
发布于 2023-01-18 13:55・IP 属地上海  论文链接:http://robotics.stanford.edu/~ddolgov/papers/dolgov_gpp_stair08.pdfGitHub
论文链接:http://robotics.stanford.edu/~ddolgov/papers/dolgov_gpp_stair08.pdfGitHub
链接:https://github.com/karlkurzer/path_planner(其他研究人员复现代码)
文档:https://karlkurzer.github.io/path_planner/
作者:自动驾驶专栏 | 原文出处:公众号【自动驾驶专栏】
摘要
本文描述一种实际的路径规划算法,它为未知环境中运行的自动驾驶车辆生成平滑的轨迹,车辆通过其安装的传感器在线检测该环境中的障碍物。这项工作的动机为2007年DARPA城市挑战赛,并且在比赛中进行实验验证,在该比赛中车辆必须自主地导航到停车场。我们的方法有两个主要的步骤。第一步使用众所周知的A^{*}搜索算法变体,它被应用于车辆的三维运动学状态空间,但是其修改了状态更新的规则,该规则在A^{*}算法的离散节点中捕获车辆的连续状态(因此保证路径的运动学可行性)。接着,第二步通过数值非线性优化来提供解的质量,达到局部(通常全局)最优。本文所描述的路径规划算法被斯坦福赛车组机器人Junior在城市挑战赛中使用。Junior在复杂的一般路径规划任务中展示了完美的性能,例如导航到停车场以及在堵塞的道路上执行掉头,典型的完整周期重新规划时间为50-300ms。
介绍和相关工作
本文解决了未知环境中运行的自动驾驶车辆的路径规划问题。我们假设机器人具有足够的感知和定位能力,并且必须在线重新规划同时增量式地构建一张障碍物地图。这个场景部分受到DARPA城市挑战赛的推动,挑战赛中车辆必须无碰撞地导航到停车场。下面描述的路径规划算法由斯坦福赛车组的机器人Junior在城市挑战赛(DARPA 2007)中使用。Junior(图1)在复杂的一般路径规划任务中展现完美的性能,其中很多任务涉及倒车,例如停车场导航、执行掉头以及处理阻塞道路和十字路口,其在现代PC上典型的完整重新规划时间为50-300ms。
针对自由导航领域开发的实用路径规划器的主要挑战之一来自于所有机器人控制空间以及轨迹是连续的,这导致一个复杂的连续变量优化的问题。关于路径规划搜索算法的很多先前工作(2001年Ersson和Hu、2002年Koenig和Likhachev、2007年Nash等人)致力于研究离散状态空间的快速算法,但是那些算法往往生成非平滑的路径,并且一般不满足车辆的非完整约束。保证运动学可行性的另外一种方法是连续坐标系下的正向搜索,例如使用快速探索随机树(RRTs)(1996年Kavraki等人、1998年LaValle、2007年Plaku、Kavraki和Vardi)。使得这种连续的搜索算法对在线实现实用的关键在于高效地引导启发式函数。另外一种方法是直接将路径规划问题转化为控制或者参数化曲线空间中的非线性优化问题(2006年Cremean等人),但是实际上由于存在局部极小值,很难保证这类算法快速收敛。
本文算法基于上述讨论的现有工作,并由两个主要阶段组成。第一步在连续坐标系下使用启发式搜索,这保证计算的轨迹具有运动学可行性。尽管缺少理论上最优的证明,但是实际上这第一步通常生成一条位于全局最优邻域内的轨迹。第二步使用共轭梯度(CG)下降来局部地提高解的质量,其生成的路径至少是局部最优的,但是通常也达到全局最优。
