
原文链接:https://zhuanlan.zhihu.com/p/2013011855552042379

「靠“做梦”实现SOTA建图」
在熙熙攘攘的商场、人来人往的车站,机器人如何在充满动态变化的真实世界里自由穿行?这是SLAM技术始终在挑战的难题。
一旦有人从机器人面前走过,它可能把你当成永久障碍物,在地图上留下一块”幽灵区域”;更严重的是,在自动驾驶或紧急救援等场景,这种对动态物体的”误解”可能导致灾难性后果。
针对这一挑战,现有方法处理动态物体,通常是将其识别后直接屏蔽——这是一种”做减法”的思路,代价是丢失了大量有效的图像信息。
而来自香港科技大学(广州)的李昊昂团队、上海交通大学王贺升老师、慕尼黑工业大学(TUM)、萨拉戈萨大学的研究者们提出的Dream-SLAM则另辟蹊径:
它不屏蔽动态物体,而是通过生成模型将其”替换”为与地图时刻一致的虚拟版本,让前景信息也能参与定位配准。屏蔽是做减法,Dream-SLAM是做替换——减法让信息变少,替换让信息保持完整。
他们创新地引入”做梦”(Dreaming)机制,让系统不仅能看懂当下,更能”梦见”那些看不见、甚至尚未发生时空中的场景,从而在复杂动态环境中实现鲁棒定位、高质量建图与高效探索。
01 机器人如何“做梦”?
Dream-SLAM的“做梦”能力,并非天马行空的幻想,而是基于强大的生成模型(扩散模型)构建的一套严谨的推理机制。
它主要包含两种“梦境”:一种是“回顾之梦”,用于理解过去;另一种是“预见之梦”,用于规划未来。
这两种梦境共同构成了其核心方法论,贯穿于定位、建图和探索的全过程。
- 所谓“回顾之梦”,是指通过生成模型,凭空创造出“跨时空图像”(cross-spatio-temporal image)。想象一下,在t+1时刻,相机观察到了一个运动的人,但此时的3D地图是在t时刻建立的,人和景物的位置已经发生了变化。这种不一致性会导致定位失败。
Dream-SLAM的做法是,让系统“梦见”一张特殊的图片:它描绘的是t时刻的场景内容,但却是从t+1时刻的相机视角进行观察的。这张“梦”出来的图片,完美对齐了过去(t时刻的地图)与现在(t+1时刻的观测),为机器人提供了处理动态物体的关键线索。 - 而“预见之梦”,则是在探索未知环境时发挥作用。当机器人需要决定下一步去哪里时,传统方法只能基于已建好的地图做决策,非常短视。
Dream-SLAM则会大胆“想象”,在那些待探索的路径点上放置虚拟相机,并利用生成模型“梦见”从这些虚拟视角可能看到的景象,包括房间的结构、家具的摆放等。这些“梦境”被整合进现有地图,形成一张更完整的“未来地图”,机器人得以在此基础上做出更长远、更高效的探索规划。
