
原文链接:https://zhuanlan.zhihu.com/p/1988914910986515369
当下的视觉语言模型(VLM)已经能相当不错地“看懂”世界,但大多时候,它们看到的还是一个“静止”的世界。一旦物体动起来,尤其是在三维空间中发生位置和姿态的复杂变化时,模型就开始“犯迷糊”了。这种理解物体在3D空间中随时间演变的能力,我们称之为动态空间推理
(Dynamic Spatial Reasoning, DSR),它是迈向具身智能、自动驾驶和AR等前沿应用的关键一环。
然而,训练VLMs掌握DSR能力,长期以来面临着一个巨大的瓶颈:缺乏大规模、高质量的“4D感知”训练数据。
为了系统性地解决这一难题,来自香港大学和腾讯PCG ARC Lab的研究者们联手推出了一个名为 DSR-Suite 的一站式解决方案。它不仅包含一个能从海量真实视频中自动挖掘和构建DSR问答数据的流水线,还设计了一个全新的几何选择模块
(Geometry Selection Module, GSM),能巧妙地将4D几何信息注入现有VLM,同时不影响其通用能力。

- 论文标题: Learning to Reason in 4D: Dynamic Spatial Understanding for Vision Language Models
- 论文地址: https://arxiv.org/abs/2512.20557
- 代码仓库: https://github.com/TencentARC/DSR_Suite(已开源)
- 机构: 香港大学,腾讯 PCG ARC Lab
VLM的“动态盲区”与研究动机
想象一下,让一个AI看一段视频:一辆汽车在路口左转,同时一个行人在远离汽车。要准确描述这个过程,AI不仅要识别出“汽车”和“行人”,还要理解它们各自的运动轨迹、相对方向、速度变化。这就是典型的DSR任务。
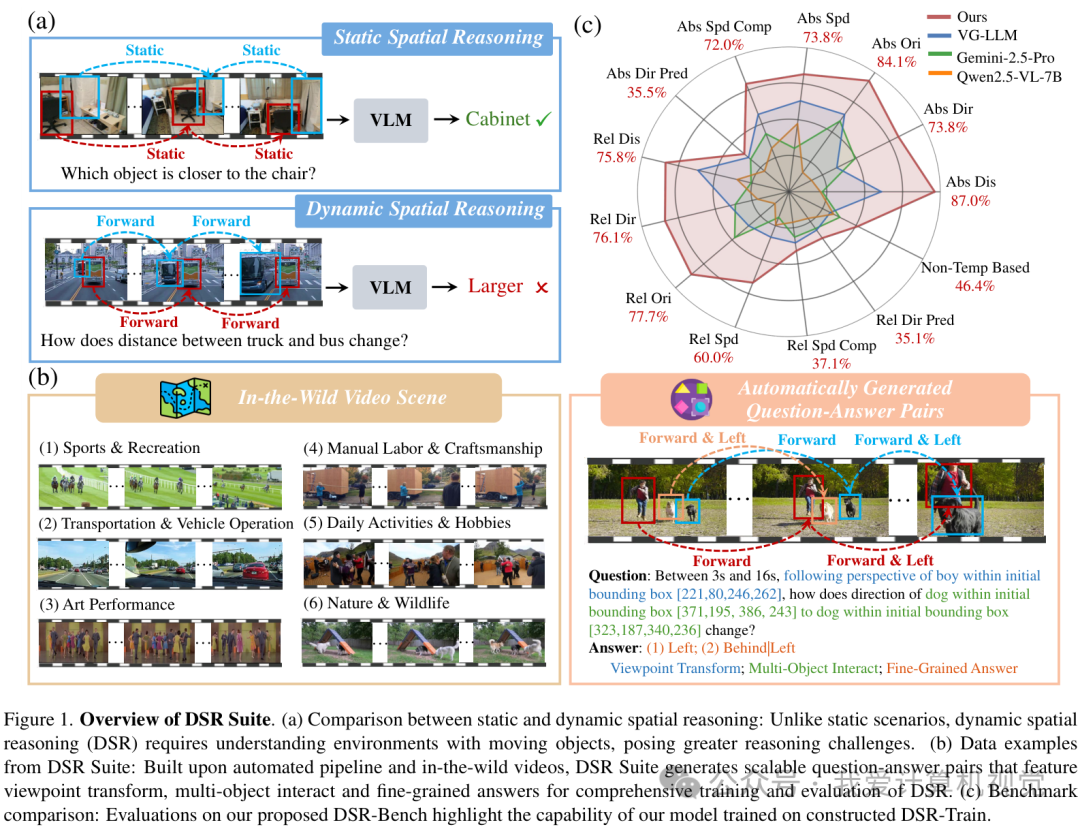
如上图(a)所示,与静态场景推理不同,DSR要求模型理解一个充满动态变化的环境,这对推理能力提出了巨大挑战。现有的大多数工作要么集中在静态的3D场景,要么只考虑非常短时的运动,难以捕捉长时程、多物体、多视角的复杂动态。究其原因,正是因为缺少一个能够规模化产出高质量DSR训练数据的“工厂”。
