 对于某些类别的非完整系统,已被证明成立。
C. 变分法
我们将首先在非线性连续优化的框架下解决轨迹规划问题。在这种情况下,该问题通常被称为轨迹优化。在本小节中,我们将采用轨迹规划的形式——注意这种做法并不会影响一般性,因为路径规划可以表示为单位时间间隔内的轨迹优化。为了利用现有的非线性优化方法,有必要将轨迹的无限维函数空间投影到一个有限维向量空间。
此外,大多数非线性规划技术要求将问题4.2形式的轨迹优化问题转化为如下形式arg min _{pi in Pi(x, T)} J(pi)
约束条件:begin{aligned} &pi(0)=mathrm{x}_{text {init }}, pi(T) in X_{g o a l} \ &fleft(pi(t), pi^{prime}(t), ldotsright)=0, forall t in[0, T] \ &gleft(pi(t), pi^{prime}(t), ldotsright) leq 0, forall t in[0, T] end{aligned}
其中完整约束和微分约束被表示为系统的等式约束和不等式约束。一些应用场景通过使用惩罚函数或障碍函数,将带约束的优化问题放松为无约束的优化问题。无论是使用惩罚函数还是障碍函数,都是利用一个增强的成本泛函代替约束。
使用惩罚方法时,成本泛函的形式如下tilde{J}(pi)=J(pi)+frac{1}{epsilon} int_0^Tleft[left|fleft(pi, pi^{prime}, ldotsright)right|^2+left|max left(0, gleft(pi, pi^{prime}, ldotsright)right)right|^2right] d t
类似地,障碍函数可以用于替代不等式约束。此时的增强成本泛函的形式为tilde{J}(pi)=J(pi)+epsilon int_0^T h(pi(t)) d t
其中障碍函数满足 g(pi)<0 Longrightarrow h(pi)
图4.1:手工绘制的图,表示正常情况下的期望行驶路径。尽管大多数时候让自动驾驶汽车沿着道路车道图中编码的路径行驶就足够了,但是有时它必须能在设计道路网络图时未考虑的障碍物周围导航,或者能在图中未涵盖的环境中导航。例如,考虑一辆故障车辆阻塞了我们的车辆计划穿过的车道——在这种情况下,必须使用更一般的运动规划方法,以找到被检测到的障碍物周围的一条无碰撞路径。根据环境中障碍物的表示方法,可以将一般的路径规划方法大致分为两类。所谓的几何或组合方法适用于障碍物的几何表示——在实践中,障碍物最常用多边形或多面体来描述。另一方面,所谓的基于采样的方法抽象了障碍物的内部表示方式,并且仅假设对于一个函数的访问,该函数用于确定任何给定的路径段是否与任何障碍物发生了碰撞。
2) 几何方法在本节中,我们将重点介绍使用障碍物几何表示的路径规划方法。我们将首先关注无微分约束的路径规划,因为对于此情况,存在有效的精确路径规划算法。尽管由于无法考虑对最小转弯半径的约束,因此无法强制地施加微分约束,进而对传统转向车辆的路径规划产生了限制,但是这些方法可用于求解具有曲率约束的路径的长度下限和上限[1],并且还可用于能够原地转弯的、更特殊的车辆结构的路径规划。
在路径规划中,术语“路线图(roadmap)”用于描述 mathcal{X}_{text {free }}的图离散化。这种离散化能够很好地描述自由构型空间的连通性,并且 mathcal{X}_{text {free }}中的任意点都可以从路线图的某些顶点出发而轻松到达。当集合 mathcal{X}_{text {free }}可以通过线性或半代数模型被几何形式地描述时,我们能在算法上构造用于 mathcal{X}_{text {free }}的不同类型的路线图,进而将其用于获得完备的路径规划算法。
最值得注意的是,对于 mathcal{X}_{text {free }} subset mathbb{R}^2 和构型空间的多边形模型,存在几种用于构造这种路线图的有效算法,如垂直单元分解(vertical cell decomposition)[93]、广义冯洛诺伊图(generalized Voronoi diagrams)[94][95]和可见图[33][96]。
对于由一般半代数模型描述的高维构型空间,一种称为柱形代数分解(cylindrical algebraic decomposition)的技术可用于在构型空间中构造路线图[47][97],从而为非常一般的路径规划问题提供完备的算法。这类算法中最快的是Canny开发的算法[65],其在构型空间的维度上具有(单个)指数时间的复杂度。然而,其结论主要是理论性质的,迄今为止没有任何已知的实现。对于具有最大曲率约束的运动规划问题,目前也存在一些研究成果,这是因为该问题与类车车辆的运动规划存在关联。
Backer和Kirkpatrick提出了一种算法[98],用于构造一条具有有界曲率的多项式路径,且该多项式是相对于以下变量而言的:域的特征的数量、输入的精度、连接特定构型的最简单的无障碍Dubins路径上的路径段个数。由于在多边形障碍物中找到一条具有有界曲率的最短路径的问题是NP困难的,因此目前并不存在精确的多项式解算法。
Jacobs和Canny首先提出了一种在多边形障碍物中寻找曲率有界的最短路径的近似算法[99],后来Wang和Agarwal进行了改进[100],改进后的算法的时间复杂度为 Oleft(frac{n^2}{epsilon^4} log nright) ,其中 n 是障碍物的顶点数, epsilon 是近似因子。所谓的中等障碍物(moderate obstacles)具有光滑的边界,且边界的曲率大小以 k 为界。在这种中等障碍物的特殊情况下,Boissonnat和Lazard开发了一种精确的多项式算法,以找到曲率最大以 k 为界的一条路径[73]。
3) 基于采样的方法 在自动驾驶中, mathcal{X}_{text {free }}的几何模型通常不是直接可用的,而通过原始传感数据构造模型的成本又太高。此外,对生成路径的要求通常比简单的最大曲率约束更复杂。这可以解释基于采样的方法的流行,因为后者并未强制对自由构型集和动力学约束采用特定的表示方法。基于采样的方法不是通过几何表示进行推理,而是使用转向/引导(steering)和碰撞检测(collision checking)的推理方式来探索自由构型空间的可达性: 转向/引导函数 text { steer }(mathrm{x}, mathrm{y}) 返回一条从构型 x 出发、朝向构型 y(但是不必须要到达 y)的路径段,并确保满足微分约束,即,生成的运动对于所考虑的车辆模型是可行的。转向函数的具体实现方式取决于其所处的环境。
文献中报告过的一些典型选择包括:
1) 随机转向(Random steering):转向函数返回的路径是在状态x时,将一个随机控制输入应用到车辆的前向模型、并经过一个固定或可变时间步长而得到的[101]。
2) 启发式转向(Heuristic steering):转向函数返回的路径是应用一个启发式构造的控制而得到的,这类启发式的构造方法用于引导系统从 x 朝向 y [102-104],包括从预先设计的离散策略集合(库)中选择一个策略。
3) 精确转向(Exact steering):转向函数返回一条用于引导系统从 x 到 y 的可行路径。这样一条路径对应一个两点边值问题的一个解。对于一些系统和成本泛函,可以解析地求出这样的路径,例如完整系统的一条直线、前向移动的单轮车的一条Dubins曲线[57]、或双向单轮车[58]的一条Reeds-Shepp曲线。微分平坦(differentially flat)系统同样存在解析解[61],而对于更复杂的模型,可以通过求解两点边值问题来获得精确的转向解。