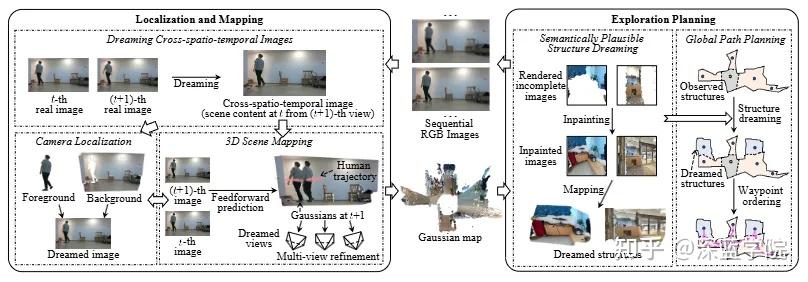
图1 | Dream-SLAM系统全貌。整个框架由两大核心模块构成。(a) 定位与建图模块:系统通过”做梦”生成跨时空图像,并以此构建额外的3D-2D前景约束,有效补偿动态物体带来的噪声干扰;同时,一个前馈网络负责同步重建静态背景与动态前景的逐像素高斯表示,并借助跨时空图像与真实图像的多视角约束对高斯进行精化。(b) 探索规划模块:系统”梦见”未观测区域的语义合理结构,将梦境信息与真实观测融合,从而规划出具有全局视野的远见路径,实现高效而彻底的环境探索。
02 技术亮点
基于“回顾之梦”的动态场景鲁棒定位
传统SLAM在动态场景中定位精度差,根源在于无法处理动态物体(如行人)造成的前景与背景模型之间的冲突。
Dream-SLAM通过生成“跨时空图像”,巧妙地解决了这个问题。这张“梦”出来的图像为定位提供了额外的、关于动态前景的几何约束。如此一来,系统不仅能利用稳定的静态背景信息,还能充分利用动态前景信息,使得相机位姿估计在复杂动态场景下的准确性和鲁棒性都得到了大幅提升。
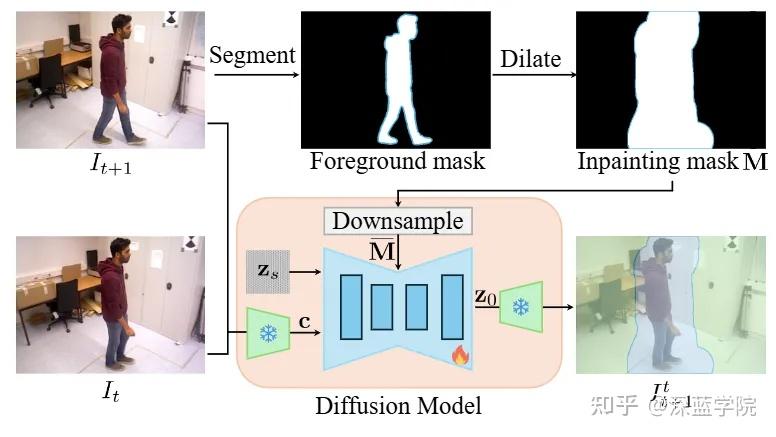
统一前景与背景的高质量3D建图
除了定位,高质量建图同样重要。
Dream-SLAM采用3D高斯溅射(Gaussian Splatting)作为3D场景的表达方式,并设计了一个前馈网络来直接、高效地预测场景的3D高斯表示。
更关键的是,它利用“梦”出的跨时空图像和真实图像进行多视角联合优化,从而精细化每一个3D高斯基元的形状和颜色。这种方法不仅能同时重建静态背景和动态前景,而且重建质量极高。相比其他方法要么无法重建前景、要么重建质量粗糙,Dream-SLAM生成的地图在视觉上清晰、锐利,细节丰富,达到了SOTA水平。
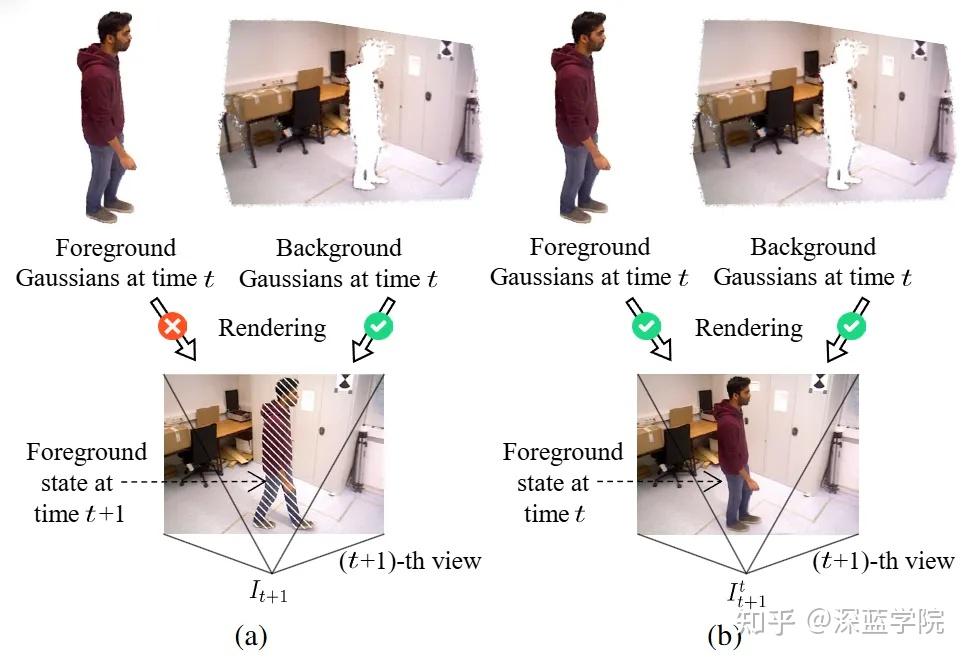
图3 | 跨时空图像如何让定位”看见”动态物体。(a) 传统定位方法只依赖静态背景估计相机位姿,动态前景信息被完全丢弃。(b) Dream-SLAM则同时利用动态前景与静态背景——通过将t时刻的高斯渲染结果与”梦”出的跨时空图像对齐,该图像描绘的是从第(t+1)帧相机视角观察到的t时刻场景,从而为定位提供了更丰富、更鲁棒的约束信号。
基于“预见之梦”的远见探索规划
主动SLAM的核心是“看得更远”。
Dream-SLAM的“预见之梦”机制赋予了其无与伦比的远见。通过在未知道路上“脑补”出合理的场景结构,它打破了传统探索方法的信息壁垒。系统不再是“摸着石头过河”,而是在一张“预言地图”的指引下行动。