另一个实际的挑战为针对路径代价函数的设计,以产生期望的驾驶行为。该困难来源于这样一个事实,我们想要获得长度上接近最优的路径,但是同时要求路径平滑且与障碍物保持合适的距离。一种惩罚车辆接近障碍物的常用方式为使用势场(1983年Andrews和Hogan、1986年Khatib、1984年Pavlov和Voronin、1985年Miyazaki和Arimoto)。然而,如很多研究者(1990年Tilove、1991年Koren和Borenstein)所观察到,势场的缺陷之一在于它们在狭窄的通道中创建高势场区域,从而使得不能有效地穿过那些通道。为了解决这个问题,我们引入一种基于工作空间几何结构重新缩放的势场,它支持狭窄通道中精确导航,同时在更开阔区域中有效地推动车辆远离障碍物。
混合状态A*搜索
本文方法的第一阶段将众所周知的A^{*}算法的一种变体应用于车辆的3D运动学状态空间,但是修改了状态更新规则,该规则在A^{*}的离散搜索节点中捕获连续状态数据。如传统的A^{*}一样,离散化搜索空间,但与传统的A^{*}不同,传统A^{*}只允许访问栅格的中心,而本文的混合状态A^{*}将每个栅格与车辆的一个连续3D状态相关联,如图2所示。
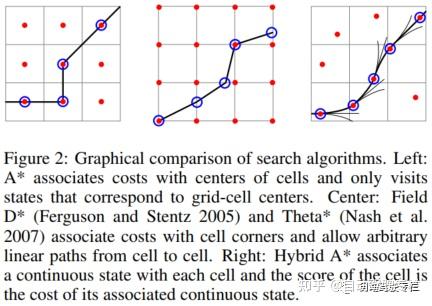
如上所述,由于混合状态A^{*}合并了在离散空间中占据相同栅格的连续坐标系下状态,因此它不能够保证找到最小代价的解。然而,结果路径能够保证是可行驶的(而不是像标准A^{*}情况下是分段线性的)。此外,实际上混合A^{*}的解通常位于全局最优的邻域内,这允许我们通过本文算法的第二阶段(使用梯度下降来局部地改进路径,如下所述)来频繁地获得全局最优解。
混合状态A^{*}的主要优势体现在紧凑空间中它的行为,其中离散误差变得至关重要。本文算法规划正向和反向运动,其对反向行驶和切换运动方向做出惩罚。
A.启发函数本文搜索算法由两种启发函数引导,如图3所示。这些启发函数不依赖于混合状态A^{*}的任何性质,并且还能被应用于其它搜索方法(例如离散A^{*})。
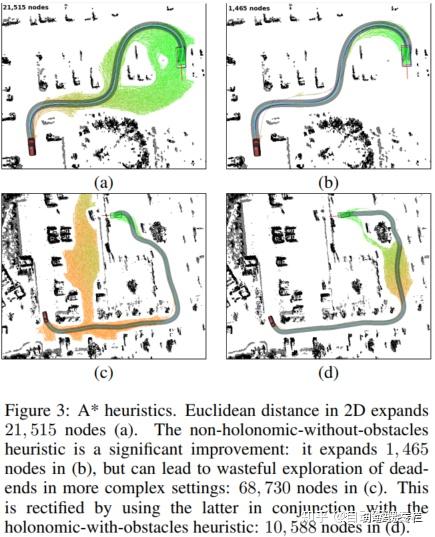
第一种启发函数(本文称为“不考虑障碍物的非完整性启发”)忽略障碍物,但是考虑车辆的非完整特性。为了计算它,假定目标状态为(x_g, y_g, theta_g) = (0, 0, 0),并且在完全没有障碍物的假设下计算从目标的某个离散邻域中的每个点(x, y, theta)到目标的最短路径(不考虑障碍物的非完整性代价)。本文使用160×160的栅格地图,其x-y方向的分辨率为1米,角度分辨率为5°。显然,这是一种可接受的启发函数。接着,使用不考虑障碍物的非完整性代价(上述)和两维的欧式距离中最大值作为本文的启发函数。这种启发函数的效果在于,它删除了以错误朝向接近目标的搜索分支。注意,由于这种启发函数不依赖于运行时的传感器信息(这是因为该启发函数不考虑障碍物),因此它能够被完全地离线预先计算,并且接着被简单地平移和旋转来匹配当前的目标。在我们的真实驾驶场景实验中,这种启发函数比直接使用两维欧氏距离代价在节点扩展数量方面给出了接近一个数量级的改进。
第二种启发函数是第一种启发函数的对偶版本,因为它忽略了车辆的非完整特性,但是使用障碍物地图通过在两维空间中执行动态规划来计算到目标的最短距离。这种启发函数的优势在于,它发现两维空间中所有的U型障碍物和死胡同,并且接着引导计算代价更昂贵的三维搜索远离这些区域。
这两种启发函数从A^{*}意义考虑是数学上合理的,所以使用这两种启发函数的最大值。
B.解析扩展
上述前向搜索使用了控制动作(转向)的离散空间。这意味着搜索将永远无法达到精确的连续坐标系下的目标状态(精度依赖于A^{*}栅格的分辨率)。为了解决这个精度问题并且进一步提高搜索速度,我们使用基于Reed-Shepp模型的解析扩展来增强搜索。在上述搜索过程中,通过使用特定的控制动作在一小段时间内(对应于栅格的分辨率)模拟车辆的运动学模型来扩展树中的节点。
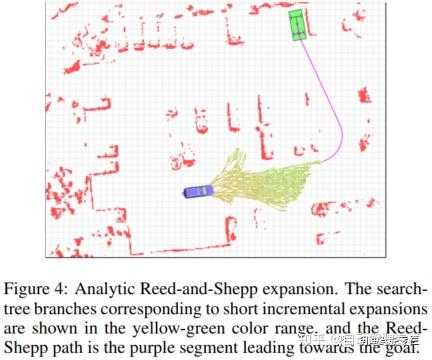