4) 最优精确转向(Optimal exact steering):转向函数返回相对于给定的成本泛函的一条最优精确转向路径。事实上,若假设成本泛函是路径的弧长[57][58],则上一段提到的直线、Dubins曲线和Reeds-Shepp曲线都是最优解。如果路径段 sigma 完全处于 mathcal{X}_{text {free }}中,那么碰撞检测函数 operatorname{col} text {-free }(sigma) 将返回真值(即true),用于确保生成的路径不会与任何障碍物发生碰撞。
具备了转向函数和碰撞检测函数之后,主要的挑战就是如何构造一个能很好地近似 mathcal{X}_{text {free }}的连接性的离散化,而不需要拥有其几何结构的显式模型。接下来我们将从文献中回顾基于采样的离散化策略。一种直接的方法是选择一组运动基元(固定策略),然后从车辆的初始构型 mathrm{x}_{text {init }}出发,递归地应用这些基元,来生成搜索图,例如使用算法1的方法。对于没有微分约束的路径规划,运动基元可以简单地是一组具有不同方向和长度的直线。对于类车车辆,运动基元可以是一组弧,表示汽车以不同的转向值跟随的路径。多种技术都可用于生成无人驾驶车辆的运动基元。一种简单的方法是采样多个控制输入,并使用车辆模型实时模拟前进,以获得可行的运动。为了获得具有连续曲率的路径,有时也使用回旋曲线段[105]。
此外,还可以通过记录由专家驾驶员驾驶的车辆的运动来获得运动基元[106]。
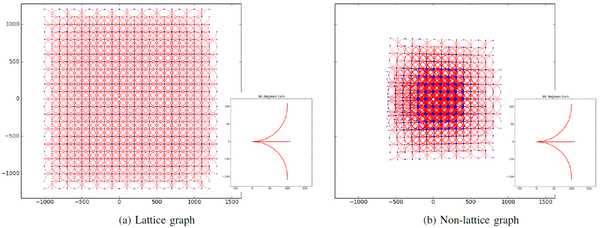
图4.2:栅格图和非栅格图,均具有5000条边
(a) 通过递归地应用 90∘ 左圆弧、 90∘ 右圆弧和直线而生成的图。(b) 通过递归地应用 89∘ 左圆弧、 89∘ 右圆弧和直线得到的图形。
对于(b),这些基元的递归应用确实没有生成栅格,而是生成了树,且树的很多分支在原点附近环绕。因此,其生成的图(右侧的图)所覆盖的区域较小。
我们可以观察到,递归地应用运动基元能生成树图,这种图在最坏情况下,不存在两条能到达相同构型的边。然而,称为“栅格生成(lattice-generating)”的运动基元集能生成形似栅格(lattice)的规则图形。
见图4.2a,栅格生成基元的优点是搜索图的顶点能够均匀地覆盖构型空间,而树通常可能在根顶点的周围出现高密度分布的顶点。Pivtoraiko等人使用术语“状态栅格(state lattice)”来描述[107]中的此类图,并指出,如果首先在原点周围生成规则间隔的构型,然后通过表示两点边值问题的解的路径将原点连接到这种构型,就可以得到当前系统的一组栅格生成运动基元。
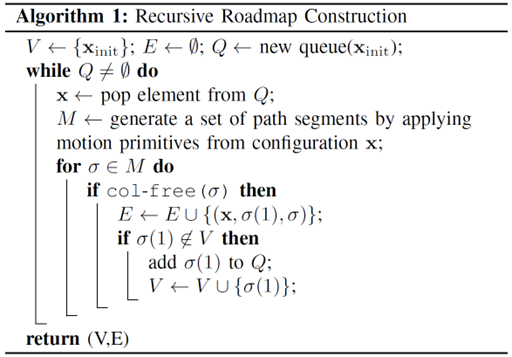
通过生成覆盖(自由)构型空间的离散样本集,并通过使用精确的转向程序获得的可行路径段将它们连接起来,可以实现类似于从初始构型出发、递归地应用栅格生成运动基元的所产生的效果。

大多数基于采样的路线图的构造方法都遵循算法2所示的方案,但是在采样点函数 text { sample-points }(mathcal{X}, n) 和邻点函数 text { neighbors }(mathrm{x}, V) 的实现上有所不同。采样点函数text { sample-points }(mathcal{X}, n)表示从构型空间 chi 中选择 n 个点的策略,而邻点函数text { neighbors }(mathrm{x}, V)表示为顶点 x 选择一组邻顶点 N subseteq V 的策略。对于邻顶点 y,该算法将尝试通过精确转向函数 text { steer }_{text {exact }}(mathrm{x}, mathrm{y}) 来找到一条从 y 连接到 x 的路径段。
函数 text { sample-points }(mathcal{X}, n) 的最常见的两种实现方式是:(1)返回排列在一个规则网格中的 n 个点,(2)返回 chi 中的 n 个随机采样点。尽管随机抽样具有普遍适用和易于实施的优点,但所谓的Sukharev网格已经被证明在单位超立方体中实现了最优 L_{infty} 散度,即其最小化了内部没有采样点的最大空球的半径。为了深入讨论基于采样的路径规划环境中随机采样和确定性采样的相对优点,我们请读者参考[108]。
实现函数 text { neighbors }(mathrm{x}, V)的两个最常用策略是:(1)与 x 最近的 k 近邻的集合,(2)位于以 x 为中心的、半径为 r 的球内的点的集合。特别地,在 d 维网格中以确定性方式排列的样本,若其邻域在二维中取为 4 个或 8个最近邻、在更高维度中取为与二维情况相类似的模式,那么这些样本代表了自由构型空间的简单确定性离散化,部分是因为它们自然产生于机器人构型空间的自由和占用区域所广泛使用的位图表示[109]。
Kavraki等人[110]主张在概率路线图(PRM)框架内使用随机抽样,以便在高维构型空间中构造路线图,因为与网格不同,它们随时可以自然运行。批处理版本的PRM遵循算法2的方案,其采用随机抽样,并且在固定半径 r 的球内选择邻点[79]。由于PRM具有通用的形式,它们已用于各种系统的路径规划,包括具有微分约束的系统。然而,该算法的理论分析主要集中于无微分约束系统的算法性能,即,当使用直线连接两种构型时。在这样的假设下,文章[80]中的PRM被证明是概率完备且渐近最优的。
也就是说,其生成的图包含有效解(如果存在)的概率随着图的大小的增加而收敛到 1,且图中最短路径的成本随之收敛到最优成本。Karaman和Frazzoli提出了一种称为PRM*的批处理PRM的自适应版本[80],其仅连接一个球内的邻顶点。该球的半径随着样本数量的增加而对数大小地减小。这么做的目的是保持算法的渐近最优性以及计算效率。
在同一篇论文中,作者同时提出了快速探索随机图(RRG*)。这是一种增量离散化策略,在保持渐近最优性的同时能够随时终止。最近,快速行进树(FMT*)[111]被提出作为PRM*的渐近最优替代方案。该算法通过对一组采样顶点执行惰性动态规划递归,将离散化和搜索结合到一个过程中。这些采样顶点随后可以被用于快速确定从初始构型到目标区域的路径。
最近,理论分析也扩展到微分约束系统。
Schmerling等人[81]提出了PRM*和FMT*的微分版本,并证明了这些算法对于无漂移的仿射控制的动力系统的渐近最优性。这一类动力系统包括无滑移的轮式车辆模型。
4) 图搜索策略在上一节中,我们讨论了将自由构型空间离散化为图的形式的技术。为了在这种离散化中获得一条实际的最优路径,必须使用图搜索算法。
在本节中,我们将回顾与路径规划相关的图搜索算法。最受广泛认可的、用于在图中找到最短路径的算法可能是Dijkstra算法[32]。它执行最佳优先搜索(best first search),以构建表示从给定源顶点到图中所有其他顶点的最短路径的树。当只需要到单个顶点的路径时,可以使用启发式方法来指导搜索。最著名的启发式搜索算法是Hart、Nilsson和Raphael开发的A*算法[112]。
如果给定的启发式函数是可接受的(admissible),即,函数从不会高估未来要花费的成本(cost-to-go),则此时A*是最优有效的,并保证返回最优解。许多问题可以使用加权A*算法[113],以较少的计算量获得一个有界的次优解,这相当于简单地将启发式乘以一个常数因子 epsilon>1 。