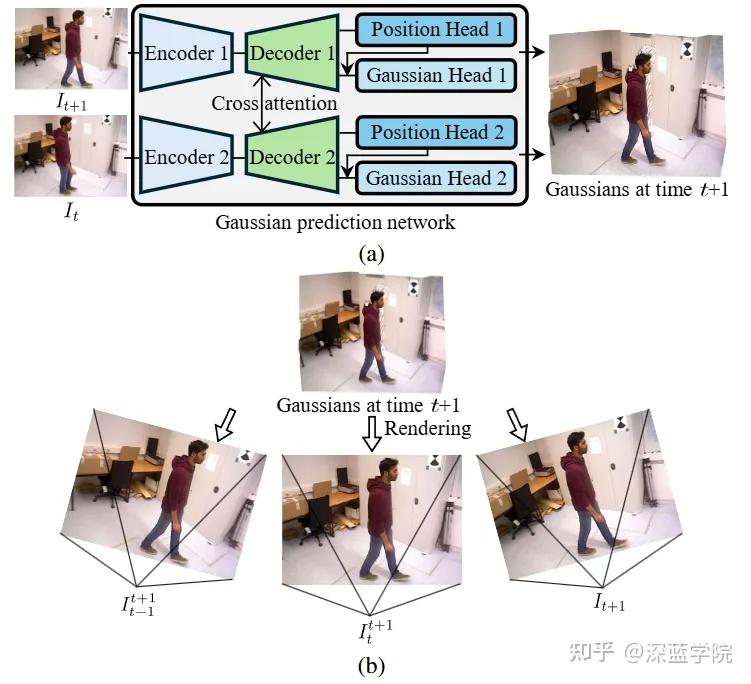
图4 | 基于3D高斯的”预见之梦“。(a) 给定相邻两帧图像,前馈网络同时预测两个时刻的动态高斯表示,实现对动态场景的高效建模。(b) 为进一步提升精度,系统利用多张描绘同一场景内容、但分别来自前一帧、当前帧和后一帧视角的图像(包括真实图像与”梦”出的跨时空图像),对高斯进行多视角光度约束下的联合精化,从而获得更连贯、更高质量的3D场景表示。
这种基于“梦境”的规划,使得机器人能够避免陷入死胡同,规划出更短、更高效的全局路径。在Gibson和HM3D等大规模仿真环境中的实验证明,Dream-SLAM的探索效率(以覆盖率为指标)平均达到了96.8%,远超其他方法,同时探索路径长度平均缩短了30%以上。
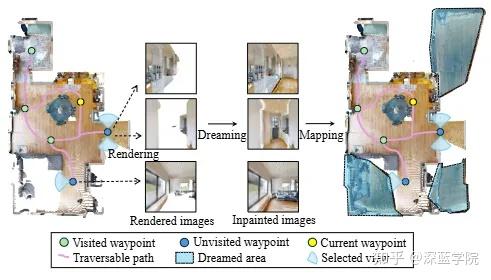
图5 | “预见之梦”——在未知区域提前建图。在尚未到达的路径点处,系统放置虚拟相机从多个角度渲染当前不完整的场景,并筛选出合适的视角图像。随后,扩散模型对这些图像中的缺失区域进行语义合理的修复,再将修复结果反推为3D高斯表示,融合进现有地图。经过这一”梦境补全”过程,机器人得以在真正抵达之前,就拥有一张更完整的环境结构图,为长远规划提供有力支撑。
03 实验与表现
Dream-SLAM的卓越性能在多个公开数据集和自采集数据上得到了充分验证。无论是定位精度、建图质量还是探索效率,它都展现出了碾压性的优势。
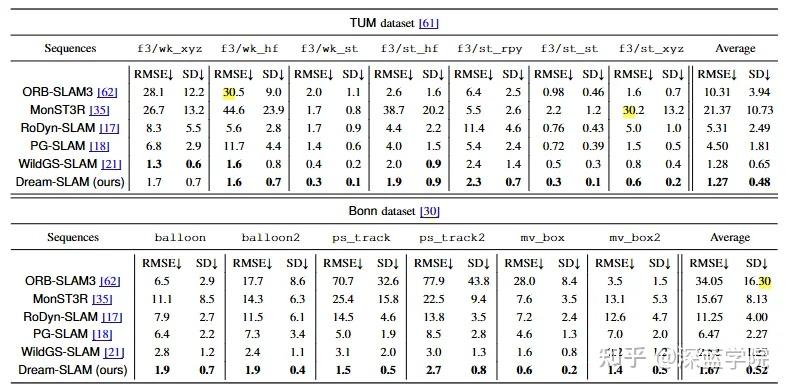
在建图质量方面,如下图所示,在TUM动态数据集的一个典型场景中,其他方法(如MonST3R、WildGS-SLAM)的重建结果要么无法处理动态前景(a),要么背景模糊、前景丢失(b),而PG-SLAM虽然能同时重建,但质量较低(c)。相比之下,Dream-SLAM(d)能够清晰、完整地重建整个动态场景,无论是静态的桌椅还是动态的人,都栩栩如生。

图7 | 建图质量一目了然——TUM数据集动态场景新视角渲染对比。四种方法在同一动态序列上的建图效果差异显著:MonST3R(a)受限于点云表示,无法生成照片级真实感渲染;WildGS-SLAM(b)完全丢失了动态前景的重建;PG-SLAM(c)虽能同时重建前景与背景,但部分区域渲染质量偏低;Dream-SLAM(d)不仅完整重建了动态前景与静态背景,渲染质量也全面最优,细节清晰、场景连贯。