为此,DSR-Suite应运而生,它旨在从数据集、基准和模型三个层面,全面提升VLM的动态空间推理能力。
DSR-Suite:全自动的4D数据工厂
DSR-Suite的核心是一套全自动的数据生成流水线,能够将普通、无标注的“野生”视频(in-the-wild videos)转化为包含丰富DSR知识的多项选择题。整个流程分为三个阶段,如下图所示:
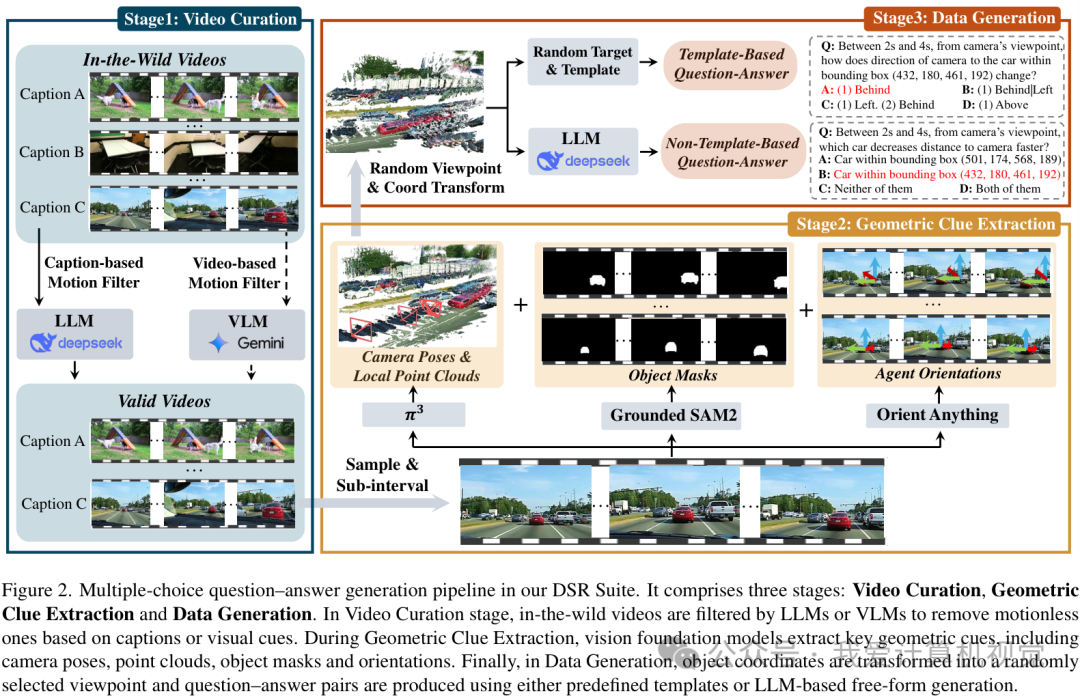
- 视频筛选 (Video Curation) :首先,从大规模视频库(如Koala-36M)中,利用大模型(如Gemini-2.5-Pro)根据视频内容或字幕,自动筛选出那些包含显著物体运动的视频片段,淘汰掉静态或运动不明显的视频。
- 几何线索提取 (Geometric Clue Extraction) :这是最关键的一步。对于筛选后的视频,流水线会调用一系列先进的视觉基础模型,从视频中提取丰富的几何与运动信息,包括:
- 相机位姿和局部点云 (通过模型)
- 物体掩码和3D轨迹 (通过Grounded SAM2进行跟踪和分割)
- 物体朝向 (通过Orient Anything估计)
这些信息共同构成了一个场景的4D时空图景,为后续生成有意义的问答对奠定了基础。
- 数据生成 (Data Generation) :有了精确的几何线索,就可以生成各种DSR问题了。这个阶段有几个亮点:
- 多样化的视角:问题可以从“相机视角”提出,也可以从视频中某个“运动物体”(agent)的视角提出,甚至可以是某个时刻的“绝对视角”,这迫使模型学会视角转换。
- 丰富的题型:涵盖相对距离、相对方向、朝向、速度、速度对比、方向预测等多种类型。
- 细粒度的程序化答案:答案不是简单的“变近了”,而是描述整个过程的“先保持不变,然后变远”,极大地考验模型对连续动态的理解能力。
通过这套流水线,研究者构建了用于模型训练的DSR-Train(包含50K问答对)和经过人工精校的评测基准DSR-Bench。

GSM:给VLM装上“几何选择器”
有了数据,如何让模型高效地“吃”进去?