可以证明,利用这种膨胀的启发式方法,A*保证返回的解路径在最差情况下只有最优路径的成本的 1+epsilon 倍。通常,每次使用传感数据更新世界模型时,算法会再次寻找从车辆当前构型到目标区域的最短路径。由于每次这样的更新通常只影响图的小部分区域,所以每次完全从头开始搜索可能会浪费时间。实时的重新规划(replanning)搜索算法,例如D*算法[114]、聚焦D*算法(Focussed D*)[115]和轻量D*算法(D* Lite)[116],能在每次图发生改变时有效地重新计算最短路径,同时利用来自先前搜索的信息。
随时搜索(anytime search)算法试图首先快速找到一个次优路径,再用更多的计算时间不断改进解。随时A*算法(anytime A*)[117]使用加权启发式函数来找到第一个解,再以第一个解路径的成本为上限、以可接受的启发式为下限,来继续搜索,以实现随时搜索的功能。
而随时修复A*算法(Anytime Repair A* / ARA*)[118]使用权重降低的膨胀启发式来执行一系列搜索,并重复利用来自先前迭代的信息。
另一方面,随时动态A*算法(Anytime Dynamic A* / ADA*)[119]结合了D* Lite和ARA*的思想,为动态环境中的实时重新规划提供了一种随时搜索算法。用于在构型空间的离散化图上搜索路径的算法存在的明显限制是,在这样的图上得到的最优路径可能显著长于构型空间中的真实最短路径。任意角度路径规划算法(any-angle path planning algorithms)[120-122]在网格上运行,或者更一般地,在表示自由构型空间的单元分解(cell decomposition)的图上运行,并通过在搜索过程中考虑图中顶点之间的“捷径(shortcuts)”来尝试减轻这一缺点。
此外,真实场景D*算法(Field D*)通过将线性插值引入搜索过程来产生平滑路径[123]。E. 增量搜索技术在固定的离散化图上进行搜索的技术的缺点是,其只搜索可以由基元构造的一组路径,因此这些技术可能无法返回可行的路径或返回明显次优的路径。增量可行运动规划器努力解决这个问题,并在给定足够的计算时间的情况下,为任何运动规划问题实例提供可行路径(如果存在可行路径)。
通常,这些方法逐步构造对构型空间的越来越精细的离散化,同时尝试确定在每一步离散化中是否存在从初始构型到目标区域的路径。如果实例是“简单”的,则可以快速得到解,但是通常情况下,计算时间可能是无限长的。类似地,在快速找到可行路径的基础上,增量最优运动规划方法试图提供一系列质量不断提高的解,从而收敛到最优路径。文献中使用“概率完备(probabilistically complete)”一词来描述一种算法。这类算法找到解(如果存在解)的概率随着计算时间的增加而接近 1。
请注意,如果解并不存在,则概率完备的算法可能不会终止。
类似地,渐近最优(asymptotically optimal)一词用于描述以概率 1 收敛到最优解的算法。极限情况下获得完备性和最优性的一种简单策略是在构型空间的固定离散化上解决一系列路径规划问题,且每次都采取更高的离散化分辨率。此方法的一个缺点是,各个分辨率级别上的路径规划过程是独立的,无法重复利用任何信息。此外,在开始新一轮图搜索前,我们并不明显地知道应该多快地增加离散化的分辨率,即,到底是添加单个新构型、还是增加一倍数量的构型、还是沿着构型空间的每个维度增加一倍数量的离散值更加合适。为了克服这些问题,增量运动规划方法将构型空间的增量离散化与路径搜索结合到一个步骤中。
增量路径规划的一类重要方法的思路是,在车辆初始构型处向外增量生长树,以探索可到达的构型空间。“探索性”行为迭代地选择树的一个随机顶点,并在树中应用转向函数,以扩展(expand)所选顶点。一旦树生长到足以到达目标区域,则可以从目标区域内的顶点出发,反向跟踪能到达初始构型的边,来获得生成的路径。算法3中描述了基于增量树的算法的一般方案。

第一个基于随机树的增量规划器是Hsu等人提出的扩展空间树(EST)规划器[124]。其以特定的概率从 V 中随机选择一个用于扩展的顶点 mathrm{X}_{text {selected }}。概率与其邻域中顶点的数量成反比,从而鼓励向未探索区域的增长。
在扩展过程中,算法在 mathrm{X}_{text {selected }}周围的固定半径的邻域内采样得到一个新顶点 y。我们使用相同的技术来偏置这个采样过程,使其能在相对较少探索的区域选择顶点。随后,算法返回 mathrm{X}_{text {selected }}和 y 之间的一条直线路径。
文章[125]引入了在动态环境中进行具有动力学约束的规划的推广思想,其中在不同的非完整机器人系统上证明了算法的能力。此外,作者还使用理想化版本的算法,证明了无法找到可行路径的概率取决于状态空间的可扩展性,并且这个概率随着样本的数量增长而呈指数衰减。
La Valle提出了快速探索随机树(RRT)[101],作为寻找高维非完整系统的可行轨迹的一种有效方法。该算法从自由构型空间中随机采样 x_{r n d} ,并在随机样本的方向上扩展树,来实现快速探索。在RRT中,顶点选择函数 text { select }(V) 根据两个构型之间的给定的距离度量,返回随机样本 x_{r n d} 的最近邻。扩展函数 text { extend() } 随后通过在固定时间步长上应用一个能最小化到 x_{r n d} 的距离的控制输入,以在构型空间中生成一条路径。在某些简化的假设(随机转向用于扩展)下,RRT算法已被证明是概率完备的[83]。我们注意到,这个概率完备性的结论并不能轻易推广到许多实际实现的RRT版本,后者通常使用启发式转向。事实上,最近[126]中已经表明,使用具有固定时间步长的启发式转向的RRT不是概率完备的。
此外,Karaman和Frazzoli证明了RRT以概率1收敛到次优解,并设计了RRT的渐近最优版本,称为RRT*算法[127]。如算法4所示,在每次迭代时,RRT*考虑位于新添加的顶点 x_{n e w} 的邻域内的一组顶点,随后(a)将 x_{n e w} 连接到邻域中的一个顶点,以最小化从 mathrm{x}_{text {init }} 到 x_{n e w} 的路径成本,(b)如果将该邻域内的某个顶点重新连接到 x_{n e w} 后,从 mathrm{x}_{text {init }}到该顶点的路径成本降低了,那么执行这个重连接(rewire)操作。该算法的一个重要特征是,邻域被定义为以 x_{n e w} 为中心的球,其半径是树的大小的函数: r=gamma sqrt[d]{(log n) / n} ,其中 n 是树的顶点的数量, d 是构型空间的维度, gamma 是依赖于实例的常数。结果表明,对于这样的函数,球内顶点的期望个数是树的大小的对数,这对于确保算法几乎肯定地收敛到最优路径、同时保持与次优RRT相同的渐近复杂性来说是必要的。

文章[80]中陈述了微分约束下RRT*的渐近最优性的充分条件,并且证明,这对于Dubins车辆和双积分器系统来说是可满足的。在随后的工作中,作者进一步表明,在小时间局部可达系统(small-time locally attainable systems)的情况下,该算法不仅可以保持渐近最优性,而且可以保持计算效率[82]。其他相关的工作将注意力放在通过局部线性化系统动力学[128]或通过推导得到具有线性动力学的系统的闭式解[129],来得到非完整系统的距离和转向函数。另一方面,RRTX是一种RRT*的扩展算法,其允许在障碍物区域发生变化时(例如面对来自传感器的新数据时)进行实时增量重新规划[130]。基于采样的算法领域的新进展包括提出了在缺少精确转向程序的情况下实现渐近最优的算法。特别是,Li等人[84]最近提出了面向渐近(近似)最优路径规划的稳定稀疏树(SST)。
