
1. 什么是联合感知预测?
1.1 自动驾驶的工作流程
传统的自动驾驶方法,是分模块进行的 [17]:
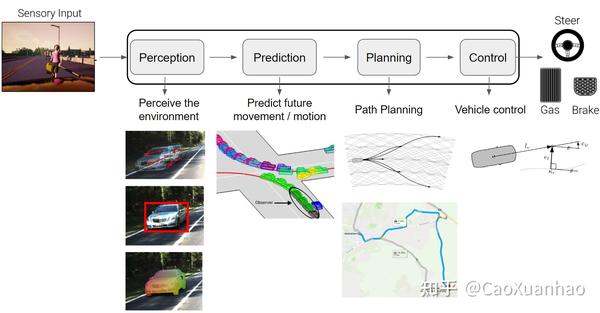
(1)感知模块:融合传感器数据,感知环境
(2)预测模块:预测物体或障碍物的未来运动轨迹
(3)规划模块:规划路径
(4)控制模块:控制汽车的运动,输出汽车运行指令
前一个模块的输出,是后一个模块的输入。开发的时候也是分别进行开发,配置不同的工程师(感知算法工程师、预测算法工程师、决策规划算法工程师。。。)
这样分模块开发的好处是:(1)速度快,能并行开发模块;(2)可解释性强,能知道每个模块的机制。
但同时也有不少弊端,比如:(1)级联式失误,因为开发每个模块的时候,默认使用前一个模块的groung truth;但实际应用上前一个模块可能会出错,导致后面模块得到了错误的输入,进而输出错误的预测,然后又导致后面的模块出错。(2)每个模块只能得到局部最优,因为每个模块的单独开发的,而不是根据自己驾驶这个终极目标进行优化,所以只能得到局部最优。
1.2 新趋势:多模块联合
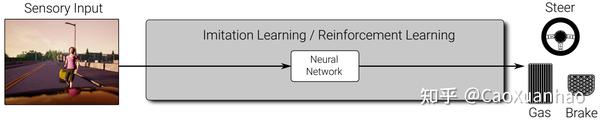
未来解决上述缺点,学术界最新的趋势是,讲其中几个模块进行合并,进行“端到端的开发(end-to-end)”。做法有很多,比如(1)强化学习、模仿学习 [18]:输入传感器数据,直接输出汽车运行指令
(2)端到端的运动预测(end-to-end motion prediction)/ 联合感知预测 [1,2,3,4,5,6,7,8,13,14,15]:联合开发感知和预测模块
 (3)端到端的规划(end-to-end planning) [9,11,12,16]:联合开发感知+预测+规划模块
(3)端到端的规划(end-to-end planning) [9,11,12,16]:联合开发感知+预测+规划模块
这种端到端的方法有很多好处,比如前一个模块的信息可以帮助后一个模块的计算、可以直接利用前一个模块的特征以避免重复计算。
在这篇文章里,我主要介绍一下第2种方法,端到端的运动预测。这任务以多时间的传感器数据作为输入,输出未来时刻的运动预测(包括物体检测、语义分割、instance flow等)。其中instance flow的效果图大概长这样:
2. 联合感知预测的工作流程
总的来说,也可以分为encoder-decoder流程:
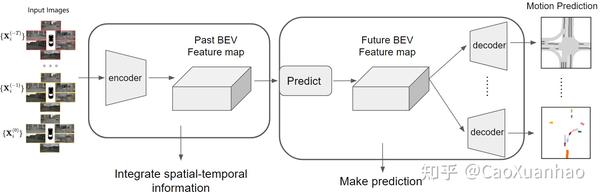
(1)先用一个encoder做数据预处理,融合多视角、多时间信息以形成一个综合的特征表示。然后(2)用一个decoder,用一个预测机制预测未来的特征表示,再解码成未来的运动预测。下面分别阐述各个主要成分(黑体部分)
2.1 数据预处理
先来说说传感器数据是图像的情况,然后雷达、多传感器融合的情况也就很类似了。
一般汽车的图像感知数据是多视角(6个相机,感知360°全景信息)、时间序列的, I_t = {X^1_ t , …, X^n_ t }, t=1,…,T
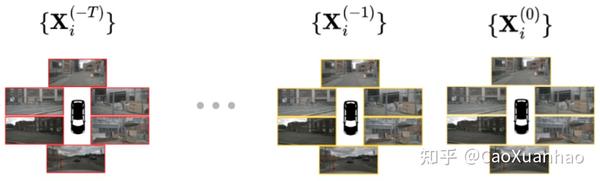
所以需要先融合各个视角的信息,再融合不同时间下的信息,方便后面做预测。
对于融合多视角,常用方法有(具体内容可以参考原论文,我这里就简单描述一下):
(1)LSS [19]
将各个视角下的二维图像抬升倒3D点云,再压缩成二维鸟瞰图(Bird’s eye view,BEV)。
(2)注意力机制 [20]