除了以这种方式生成子节点外,对于某些节点,通过计算从当前状态到目标的最优Reed-Shepp路径来生成额外的子节点(假设环境中没有障碍物)。接着,检查Reed-Shepp路径是否和当前障碍物地图发生碰撞,并且仅当路径没有发生碰撞时才将子节点加入到树中。出于计算效率的原因,不希望将Reed-Shepp扩展应用于每个节点(特别是离目标较远的节点,因为这种情况下的大多数Reed-Shepp路径都会与障碍物发生碰撞)。在本文的实现中,我们使用一种简单的选择规则,其中Reed-Shepp曲线被应用于每N个节点中的一个节点,并且N作为到目标代价的启发函数而减小(当接近目标时,将对节点进行更为频繁地解析扩展)。
Reed-Shepp扩展的搜索树如图4所示。由节点短增量扩展生成的搜索树显示为黄色到绿色的颜色范围,并且Reed-Shepp扩展显示为一条连接目标的单一紫色曲线。我们发现,搜索树的这种解析扩展在精度和规划时间方面都具有显著的优势。
使用Voronoi场的路径代价函数
本文使用如下势场(我们称为Voronoi场)来定义路径长度和车辆接近障碍物之间的平衡。Voronoi场被定义如下:
rho_V = (frac{alpha}{alpha + d_{mathcal O}(x,y)})(frac{d_{mathcal V}}{d_{mathcal O}(x,y) + d_{mathcal V}(x,y)}) frac{(d_{mathcal O} – d^{max}_{mathcal O})^2}{(d^{max}_{mathcal O})^2} tag{1}
其中,d_{mathcal O}和d_{mathcal V}分别为到最近障碍物和广义Voronoi图(GVD)边的距离,并且alpha > 0,d_{mathcal O} > 0为常数,用于控制势场的衰减率和最大有效范围。公式(1)中的表达式是对于d_{mathcal O} leq d^{max}_{mathcal O}的,否则,rho_V(x, y) = 0。
这个势场具有如下性质:i)当d_{mathcal O} geq d^{max}_{mathcal O}时,其值为零;ii)rho_V(x, y) in [0,1],并且在(x,y)空间上连续;因为不能同时满足d_{mathcal O} = d_{mathcal V} = 0;iii)只有在障碍物内时它才达到最大值;iv)只有在GVD的边上时,它才达到最小值。
Voronoi场相对于传统势场的关键优势在于,势场值与导航总共可通行区域成正比。因此,即使狭窄的开放区域也保持可通行,这不是标准的势场总是能够做到的。
图5说明了这个性质。图5a展示了Voronoi场的两维投影,并且图5b给出了对应的广义Voronoi图。注意,彼此靠近的障碍物间的狭窄通道没有被势场所阻塞,并且在它们之间总是存在一条连续的rho_V = 0的路径。将它与图5c中显示的简单朴素的势场rho(x, y) = alpha (alpha + d_{mathcal O}(x, y))^{-1}相比,该朴素的势场在障碍物之间的狭窄通道中具有高势场区域。
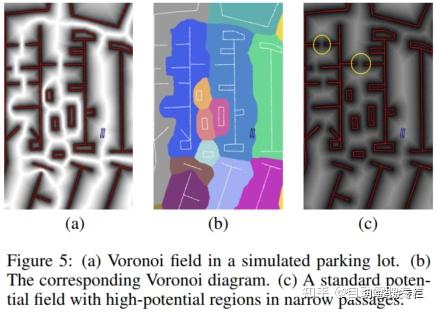
图6展示了真实停车场的Voronoi场和一条可行驶的轨迹。
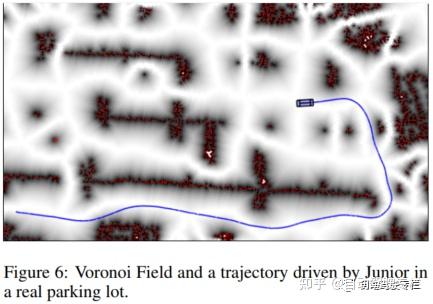
我们应该注意到,Voronoi图和势场的使用早已经在机器人运动规划中提出。例如,Voronoi图能够被用于获取可通行空间的骨架(2000年Choset和Burdick)。然而,对于具有非完整特性的汽车而言,沿着Voronoi图导航是不可能的。
导航函数(1987年Koditschek、1992年Rimon和Koditschek)和拉普拉斯势能(1990年Connolly、Burns和Weiss)也类似于我们的Voronoi场,因为他们为全局导航构建了无局部极小值的势能函数。我们没有将Voronoi场用于全局导航。然而,我们观测到,对于具有凸障碍物的工作空间,能够通过全局吸引势能来增强Voronoi场,从而产生一个无局部极小值的场,并因此适合于全局导航。
局部优化和平滑