该方法基于通过系统动力学的前向模型来传播的随机采样控制树,从而修剪出(prune out)局部次优的分支,以确保树保持稀疏。
F. 实际部署我们已经讨论了自动驾驶车辆的三类路径规划方法:变分法、图搜索法和基于增量树的方法。自动驾驶系统的实际现场部署算法来自上述的所有类别。
例如,即使是DARPA城市挑战赛的前四位成功参与者,采用的运动规划方法也存在显著差异。作为挑战的胜利者,卡内基梅隆大学的Boss车辆使用变分技术来在结构化的环境中生成局部轨迹,并在四维构型空间(由位置、方向和速度组成)中使用栅格图以及Anytime D*,以在停车场中找到无碰撞路径[131]。据报道,斯坦福大学团队开发的亚军车辆使用了一种被称为混合A*(Hybrid A*)的搜索策略。
在搜索过程中,其通过递归地应用有限的一组策略,惰性地构建一个运动基元树。该搜索由精心设计的启发式方法指导,并且在构型空间的给定区域中仅保留单个节点,来确保树的稀疏性[132]。类似地,弗吉尼亚理工大学VictorTango团队开发的季军车辆构造了一个包含可能的策略的离散化图,并使用A*算法搜索此图[133]。最后,麻省理工学院开发的车辆使用了一种RRT算法的变体,称为具有偏置采样(biased sampling)的闭环RRT算法[134]。
5. 车辆控制运动规划过程提供了问题4.1或4.2的解。
反馈控制器的作用是,在存在建模误差和其他形式的不确定性的情况下,稳定于参考路径或轨迹。根据运动规划器提供的参考,控制目标可以是路径稳定或轨迹稳定。更正式地说,路径稳定问题表述如下:问题 5.1 路径稳定(Path Stabilization)给定受控微分方程 dot{x}=f(x, u) ,参考路径 x_{text {ref }}: mathbb{R} rightarrow mathbb{R}^n ,以及参考速度 v_{text {ref }}: mathbb{R} rightarrow mathbb{R} ,找到一个反馈律,使得 dot{x}=f(x, u(x)) 的解满足如下命题:对于 forall epsilon>0, t_10 以及可微分的 S: mathbb{R} rightarrow mathbb{R} ,使得begin{aligned} & 1) rightarrowleft|xleft(t_1right)-x_{text {ref }}left(sleft(t_1right)right)right| leq delta quad Longrightarrowleft|xleft(t_2right)-x_{text {ref }}left(sleft(t_2right)right)right| leq epsilon \ & 2) rightarrow lim _{t rightarrow infty}left|x(t)-x_{text {ref }}(s(t))right|=0 \ & 3) rightarrow lim _{t rightarrow infty} dot{s}(t)=v_{text {ref }}(s(t))end{aligned}
定性地说,上述的条件表示:(1) 小的初始跟踪误差仍将保持小,(2) 跟踪误差必须收敛到零,(3) 沿着参考路径的行驶趋近于规定速率(nominal rate)。许多已被提出的车辆控制律,包括本节将要讨论的几个,都使用以下形式的反馈律:u(x)=fleft(arg min _gammaleft|x-x_{r e f}(gamma)right|right) (5.1)其中反馈是参考路径上距车辆最近的点的函数。该形式的控制的一个重要问题是闭环向量场 f(x, u(x)) 非连续。如果路径是自相交的或在某一点不可微分,则 f(x, u(x)) 存在的不连续性将直接出现在路径上。若执行的轨迹存在不连续性,则将导致不可预测的行为。这种不连续性如图5.1所示。
文章[135]提出了一种反推(backstepping)控制设计,其不使用公式(5.1)的反馈律。轨迹稳定问题更加简单,但是这些控制器容易受到性能限制[136]。
问题 5.2 轨迹稳定(Trajectory Stabilization)给定受控微分方程 dot{x}=f(x, u) 和参考轨迹 x_{r e f}(t) ,找到 pi(x) 使得 dot{x}=f(x, pi(x)) 的解满足如下命题:对于 forall epsilon>0, t_10 ,使得begin{aligned} & text { 1) } rightarrowleft|xleft(t_1right)-x_{text {ref }}left(t_1right)right| leq delta \ & quad Rightarrowleft|xleft(t_2right)-x_{text {ref }}left(t_2right)right| leq epsilon \ & text { 2) } rightarrow lim _{t rightarrow infty}left|x(t)-x_{text {ref }}(t)right|=0 end{aligned}
在许多情况下,分析轨迹的稳定性可以简化为确定时变系统的原点的稳定性。李雅普诺夫定理的基本形式仅适用于时不变系统。然而,时变系统的稳定性理论也得到了很好的建立(例如[137]的定理4.9)。对于各种类型的稳定性,一些有用的术语包括:时变系统的一致渐近稳定性(uniformly / uniform asymptotic stability),其断言上述问题的条件 1 中的 delta 独立于 t_{1} 。指数稳定性(exponential stability),其断言收敛速率以指数衰减为界。
需要注意的一个微妙问题是,当时间趋于无穷大时,控制器的规范通常用渐近跟踪误差来表示。在实践中,参考轨迹是有限的,因此还应当考虑系统的瞬态响应。本节的剩余部分将选择一些适用于无人驾驶汽车的控制设计,并对其进行综述。表2提供了这些控制器的概述。第5-A小节详细介绍了用于运动学模型的路径稳定的一些有效控制策略。第5-B2小节讨论了轨迹稳定技术。第5-C小节将讨论的预测控制策略对于更复杂的车辆模型是有效的,可以应用于路径和轨迹稳定。
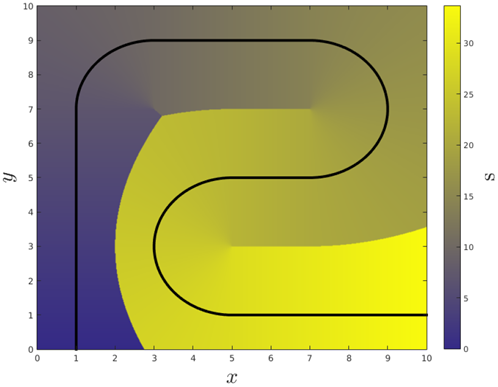
图5.1:(5.5)的可视化黑线表示参考路径的样例。平面上每个点的 s 值用颜色表示,这描绘了(5.5)中的不连续性。
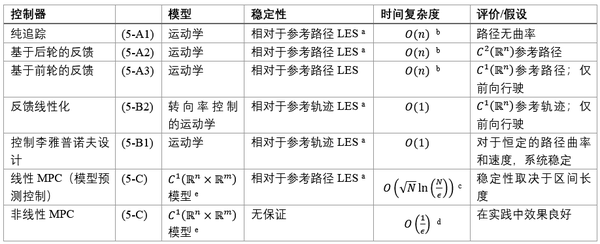
表2:本节讨论的控制器概述说明: a: 局部指数稳定性(LES); b: 假设(5.1)是通过在路径或轨迹的 n 点离散化上的线性搜索来评估的; c: 假设使用内点法求解(5.28),其中时间范围/区间(horizon)为 n ,解的精确度为 epsilon ; d: 基于使用最陡下降的、向(5.25)的局部最小值收敛的渐近收敛速率,不保证返回解或找到全局最小值; e: 由 mathbb{R}^m 中的各个输入定义的状态空间 mathbb{R}^n 上的向量场是连续可微分函数,从而定义关于参考的成本梯度或线性化。
A. 基于运动学模型的路径稳定
1) 纯追踪(Pure Pursuit)纯追踪算法是最早提出的路径跟踪(path tracking)策略之一。文章[138]中第一次讨论了它,并在[52][139]中进行了详细阐述。该策略及其变体(例如[140][141])已被证明是车辆控制不可或缺的工具,因为其实施简单且性能令人满意。许多相关成果,包括DARPA大挑战中的两辆车[8]和DARPA城市挑战中的三辆车[9]都报道使用了纯追踪器。