过去的思路通常是把提取出的几何特征(比如一大堆点云token)直接与视觉特征融合,但这往往会引入大量噪声和无关信息,导致模型在DSR任务上性能提升的同时,在其他通用视频理解任务上“翻车”。
为此,论文提出了一个即插即用的轻量级模块——几何选择模块(Geometry Selection Module, GSM)。
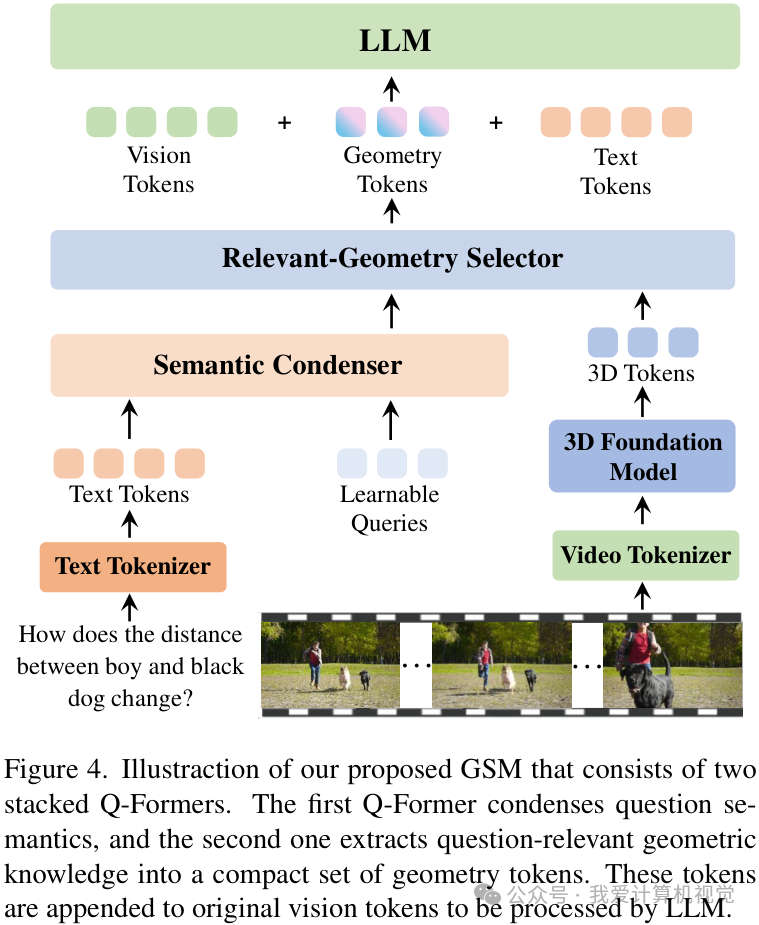
GSM的设计非常精妙,它像一个智能信息过滤器,其核心是两个串联的Q-Former:
- 第一级 Q-Former (语义压缩器) :接收用户提出的文本问题,将其“阅读并理解”,然后把问题的核心语义压缩成一小组固定数量(例如32个)的“查询向量”(Query)。
- 第二级 Q-Former (相关几何选择器) :带着上一级生成的“查询向量”,去庞大的几何特征库(由等模型生成)中进行检索。它只会把与问题语义相关的几何信息提取出来,编码成一组同样数量的、紧凑的“几何Token”。
最后,这组被问题“精炼”过的几何Token,会和原始的视觉Token、问题Token一起,被送入VLM的大语言模型部分进行最终的推理和回答。
这个“先问后找”的机制,完美地解决了信息过载的问题。它确保了只有对回答问题有用的几何知识才会被模型看到,从而在显著提升DSR能力的同时,最大程度地保护了模型原有的通用性能。