一般沿用BEVFormer开创的spatial cross-attention方法:先用CNN或者Transformer encode提前图像数据特征,再训练一个query,用注意力机制提取图像特征信息。
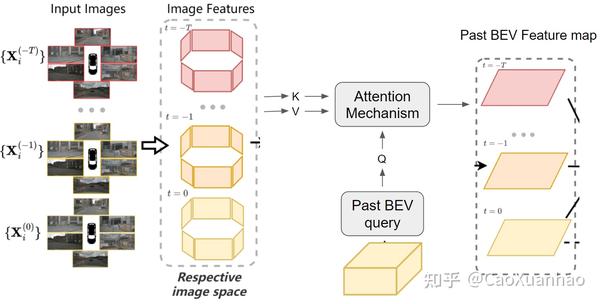 一般这个过程会循环做几次,即拿前一次输出的bev feature map做query,再提取图像特征信息,再输出更新的bev feature map
一般这个过程会循环做几次,即拿前一次输出的bev feature map做query,再提取图像特征信息,再输出更新的bev feature map
对每一个时刻的多视角图,都这样处理,我们就能得到数据的时序特征表示 S = [B^{(0)}, B^{(−1)}, …, B^{(−T )}] ∈ R^{(T +1)×X×Y ×C}
对于雷达数据、多传感器数据 [1,4,8,11,13,14],只是这一步有区别。用不同的方法预处理完不同数据、融合完不同的数据之后,也是得到一个时序特征表示 S = [B^{(0)}, B^{(−1)}, …, B^{(−T )}] ,然后下面的流程就完全一样了。
2.2 融合多视角、多时间信息
但上面只是简单融合了一下多视角信息,并且把时序特征拼接起来,所以还需要进一步处理。常用方法有:
(1)3D 卷积 [1,2,9]
因为时序特征表示是个4维数据,所以可以用3D卷积。
(2)2D 卷积 (仅限雷达数据)[8]
3D 卷积计算量有点大,所以可以把时间维度也当成特征维度,这样得到的时序特征表示就是个3维的了 S = [B^{(0)}, B^{(−1)}, …, B^{(−T )}] ∈ R^{(C(T +1))×X×Y} ,就可以用正常的CNN了。
(3)自注意力机制 [3]
这里可以像BEVFormer一样用temporal cross-attention,也可以用MotionNet、TBP-Former中的Spatial-Temporal Pyramid Network:
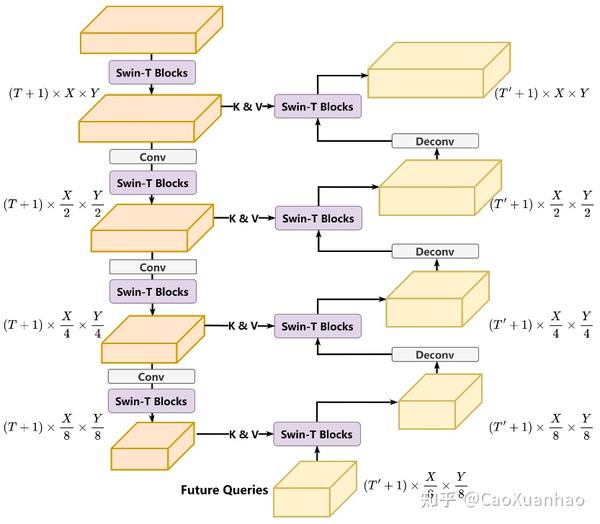
对每个通道数据 S_c = [B^{(0)}, B^{(−1)}, …, B^{(−T )}]_c ∈ R^{(T +1)×X×Y } ,可以单独取出来作为特征图,然后用自注意力机制就能处理。
处理完之后,我们就能得到一个综合的特征表示,可以是一个特征图表示所有过去时间的图像 S=s in R^{H” times W” times C_{out}} (当我们用(1)或(2)的方法处理时),也可以是每一个时刻都有一个特征表示 S ∈ R^{(T +1)×X×Y ×C} (当我们用(3)的方法处理时)。
其实这一步做完之后,就可以直接做感知类任务了(比如当前时刻的语义分割、检测等),在特征表示后面加上几个任务相关的decoder head就行,但如果我们要做预测类任务,那么还要再预测未来时刻的特征表示。
2.3 预测未来的特征表示
接下来就要预测未来时刻的时序特征表示了。常用方法有:
(1)2D 卷积 [1]
直接接一个过去时间的特征表示,训练一个CNN,输出未来时刻的时序特征表示,然后端到端训练。但这种方法效果略差。
(2)RNN类方法 [2,4,9]
RNN类方法是很适合做时序任务了。输入一个过去时间的特征表示,依次输出每个未来时刻的时序特征表示。很多论文能把这块完出花来,加了很多复杂的技巧,但我这里就不过多介绍了。
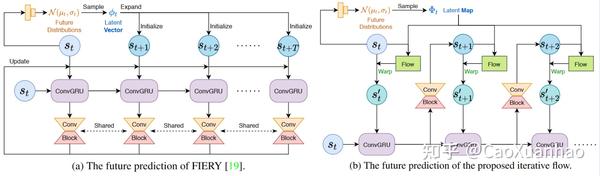
一般这种方法也很喜欢结合一下概率预测机制
(3)注意力机制 [3]