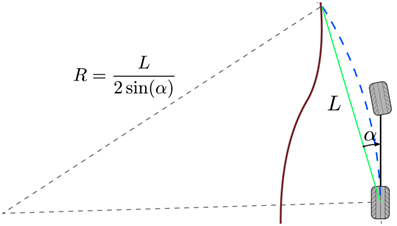
图5.2:纯追踪控制器的几何结构
一个圆(蓝色)位于后轮位置和参考路径(棕色)之间,使得弦长(绿色)为前瞻距离 L ,并且该圆与当前车辆的朝向方向相切。纯追踪的控制律的基本思想是,利用半圆弧来拟合从车辆当前构型到参考路径上特定一点,这个特定点在车辆前方、距离为 L ,称为前瞻距离(lookahead distance)。
图5.2描述了这个几何结构。通过两个点和一个切线来定义这个圆:代表汽车所处位置的点、在该点处与车辆朝向方向相同的切线、车辆前方相距一个前瞻距离的参考路径上的点。圆的曲率由下式给出:kappa=frac{2 sin alpha}{L} (5.2)对于车辆速度 v_r ,指令的航向速率为omega=frac{2 v_r sin alpha}{L} (5.3)在这个控制器的最早报道[138]中,从相机的输出数据中直接计算角度 alpha 。
然而, alpha 可以用惯性坐标系表示,以定义一个状态反馈控制。考虑构型 left(x_r, y_r, thetaright)^T 以及路径点 left(x_{r e f}(s), y_{r e f}(s)right) ,使得left|left(x_{text {ref }}(s), y_{text {ref }}(s)right)-left(x_r, y_rright)right|=L 。由于路径上通常不止有一个这样的点,我们选择参数 s 的值最大的点,以唯一地定义控制。进而, alpha 由下式给出:alpha=arctan left(frac{y_{text {ref }}-y_r}{x_{text {ref }}-x_r}right)-theta (5.4)
假设路径没有曲率且车辆速度恒定(可能为负),则纯追踪控制器可以给出问题5.1的解。对于固定的非零曲率,纯追踪具有较小的稳态跟踪误差。在车辆到路径的距离大于 L 的情况下,控制器输出并未被定义。另一个考虑是,参考路径的曲率的变化会导致汽车偏离参考轨迹,这对于沿道路行驶的任务可能可以接受,但是对于跟踪泊车策略可能存在问题。最后,随着车辆速度的增加,航向速率指令 omega 对反馈角 alpha 更加敏感。解决此问题的一个常见方法是根据车速来缩放 L 。
2) 基于后轮位置的反馈后轮反馈控制使用后轮位置作为输出,使之稳定于一条标准后轮路径[56]。控制器规定s(t)=arg min _gammaleft|left(x_r(t), y_r(t)right)-left(x_{text {ref }}(gamma), y_{text {ref }}(gamma)right)right| (5.5)文章[56]中描述了关于参考路径和包含参考路径的有限域的详细假设,在这个有限域内,(5.5)是连续函数。
s(t) 处与路径相切的单位正切由下式给出hat{t}=frac{left(left.frac{partial x_{r e f}}{partial s}right|_{s(t)},left.frac{partial y_{r e f}}{partial s}right|_{s(t)}right)}{left|left(frac{partial x_{r e f}(s(t))}{partial s}, frac{partial y_{r e f}(s(t))}{partial s}right)right|} (5.6)且跟踪误差向量为d(t):=left(x_r(t), y_r(t)right)-left(x_{text {ref }}(s(t)), y_{text {ref }}(s(t))right) (5.7)
这些值用于根据路径 e 计算横向误差坐标,其中路径 e 是两个向量之间的向量积e=d_x hat{t}_y-d_y hat{t}_x (5.8)其中下标表示向量的分量索引。这种控制策略使用车辆的航向向量和路径的切线向量之间的角度 theta_e 。theta_e(t)=theta-arctan _2left(frac{partial y_{text {ref }}(s(t))}{partial s}, frac{partial x_{text {ref }}(s(t))}{partial s}right) (5.9)这个几何关系如图5.3所示。
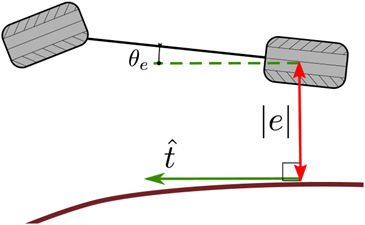
图5.3:基于后轮的反馈控制的反馈变量theta_e 是路径上距离后轮最近的点处的切线与汽车航向之间的差值。标量 e 的大小(绝对值)用红色表示。
如图所示, e>0 ,而对于汽车位于路径左侧的情况,e<0。坐标 left(s, e, theta_eright) 的变化率满足:begin{aligned} & dot{s}=frac{v_r cos theta_e}{1-kappa(s) e} \ &dot{e}=v_r sin theta_e \ & theta_e=omega-frac{v_r kappa(s) cos theta_e}{1-kappa(s) e} end{aligned} (5.10)
其中 kappa(s) 表示路径在 s 处的曲率。下式中的转向率指令为局部渐近收敛提供了连续二次可微分的路径:omega=frac{v_r kappa(s) cos theta_e}{1-kappa(s) e}-g_1left(e, theta_e, tright) theta_e-k_2 v_r frac{sin theta_e}{theta_e} e (5.11)
其中 g_1left(e, theta_e, tright)>0, k_2>0, v_r neq 0 ,可以通过[56]中利用了坐标系(5.10)的李雅普诺夫函数Vleft(e, theta_eright)=e^2+theta_e^2 / k_2 来证明。之所以要求路径是二次可微分的,是因为反馈定律中出现了曲率。
这种控制律的一个优点是,稳定性不受 v_r 的正负号的影响,从而使其适用于反向驾驶。当 k_e>0 时,设置 g_1left(v_r, theta_e, tright)=k_thetaleft|v_rright| 可以实现局部指数收敛,且收敛速率与车速无关(只要 v_r neq 0)。
这种情况下的控制律是omega=frac{v_r kappa(s) cos theta_e}{1-kappa(s) e}-left(k_thetaleft|v_rright|right) theta_e-left(k_e v_r frac{sin theta_e}{theta_e}right) e (5.12)3)
基于前轮位置的反馈前轮反馈控制是斯坦福大学在2005年DARPA大挑战中提出并使用的方法[55][8],其将前轮位置作为控制变量。它同样使用上一节中的变量 s(t), e(t), theta_e(t) ,不同的是其根据前轮位置而不是后轮位置来计算 e(t) 。取横向误差的时间导数dot{e}=v_f sin left(theta_e+deltaright) (5.13)对于上式中的误差变化率,如果大小小于 v_f ,则可直接由转向角控。转向角的解应使得 dot{e}=-k e 能以指数速度将 e(t) 控制到零。
begin{aligned} v_f sin left(delta+theta_eright)=-k e Rightarrow & delta=arcsin left(-frac{k e}{v_f}right)-theta_e end{aligned} (5.14)