实验结果:性能全面超越
DSR-Suite的效果如何?研究者们在基于Qwen2.5-VL-7B
模型上集成了GSM模块,并在DSR-Train上进行了训练。
在专门为DSR任务设计的DSR-Bench上,该模型取得了惊人的成绩。
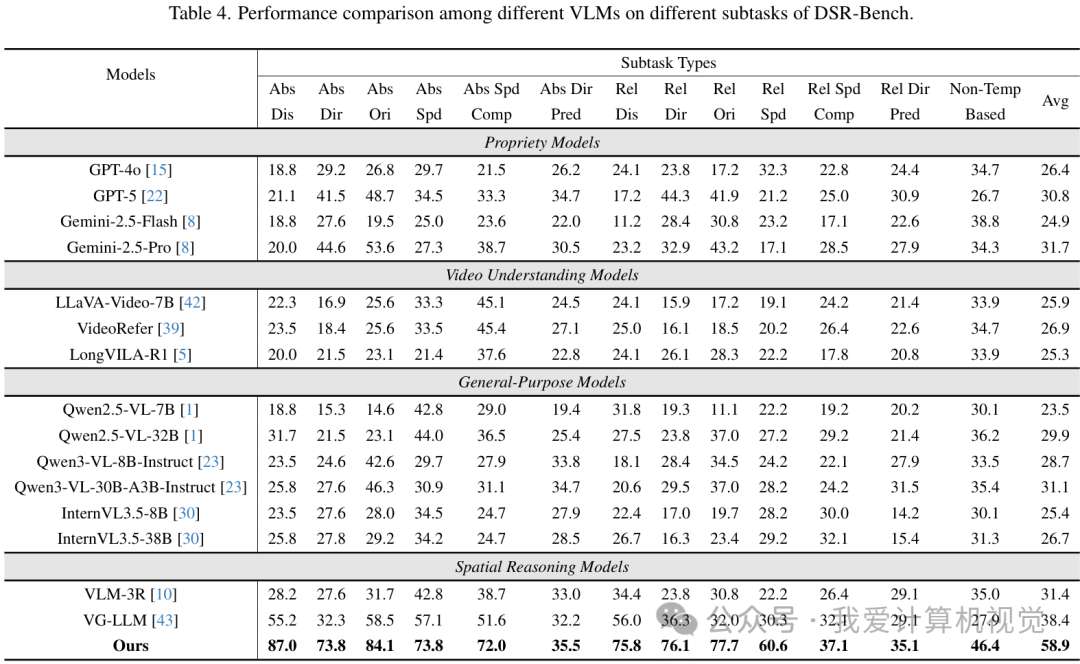
从上表可以看出,搭载了GSM的模型取得了58.9%的平均准确率,不仅远超所有未针对DSR优化的通用VLM(包括GPT-4o的26.4%和Gemini-2.5-Pro的31.7%),也优于其他为空间推理设计的模型。这充分证明了DSR-Suite的有效性。
GSM模块的优越性
为了证明GSM不是简单的“大力出奇迹”,消融实验给出了答案。
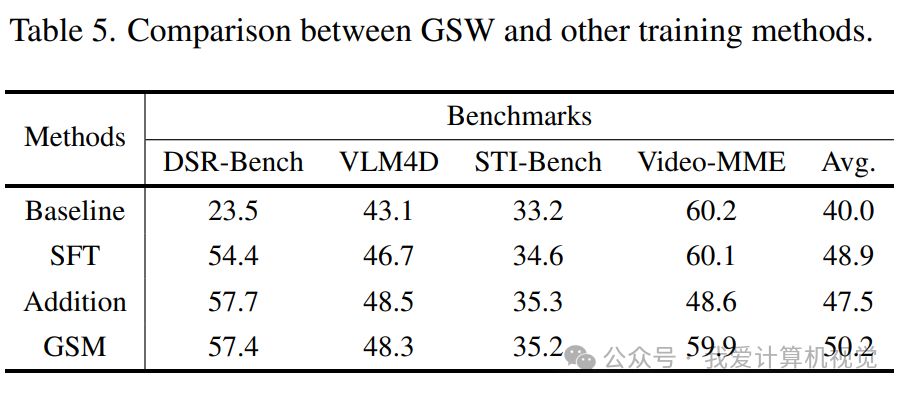
与直接微调(SFT)和暴力添加几何特征(Addition)相比,GSM的优势显而易见:
- 在DSR-Bench上,GSM (57.4%) 和Addition (57.7%) 的性能远超SFT (54.4%),证明了引入几何知识的必要性。
- 但在通用视频理解基准Video-MME
- 上,Addition方法的性能从60.2暴跌至48.6,而GSM方法则稳定在59.9,几乎没有损失。
这有力地证明了GSM的选择性信息注入机制,是实现“专才”与“通才”兼备的关键。