由混合状态A^{*}产生的路径通常仍然是次优的,并且值得进一步优化。根据经验,我们发现这种路径是可行驶的,但是可能包含需要非必要转向的不正常的急转弯。因此,我们通过应用以下两阶段的优化过程来后处理混合状态A^{*}的解。在第一阶段,我们在路径顶点的坐标上构建一个非线性优化过程,从而提高解的长度和平滑性。第二阶段使用具有更高分辨率路径离散的共轭梯度的另一种迭代来进行非参数化插值。
给定一系列顶点mathbf{x}_i = (x_i, y_i), i in [1,N],我们定义一些变量:mathbf{o}_i为离顶点最近的障碍物的位置;Delta mathbf{x}_i = mathbf{x}_i – mathbf{x}_{i-1}为顶点的位移向量;Delta phi_i = lvert tan^{-1}frac{Delta y_{i+1}}{Delta x_{i+1}} – tan^{-1}frac{Delta y_i}{Delta x_i} rvert为顶点的切向角度变化。
目标函数为:begin{matrix} w_{rho} sum^N_{i = 1} rho_V(x_i, y_i) + w_o sum^N_{i = 1}sigma_o(lvert mathbf{x}_i – mathbf{o}_i rvert – d_{max}) \ + w_{kappa} sum^{N-1}_{i=1} sigma_{kappa}(frac{Delta phi_i}{lvert Delta mathbf{x}_i rvert} – kappa_{max}) + w_s sum^{N-1}_{i=1}(Delta mathbf{x}_{i+1} – Delta mathbf{x}_i)^2 end{matrix}
其中,rho_V为Voronoi场,kappa_{max}为路径的最大允许曲率(由车辆的最小转弯半径定义),sigma_o和sigma_{kappa}为惩罚函数(根据经验,发现简单的平方惩罚项就能很好工作),以及w_{rho}、w_o、w_{kappa}和w_s为权重。
代价函数的第一项有效地引导机器人在狭窄通道和宽敞通道远离障碍物。第二项惩罚与障碍物发生的碰撞。第三项约束了轨迹在每个节点处瞬时曲率的上限,并且施加车辆的非完整性约束。第四项为路径平滑性的度量。
上述代价函数的梯度以如下描述的直接方式计算。对于Voronoi场项,当d_{mathcal O} leq d^{max}_{mathcal O}时,有:frac{partial rho_V}{partial mathbf{x}_i} = frac{partial rho_V}{partial d_{mathcal O}}frac{partial d_{mathcal O}}{partial mathbf{x}_i} + frac{partial rho_V}{partial d_{mathcal V}}frac{partial d_{mathcal V}}{partial mathbf{x}_i} frac{partial d_{mathcal O}}{partial mathbf{x}_i} = frac{mathbf{x}_i – mathbf{o}_i}{lvert mathbf{x}_i – mathbf{o}_i rvert} frac{partial d_{mathcal V}}{partial mathbf{x}_i} = frac{mathbf{x}_i – mathbf{v}_i}{lvert mathbf{x}_i – mathbf{v}_i rvert} frac{partial rho_V}{partial d_{mathcal V}} = frac{alpha}{alpha + d_{mathcal O}} frac{(d_{mathcal O} – d^{max}_{mathcal O})^2}{(d^{max}_{mathcal