在这种情况下,术语 theta_e 不被解释为航向误差,因为即使在完美跟踪的情况下,它也将是非零的。更恰当的解释应该是, theta_e 是为用于追踪参考路径的标准转向角的前馈项和航向误差项的组合。这种控制律的缺点是,当 left|frac{k e}{v_f}right|>1 时,它未被定义。
通过如下的反馈律,有限域上的指数收敛可以被放松为局部指数收敛。delta=arctan left(-frac{k e}{v_f}right)-theta_e (5.15)考虑 e 的一阶导,该式与前面的公式相同,如图5.4所示。与(5.14)中的控制律一样,此控制器在路径连续可微分的条件下,局部指数地将车辆稳定于具有可变曲率的路径。之所以要求路径连续可微分,是因为反馈策略中对 theta_e 的定义。此控制器的缺点是它在倒车时不稳定,因此不适合处理泊车任务。
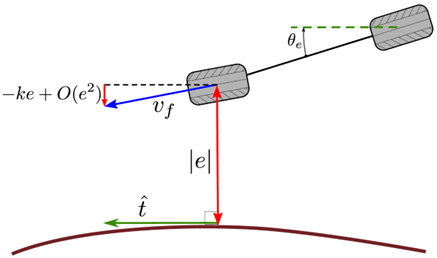
图5.4:基于前轮输出的控制这种控制策略将前轮指向路径,以使前轮垂直于路径的速度分量正比于前轮到路径的距离。这种控制在局部实现,并导致局部指数收敛。
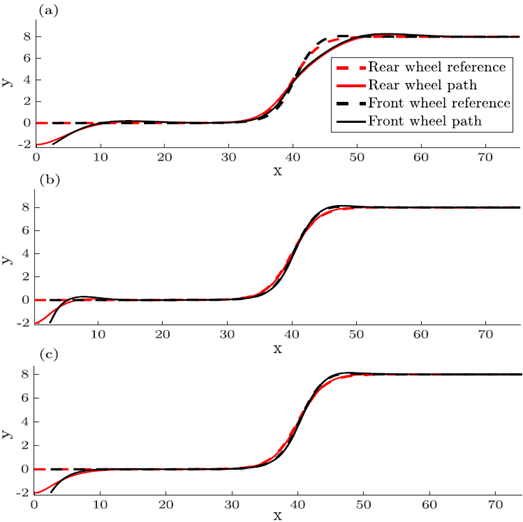
图5.5:本节中的三种路径稳定控制律的跟踪性能比较。
(a) 当曲率非零时,纯追踪控制策略偏离参考路径。(b) 基于后轮输出的控制器将后轮驱动至后轮参考路径。系统的二阶响应导致了过冲。(c) 基于前轮输出的控制器以一阶响应将前轮驱动至参考路径并跟踪路径。
面向运动学模型的路径跟踪控制器的比较:基于具有车轮无滑移约束的运动学模型的控制器的优点在于,它们的计算要求低,易于实现,并且在中等速度下具有良好的性能。
图5.5定性比较了本节讨论的路径稳定控制器,其中各个控制器基于(3.3)进行了变道策略的模拟。在基于前轮输出的控制器的仿真中,后轮参考路径被满足以下条件的前轮参考路径代替begin{aligned} & x_{r e f}(s) longmapsto x_{r e f}(s)+l cos theta \ & y_{r e f}(s) longmapsto y_{r e f}(s)+l sin theta end{aligned} (5.16)模拟中涉及的参数如表3所示。
参考图5.5,纯追踪控制在没有曲率的周期内能够跟踪参考路径。在对应高曲率路径的区域中,纯追踪控制将导致系统偏离参考路径。与之相反,后两种控制器收敛于参考路径,并仍能在高曲率的区域内跟踪参考路径。对于均使用(5.5)作为控制策略的两种控制器,仅当存在路径的邻域使得(5.5)是连续的,局部指数稳定性才能被证明。直觉上,这意味着路径不能自相交,且必须是可微分的。
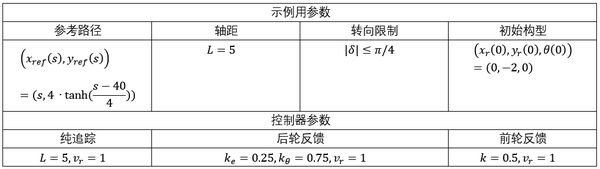
表3:用于生成图5.5的模拟和控制器参数B. 基于运动学模型的轨迹跟踪控制1) 基于控制李雅普诺夫函数的设计文章[142]描述了基于控制李雅普诺夫函数的控制设计,其在汽车坐标系中定义跟踪误差。
利用参考轨迹和参考速度 left(x_{text {ref }}, y_{text {ref }}, theta_{text {ref }}, v_{text {ref }}, omega_{text {ref }}right) ,构型误差可以表示为惯性坐标系的基的变化:left(begin{array}{l} x_e \ y_e \ theta_e end{array}right)=left(begin{array}{ccc} cos theta & sin theta & 0 \ -sin theta & cos theta & 0 \ 0 & 0 & 1 end{array}right)left(begin{array}{c} x_{text {ref }}-x_r \ y_{text {ref }}-y_r \ theta_{text {ref }}-theta end{array}right)
构型误差的变化继而满足:begin{aligned} & dot{x}_e=omega y_e-v_r+v_{r e f} cos theta_e \ & dot{y}_e=-omega x_e+v_{r e f} sin theta_e \ &dot{theta}_e=omega_{r e f}-omega end{aligned}
通过如下的控制分配begin{aligned} &v_r=v_{r e f} cos theta_e+k_1 x_e \ &omega=omega_{r e f}+v_{r e f}left(k_2 y_e+k_3 sin theta_eright) end{aligned}
可以得到如下的闭环误差动力学begin{aligned} &dot{x}_e=left(omega_{text {ref }}+v_{text {ref }}left(k_2 y_e+k_3 sin theta_eright)right) y_e-k_1 x_e \ &dot{y}_e=-left(omega_{text {ref }}+v_{text {ref }}left(k_2 y_e+k_3 sin theta_eright)right) x_e+v_{text {ref }} sin theta_e \ &theta_e=omega_{text {ref }}-omega end{aligned}
对于 k_{1,2,3}>0, dot{omega}_{r e f}=0, dot{v}_{text {ref }}=0 ,其稳定性可以由如下的李雅普诺夫函数得证V=frac{1}{2}left(x_e^2+y_e^2right)+frac{1-cos theta_e}{k_2}
且李雅普诺夫函数具有半负定的时间导数dot{V}=-k_1 x_e^2-frac{v_{r e f} k_3 sin ^2 theta_e}{k_2} 局部的分析表明,此控制律实现了局部指数稳定性。
然而,对于时不变系统,要求 omega_{r e f} 和 v_{text {ref }} 是常数。文章[143]提出了一种相关的控制器,其利用反推的设计方法,以达到在具有时变参考的有限域上的一致局部指数稳定性。2) 输出反馈线性化对于较高的车辆速度,同理(3.8),应当约束转向角以实现连续转向。由于附加了一个状态,从简单的几何角度来考虑如何设计控制器变得更加困难。在这种情况下,输出线性化的系统是一种好的选择。使用前轮或后轮的位置并不容易实现这一点。文章[144]中提出了简化反馈线性化的输出,其中选择了与转向角对齐的、距离车辆前方任意 d neq 0 的点。设 x_p=x_f+d cos (theta+delta) 和 y_p=y_f+d sin (theta+delta) 为系统的输出。
取输出的导数,代入(3.8)的动力学得begin{aligned} left(begin{array}{l} dot{x}_p \ dot{y}_p end{array}right)=left(begin{array}{cc} cos (theta+delta)-frac{d}{l} sin (theta+delta) sin delta & -d sin (theta+delta) \ sin (theta+delta)+frac{d}{l} cos (theta+delta) sin delta & d cos (theta+delta) end{array}right)left(begin{array}{l} v_f \ v_delta end{array}right) =: A(theta, delta)left(begin{array}{l} v_f \ v_delta end{array}right) end{aligned} (5.17)