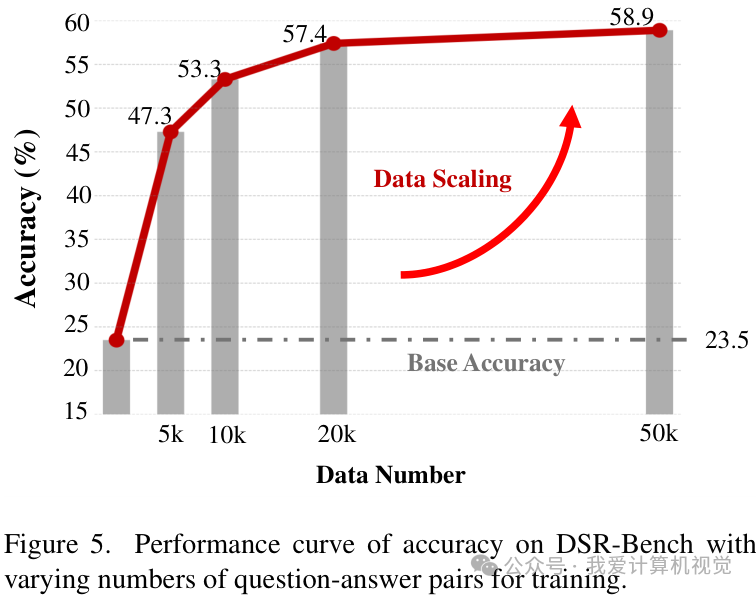
数据的力量
此外,实验还表明,DSR-Train数据集具有极佳的可扩展性。随着训练数据量的增加,模型性能稳步提升。
开源实践指引
好消息是,作者已经将DSR-Suite完全开源。这意味着社区的研究者和开发者们可以:
- 访问并使用DSR-Train数据集来训练自己的模型。
- 在DSR-Bench上评测和对比不同模型的DSR能力。
- 将GSM模块集成到自己的VLM架构中。
虽然论文没有给出详细的硬件配置,但考虑到基础模型是Qwen2.5-VL-7B,并使用了多个视觉基础模型,复现完整的训练和数据生成流水线预计需要一块高性能的GPU(如A100或3090/4090级别)。感兴趣的读者可以访问项目主页,获取更多技术细节和使用指南。
一点思考
这项工作最令人兴奋的地方,在于它为解决VLM的“动态盲区”问题,提供了一个系统化、可扩展且高效的范式。通过自动化的数据工厂(DSR-Suite)和智能的知识注入模块(GSM),研究者们不仅让模型学会了看“懂”4D时空,更重要的是,探索出了一条如何在不牺牲通用性的前提下,为大模型精准“补课”的有效路径。
随着DSR-Suite的开源,我们可以预见,未来将有更多VLM具备强大的动态空间推理能力,这无疑会加速具身智能、自动驾驶等领域的发展,让AI离真正理解和交互于物理世界更近一步。
发表回复