O})^2} frac{d_{mathcal O}}{(d_{mathcal O}+d_{mathcal V})^2} frac{partial rho_V}{partial d_{mathcal O}} = frac{alpha}{alpha + d_{mathcal O}} frac{d_{mathcal V}}{d_{mathcal O} + d_{mathcal V}} frac{(d_{mathcal O} – d^{max}_{mathcal O})}{(d^{max}_{mathcal O})^2} left[ frac{-(d_{mathcal O} – d^{max}_{mathcal O})}{alpha + d_{mathcal O}} – frac{d_{mathcal O} – d^{max}_{mathcal O}}{d_{mathcal O} + d_{mathcal V}} + 2 right]
其中,mathbf{v}_i为广义Voronoi图(GVD)边缘上的点坐标的两维向量,它离顶点i最近。我们通过维护所有障碍物点和GVD边缘点的kd树并且在共轭梯度的每次迭代中更新顶点的最近邻来计算最近的障碍物mathbf{o}_i和最近的GVD边缘点mathbf{v}_i。
对于一个平方形式sigma_o的碰撞惩罚项,如果lvert mathbf{x}_i – mathbf{o}_i rvert leq d_{max},有:frac{partial sigma_o}{partial mathbf{x}_i} = 2(lvert mathbf{x}_i – mathbf{o}_i rvert – d_{max}) frac{mathbf{x}_i – mathbf{o}_i}{lvert mathbf{x}_i – mathbf{o}_i rvert}
对于顶点i处的最大曲率项,必须求它相对于影响点i处曲率的三个点(点i-1、点i和点i+1)的导数。出于计算考虑,节点i处切向角度的变化最好表示为:Delta phi_i = cos^{-1} frac{Delta mathbf{x}_i^T Delta mathbf{x}_{i+1}}{lvert Delta mathbf{x}_i rvert lvert Delta mathbf{x}_{i+1} rvert} tag{2}
曲率kappa_i = Delta phi_i / lvert Delta mathbf{x}_i rvert相对于三个节点坐标的导数为:frac{partial kappa_i}{partial mathbf{x}_i} = -frac{1}{lvert Delta mathbf{x}_i rvert}frac{partial Delta phi_i}{partial cos(Delta phi_i)} frac{partial cos(Delta phi_i)}{partial mathbf{x}_i} – frac{Delta phi_i}{(Delta mathbf{x}_i)^2} frac{partial Delta mathbf{x}_i}{partial mathbf{x}_i} frac{partial kappa_i}{partial mathbf{x}_{i-1}} = -frac{1}{lvert Delta mathbf{x}_i rvert}frac{partial Delta phi_i}{partial cos(Delta phi_i)} frac{partial cos(Delta phi_i)}{partial mathbf{x}_{i-1}} – frac{Delta phi_i}{(Delta mathbf{x}_i)^2} frac{partial Delta mathbf{x}_i}{partial mathbf{x}_{i-1}} frac{partial kappa_i}{partial