再定义(5.17)等式右侧为辅助控制变量 u_x 和 u_y ,有left(begin{array}{l} dot{x}_p \ dot{y}_p end{array}right)=left(begin{array}{l} u_x \ u_y end{array}right) (5.18)
这使得控制变得简单。根据 u_x 和 u_y ,使用(5.17)中的矩阵的逆,来重新得到原始控制 v_f 和 v_delta ,如下所示:begin{aligned} {[A(theta, delta)]^{-1}} & =left(begin{array}{cc} cos (theta+delta) & sin (theta+delta) \ -frac{1}{d} sin (theta+delta)-frac{1}{l} cos (theta+delta) sin delta & frac{1}{d} cos (theta+delta)-frac{1}{l} sin (theta+delta) sin delta end{array}right) end{aligned} (5.19)
根据输入-输出线性系统,可以通过如下的控制,来实现局部轨迹稳定begin{aligned} & u_x=dot{x}_{p, text { ref }}+k_xleft(x_{p, r e f}-x_pright) \ & u_y=y_{p, text { ref }}+k_yleft(y_{p, r e f}-y_pright) end{aligned} (5.20)
为避免混淆,注意在这种情况下,输出位置 left(x_p, y_pright) 和受控速度 v_f 并不像前面讨论的控制器那样配置。
C. 预测控制方法
上面讨论的简单控制律适用于中等驾驶条件。然而,湿滑道路或紧急机动可能需要更精确的模型,例如第3-B节中介绍的模型。更复杂的模型所增加的细节使控制设计复杂化,使得难以根据直觉和构型空间的几何结构来构造控制器。模型预测控制[145]是一种通用的控制设计方法,对这种问题非常有效。从概念上讲,此方法在短时间范围/区间内求解运动规划问题,取短时间间隔内的开环控制,并将其应用于系统。
在执行时,重新求解运动规划问题,以找到下一时间间隔的适当控制。计算硬件和数学编程算法的进步使得预测控制在无人驾驶车辆中的实时应用成为可能。MPC本身是一个主要的研究领域,本节仅旨在简要描述该技术,并综述其在无人驾驶车辆控制中的应用结果。由于模型预测控制是一种非常通用的控制技术,因此其模型可表示为具有控制 u(t) in mathbb{R}^m 和状态 x(t) in mathbb{R}^n 的一般连续时间控制系统:dot{x}=f(x, u, t) (5.21)问题给定一条可行的参考轨迹 x_{text {ref }}(t) ,以及对于一些运动规划器,还给定 u_{r e f}(t) 。这些给定条件满足(5.21)。
随后,通过一种合适的数值近似来离散化系统,使得(5.21)在离散时间情况下表示为x_{k+1}=F_kleft(x_k, u_kright), quad k in mathbb{N} (5.22)欧拉法是最简单的离散化策略之一,其对控制施加零阶保持begin{aligned} F_k(x(k cdot Delta t), u(k cdot Delta t)) =x(k cdot Delta t)+Delta t & cdot fleft(x(k cdot Delta t), u(k cdot Delta t), t_kright), quad k in mathbb{N} end{aligned} (5.23)
状态和控制在时间 t_k=k cdot Delta t 时通过其近似值离散化。离散系统的解是近似的,因此不会精确地匹配连续时间方程。类似地,在离散时间 t_k 采样的参考轨迹和控制将不满足离散时间方程。例如,(5.23)和(5.21)的解之间的误差将是 O(Delta t) ,且在时间 t_k 采样的参考轨迹将导致F_kleft(x_{r e f}left(t_kright), u_{r e f}left(t_kright)right)-x_{r e f}left(t_{k+1}right)=Oleft(Delta t^2right) (5.24)
为了避免过度复杂化接下来的讨论,我们在本节的剩余部分假设离散化是精确的。
通常,控制律有如下形式begin{array}{r} u_kleft(x_{m e a s .}right)=arg min _{substack{x_n in X_n, u_n in U_n}}left{hleft(x_N-x_{r e f, N}, u_N-u_{r e f, N}right)right. \ left.+sum_{n=k} g_nleft(x_n-x_{r e f, n}, u_n-u_{r e f, n}right)right} end{array} (5.25)约束条件:begin{aligned} &x_k=x_{text {meas. }} \ &x_{n+1}=Fleft(x_n, u_nright) \ &n in{k, ldots, k+N-1} end{aligned}
函数 g_n 将每个时间步长处的、与参考轨迹和参考控制的偏差作为惩罚项,而函数 h 是时间区间结束时的终止惩罚项。集合 x_n 是可允许状态的集合,以限制非期望的位置或速度,例如过度的轮胎打滑或障碍物。集合 mathcal{U}_n 对输入信号的幅度限制进行编码。重要的考虑因素是,(5.25)的等式右侧的解是否存在、何时存在,以及闭环系统的稳定性和鲁棒性。预测控制文献[146][147]研究了这些问题。为了在无人驾驶汽车上实现MPC,必须每秒内若干次地求解出(5.25),这是使用MPC的主要障碍。一种特殊情况下, h 和 g_n 是二次的, mathcal{U}_n 和 x_n 是多面体, F 是线性的,此时问题变成了二次规划。与一般的非线性规划不同,内点算法可以在多项式时间内求解二次规划。为了利用这一点,复杂的车辆模型通常被线性化以获得近似的线性模型。线性化方法通常在计算线性化的参考上有所不同,包括当前操作点[148-150]、参考路径[151]、或者,更一般地,参考轨迹。采用参考轨迹作为线性化的参考,将得到如下的近似线性模型:begin{aligned} & x_{r e f, k+1}+xi_{k+1}\ &= F_kleft(x_{r e f, k}, u_{r e f, k}right) +nabla_x F_kleft(x_{r e f, k}, u_{r e f, k}right) xi_k \ &+nabla_u F_kleft(x_{r e f, k}, u_{r e f, k}right) eta_k+Oleft(left|xi_kright|^2right) + Oleft(|| eta_k |^2right) \ &=: F_kleft(x_{r e f, k}, u_{r e f, k}right)+A_k xi_k+B_k eta_k+Oleft(left|xi_kright|^2right) +Oleft(|| eta_k |^2right) end{aligned} (5.26)