在探索效率方面,下图直观地展示了Dream-SLAM与顶尖主动SLAM方法ActiveSplat的对比。在相同的探索时间内,Dream-SLAM(下图)覆盖的地图面积明显更大,探索路径(紫色轨迹)也更为直接、高效。最终,Dream-SLAM用更短的时间(1164秒 vs 1536秒)和更短的路径完成了100%的探索,充分证明了其“远见”带来的巨大优势。
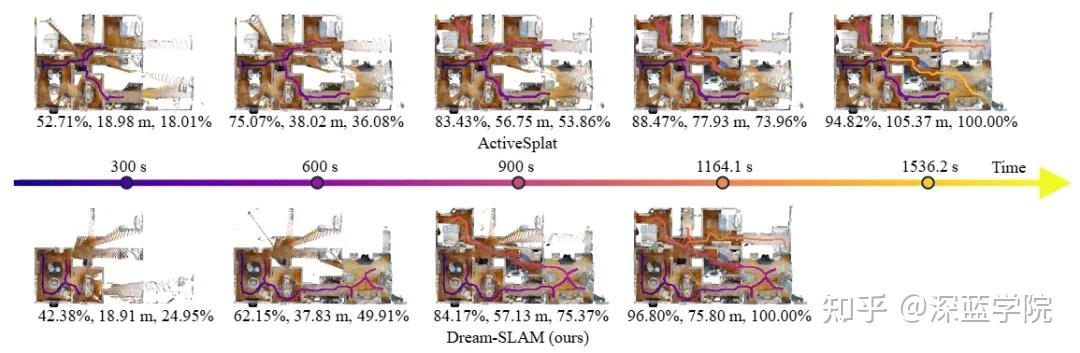
图8 | 探索效率的差距一目了然。图中展示了ActiveSplat与Dream-SLAM在HM3D数据集同一场景序列上的探索进度俯视对比。每张地图下方的三个数字依次代表:场景覆盖率、已行驶路径长度、以及已行驶路径占总路径的比例;轨迹颜色则反映了探索的时间消耗。可以清晰看到,在相同时间节点下,Dream-SLAM的覆盖面积始终领先,且最终以更短的路径、更少的时间完成了100%的探索,而ActiveSplat则需要更长的迂回才能达到同等覆盖效果。
此外,论文还通过详尽的消融实验证明了“做梦”机制的不可或缺性。一旦移除“回顾之梦”(用于定位)或“预见之梦”(用于规划),系统的各项性能指标均出现显著下降,这雄辩地证明了“做梦”正是Dream-SLAM成功的关键所在。

图9| “做梦”对建图质量的贡献——消融实验对比。图中对比了在Bonn与TUM数据集的典型动态序列上,引入跨时空图像前后的高斯地图渲染效果。可以明显看出,去掉”做梦”机制后,动态前景区域出现模糊、残影等伪影;而加入跨时空图像的多视角约束后,场景细节更加清晰,动态物体的重建也更为完整准确,有力证明了”做梦”机制对建图质量提升的关键作用。
04 总结与延伸
Dream-SLAM的提出,代表了SLAM技术从“被动感知”向“主动想象”的重大范式转变。它通过引入生成模型赋能的“做梦”机制,将看似分离的定位、建图和探索任务无缝地统一在一个框架下,为解决动态环境下主动SLAM的根本性难题提供了一个优雅且强大的解决方案。这项工作不仅在技术指标上取得了突破,更在理念上为具身智能的发展带来了深刻启示:未来的智能体或许不仅需要感知世界,更需要具备“想象”世界的能力。
这项技术未来有望应用于家庭服务机器人、仓储物流、自动驾驶乃至元宇宙的构建中,让机器人在复杂多变的真实世界里更加智能、自主。当然,如何让“梦境”更逼真、更可控,如何处理更长时程、更复杂的动态变化,将是未来值得继续探索的方向。
REF
论文标题: Dream-SLAM: Dreaming the Unseen for Active SLAM in Dynamic Environments
发表回复