mathbf{x}_{i+1}} = -frac{1}{lvert Delta mathbf{x}_i rvert}frac{partial Delta phi_i}{partial cos(Delta phi_i)} frac{partial cos(Delta phi_i)}{partial mathbf{x}_{i+1}} 其中:frac{partial Delta phi_i}{partial cos(Delta phi_i)} = frac{partial cos^{-1}(cos(Delta phi_i))}{partial cos(Delta phi_i)} = frac{-1}{(1-cos^2(Delta phi_i))^{1/2}}
其中,cos(Delta phi_i)相对于三个顶点坐标的导数最容易用正交补形式表示:a bot b = a – frac{a^T b}{lvert b rvert} frac{b}{lvert b rvert} tag{3}
引入如下归一化正交补:mathbf{p}_1 = frac{mathbf{x}_i bot (-mathbf{x}_{i+1})}{lvert mathbf{x}_i rvert lvert mathbf{x}_{i+1} rvert}, mathbf{p}_2 = frac{(-mathbf{x}_{i+1}) bot mathbf{x}_i}{lvert mathbf{x}_i rvert lvert mathbf{x}_{i+1} rvert} tag{4}
接着,能够将导数表示为:begin{matrix} frac{partial cos(Delta phi_i)}{partial mathbf{x}_i} = -mathbf{p}_1 – mathbf{p}_2 \ frac{partial cos(Delta phi_i)}{partial mathbf{x}_{i-1}} = mathbf{p}_2, frac{partial cos(Delta phi_i)}{partial mathbf{x}_{i+1}} = mathbf{p}_1 end{matrix} tag{5}
图7展示了第二次优化和平滑步骤的效果,图中红线为A^{*}的解,蓝线为由CG优化获得的路径。
使用上述CG平滑,本文获得一条比A^{*}的解平滑很多的路径,但是它仍然是分段线性的,其顶点之间存在明显的距离(在本文实现中为0.5m-1m)。这会导致物理车辆发生非常突然的转向。因此,我们使用CG解的顶点之间的插值来进一步平滑路径。很多参数化插值技术对输入中的噪声非常敏感,并且加剧了输出中的任何此类噪声(例如,由于输入顶点彼此间隔较近,因此三次样条曲线将导致输出中存在任意大的振荡)。
因此,我们使用非参数化的插值方式,通过加入新的顶点、使用CG最小化路径的曲率同时保持原始顶点固定来对路径超采样。图8a中路径的插值结果在图8b中所示。

结果
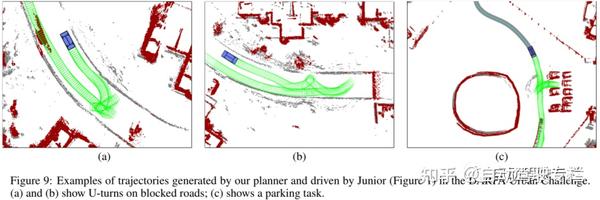
图9描述了一些在DARPA城市挑战赛中由Junior行驶的轨迹。图9a-c展示了在阻塞道路掉头的情况,图9d展示涉及停车场导航的任务。
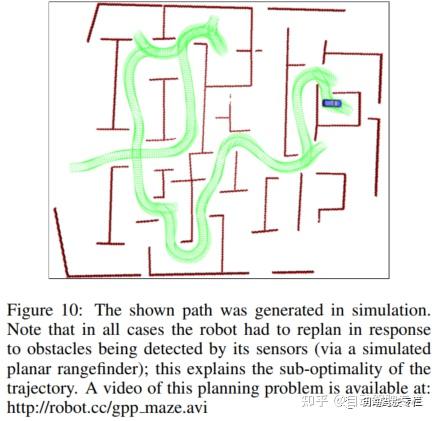
对于仿真中更复杂的迷宫类环境计算得到的解如图10所示。图10场景中当机器人增量式地检测障碍物并构建障碍物地图时进行重新规划的视频可在网址http: //http://ai.stanford.edu/ ddolgov/gpp maze.avi中找到。
本文将如下参数用于规划器:障碍物地图尺寸为160mx160m,其分辨率为0.15cm;A^{*}使用的栅格地图尺寸为160mx160mx360°,其x-y方向的分辨率为0.5m,朝向theta的分辨率为5°。包含混合A^{*}搜索、CG平滑和插值的完整重规划周期的典型运行时间为50-300ms。
发表回复