其中 xi:=x-x_{text {ref }} 和 eta:=u-u_{r e f} 分别是状态和控制与参考轨迹间的偏差。扰动动力学的这种一阶扩展得到了一个线性时变(LTV)系统,xi_{k+1}=A_k xi_k+B_k eta_k (5.27)
接着利用二次目标函数,并代数形式地表示多面体约束,我们可以得到begin{aligned} u_kleft(x_{text {meas. }}right)= & arg min _{xi_k, eta_k}left{xi_N^T H xi_Nright. left.+sum_{n=k}^{k+N-1} xi_k^T Q_k xi_k+eta_k^T R_k eta_kright} end{aligned} (5.28)约束条件:begin{aligned} &xi_k=x_{text {meas. }}-x_{r e f} \ &C_n xi_n leq 0, quad D_n eta_n leq 0 \ &xi_{k+1}=A_k xi_k+B_n eta_n, quad n in{k, ldots, k+N-1} end{aligned}
其中 R_k 和 Q_k 是半正定的。如果状态和输入是无约束的,即 mathcal{U}_n=mathbb{R}^m , x_n=mathbb{R}^n 则可以通过动态规划来获得半封闭形式的解,这只需要计算 N 步的矩阵递归[152]。当车辆模型表示为无状态和输入约束的受控自回归积分滑动平均模型(controlled auto-regressive integrated moving average,CARIMA)[153][154]时,类似的闭式递归解也得到了探索。模型预测控制方法的一种进阶变体是用性能泛函中的惩罚函数来代替状态约束(例如障碍物)和输入约束。文章[155]提出了这种基于具有非线性轮胎行为的动力学模型的预测控制方法。
除了惩罚控制输入以及惩罚从参考路径(不考虑障碍物且通往目标)的偏离,性能函数还惩罚对输入约束的违反以及在有限控制区间内与障碍物的碰撞。在这个意义上,它类似于基于势场的运动规划,但是被证明具有更好的性能。
以下是在汽车控制器文献中发现的模型预测控制框架的一些变体:
1) 利用运动学模型的无约束的模型预测控制文章[153]提出的最早的预测控制器属于此类,其中使用CARIMA模型,在没有输入或状态约束的情况下应用模型预测控制框架。所得到的半封闭形式的解具有最小的计算要求,并已在[154]中采用。此外,[154]中使用线性化的运动学模型,考虑了无输入或状态约束的时变线性二次规划方法。
2) 路径跟踪控制器在[151]中,使用基于质心的线性动力学模型(假设恒定速度)和近似转向模型研究了预测控制。通过详细的自动转向模型和一个具有27自由度的CarSim车辆模型,生成的集成模型得到了验证。
3) 轨迹跟踪控制器文章[148]研究了使用类似于第3节的轮胎模型的预测控制器。在仿真中执行了完全非线性预测控制策略,并在结冰条件下以20赫兹的控制频率实现了模拟紧急机动的稳定。然而,由于控制区间只有两个时间步长,然而计算时间是控制器采样时间的三倍,因此无法进行实验验证。在[148-150]中还研究了基于线性化的方法,其基于当前时间步长下车辆状态的单一线性化。此时,求解二次规划的复杂度降低,使得计算时间是可接受的,同时还报告了在结冰条件下以高达21 m/s的速度行驶的成功实验结果。文章[150]通过为时变系统的一致局部渐近稳定性提供条件,改进了该方法的模拟和实验结果。
D. 线性变参数控制
许多控制器设计技术可用于线性系统,使得人们通常期望使用线性模型。然而,正常驾驶条件下遇到的操作点范围很广,因此很难依赖于在单个操作点上线性化的模型。为了说明这一点,考虑(5.10)中的横向误差动力学。如果假设跟踪误差保持较小,则在操作点 theta_e=0 和 e=0 周围的动力学的线性化为:left(begin{array}{c} dot{e} \ dot{theta}_e end{array}right)=left(begin{array}{cc} 0 & v_r \ 0 & 0 end{array}right)left(begin{array}{l} e \ theta_e end{array}right)+left(begin{array}{l} 0 \ 1 end{array}right) omega+left(begin{array}{c} 0 \ -v_r kappa(s) end{array}right) (5.29)
引入一个新的控制变量来合并前馈 u=omega+v_r kappa(s) 以简化上式,得到动力学:left(begin{array}{c} dot{e} \ dot{theta}_e end{array}right)=left(begin{array}{cc} 0 & v_r \ 0 & 0 end{array}right)left(begin{array}{l} e \ theta_e end{array}right)+left(begin{array}{l} 0 \ 1 end{array}right) u (5.30)
我们观察到模型确实是线性的,但是前进速度 v_r 出现在线性模型中。具有增益 k_p 和 k_d 的简单比例加微分控制可以稳定横向动力学,但是闭环系统的极点为 left(-k_d pm sqrt{k_d^2-4 k_p v_r}right) / 2 。在较高速度下,极点将移动到复平面,这将导致振荡响应。相比之下,小的 k_p 增益将导致低速时的响应较差。针对这个问题的一种非常直观且广泛使用的解决方案是增益调度。在本例中,将 k_p 参数化为 v_r 的函数,可以将每个速度下的极点固定为一个值。该技术属于线性参数变化(LPV)模型的控制设计范畴[156]。增益调度是这类控制器设计的经典方法。鲁棒控制和凸优化工具很容易应用于解决更复杂的模型。在[157-159]中介绍了横向控制的LPV控制设计。在[160][161]中,同时使用了LPV模型以及预测控制方法,用于路径和轨迹稳定。
在较低的自动化水平上,LPV控制技术已被提出用于集成系统控制。在这些设计中,多个子系统被组合在一个控制器下,以实现改进的操纵性能。在[162][163]中开发了用于驱动主动和半主动悬架系统的LPV控制策略,而在[164][165]中开发了集成悬架和制动控制系统。
6. 结论
在过去三十年中,无人驾驶汽车技术的进步越来越快。除了计算和感知硬件的进步之外,移动机器人运动规划和反馈控制理论在计算方面的重大理论进步也推动了这一快速进步。毫无疑问,无人驾驶汽车所提供的道路网络的利用率和安全性的提高推动了研究工作。无人驾驶汽车是复杂系统,它已经被分解到决策问题的层次,其中一个问题的解就是下一个问题的输入。将决策问题分解为各个独立的问题,使得我们能够使用来自各个研究领域的成熟方法和技术。随后的任务便是集成这些方法,以使它们的交互语义有效,并使组合的系统在计算上高效。更有效的运动规划算法可能仅与计算密集型的反馈控制器(例如模型预测控制)兼容。
相反,一个简单的控制律可能只需要更少的计算,但是也不那么鲁棒,并且需要使用更详细的运动规划模型。本文综述了无人驾驶车辆决策问题的各个方面,且将重点放在了运动规划和反馈控制。对各种运动规划和控制技术的性能和计算要求的综述可作为参考,来帮助评估系统级设计的不同选择的兼容性和计算权衡。7. 参考文献详见原始paper,paper链接:A Survey of Motion Planning and Control Techniques for Self-driving Urban Vehicles。对自动驾驶算法与工程化感兴趣的伙伴,欢迎联系我们,有更多高质量的paper推荐给您。
发表回复