训练一个query,通过注意力机制,从过去的时序特征图中提取信息:
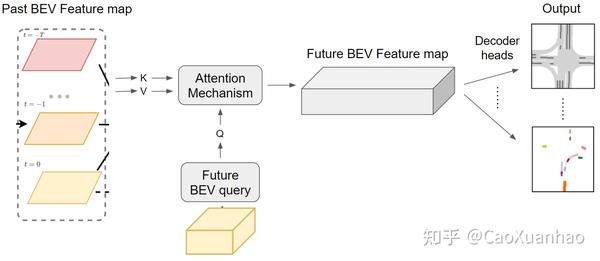 顺便提一下也有用概率预测机制做预测的 [2,6,7,10],也很有意思。
顺便提一下也有用概率预测机制做预测的 [2,6,7,10],也很有意思。
因为未来物体的运动可能是不确定的,有一定的随机性,所以用概率方法建模也有合理性。神奇的是,经过一系列复杂的数学推导以及做了一些假设之后,概率的方法往往能简化成 在原来的预测机制中额外加一个输入,这个输入是从一个“未来概率分布(模拟了未来各种可能的概率分布)”中抽的一个样本(包含了未来信息)。
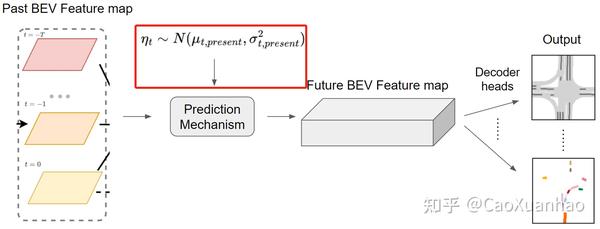 数学推导有点复杂,内容比较多,但很精彩,我打算另外单独写一篇文章介绍!(未完待续)
数学推导有点复杂,内容比较多,但很精彩,我打算另外单独写一篇文章介绍!(未完待续)
2.4 解码成各种任务
有了未来的特征表示,再那之后接一些decoder heads就行(比如detection heads),然后就能去做各种预测任务了。
常见的预测任务有:
semantic segmentation, instance centerness and instance offset, and future instance flow ([2])
… + HD map prediction ([3])
object detection (for generating tracklets from sequential detection) ([1])
future sementic segmentation, depth and optical flow ([9])
2.5 模型评估
数据集
没有现成的数据集来评估,所以一般是把其它数据集改造一下来用。比如自动驾驶中常用的NuScenes [21]、Lyft [22] 数据集,它们都是给单个模块评估用的,比如感知模块是用当前时刻的图像来做当前时刻的语义分割,那么我们就可以用过去时刻的图像做输入,然后对未来时刻的图像做语义分割。
评估标准(evaluation metric)
常用的有(1)Intersection over Union (IoU):未来每一帧图像的语义分割,(2)Video Panoptic Quality (VPQ):度量未来各个帧的物体检测结果的连续性
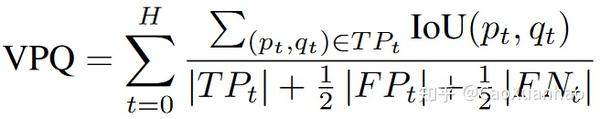
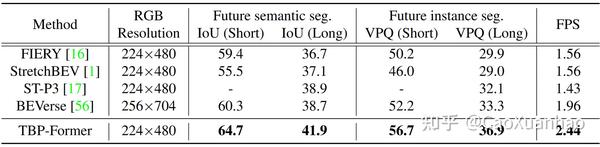
评估结果
目前的SOTA似乎是TBP-Former [3],一个用注意力机制做特征融合和预测的模型。
Reference
[1] Fast and Furious: Real Time End-to-End 3D Detection, Tracking and Motion Forecasting with a Single Convolutional Net.
[2] FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras.
[3] TBP-Former: Learning Temporal Bird’s-Eye-View Pyramid for Joint Perception and Prediction in Vision-Centric Autonomous Driving.
[4] PnPNet: End-to-End Perception and Prediction with Tracking in the Loop.
[5] FISHING Net: Future Inference of Semantic Heatmaps In Grids.
[6] BEVerse: Unified Perception and Prediction in Birds-Eye-View for Vision-Centric Autonomous Driving.
[7] StretchBEV: Stretching Future Instance Prediction Spatially and Temporally.
[8] IntentNet: Learning to Predict Intention from Raw Sensor Data.
[9] ST-P3: End-to-end Vision-based Autonomous Driving via Spatial-Temporal Feature Learning.
[10] Implicit Latent Variable Model for Scene-Consistent Motion Forecasting.
[11] Perceive, Predict, and Plan: Safe Motion Planning Through Interpretable Semantic Representations.
[12] Learning Interpretable End-to-End Vision-Based Motion Planning for Autonomous Driving with Optical Flow Distillation.
[13] Deep Multi-Task Learning for Joint Localization, Perception, and Prediction.
[14] MotionNet: Joint Perception and Motion Prediction for Autonomous Driving Based on Bird’s Eye View Maps.
[15] Perceive, Interact, Predict: Learning Dynamic and Static Clues for End-to-End Motion Prediction.
[16] VAD: Vectorized Scene Representation for Efficient Autonomous Driving.
[17] Computer Vision for Autonomous Vehicles: Problems, Datasets and State of the Art.
[18] A Survey of End-to-End Driving: Architectures and Training Methods.
[19] Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D.
[20] BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers.
[21] nuScenes: A multimodal dataset for autonomous driving.
[22] One Thousand and One Hours: Self-driving Motion Prediction Dataset.
发表回复