
原文链接:https://zhuanlan.zhihu.com/p/1987107314377974556
自动驾驶的终极目标是构建一个能够无缝将原始传感器输入映射为驾驶决策的集成系统。为了克服传统模块化管道信息丢失和误差累积的局限性,也是为了追求更接近人类的驾驶智能,学术界和工业界正经历一场从模块化向数据驱动的端到端(End-to-End, E2E)范式的转变。
今天介绍的这篇综述论文来自上海交通大学AutoLab和滴滴出行Voyager研究团队。这篇论文通过对200多篇相关论文的全面梳理,首次提出了“通用端到端自动驾驶”(General End-to-End, GE2E)的概念,并系统性地将现有方法划分为三大范式:传统端到端(Conventional E2E)、以VLM为中心(VLM-centric E2E)以及混合端到端(Hybrid E2E)。
这篇综述不仅深入剖析了这三大范式的架构设计、学习策略和核心差异,还通过在nuScenes、CARLA、NAVSIM等主流基准上的横向对比,揭示了各范式的优劣势及未来潜力。如果你正深陷于自动驾驶技术路线的选择困难症中,这篇综述绝对是你的破局指南。

- 论文标题: Survey of General End-to-End Autonomous Driving: A Unified Perspective
- 机构: 上海交通大学, 滴滴出行
- 论文地址: https://www.techrxiv.org/doi/full/10.36227/techrxiv.176523315.56439138/v1
- 项目主页/代码仓库: https://github.com/AutoLab-SAI-SJTU/GE2EAD
什么是GE2E?三大范式一图看懂
论文首先定义了“通用端到端”(GE2E)的概念:无论架构中是否包含大语言模型(VLM),只要是通过单一整体模型将原始传感器输入处理为规划轨迹或控制动作的范式,都属于GE2E。
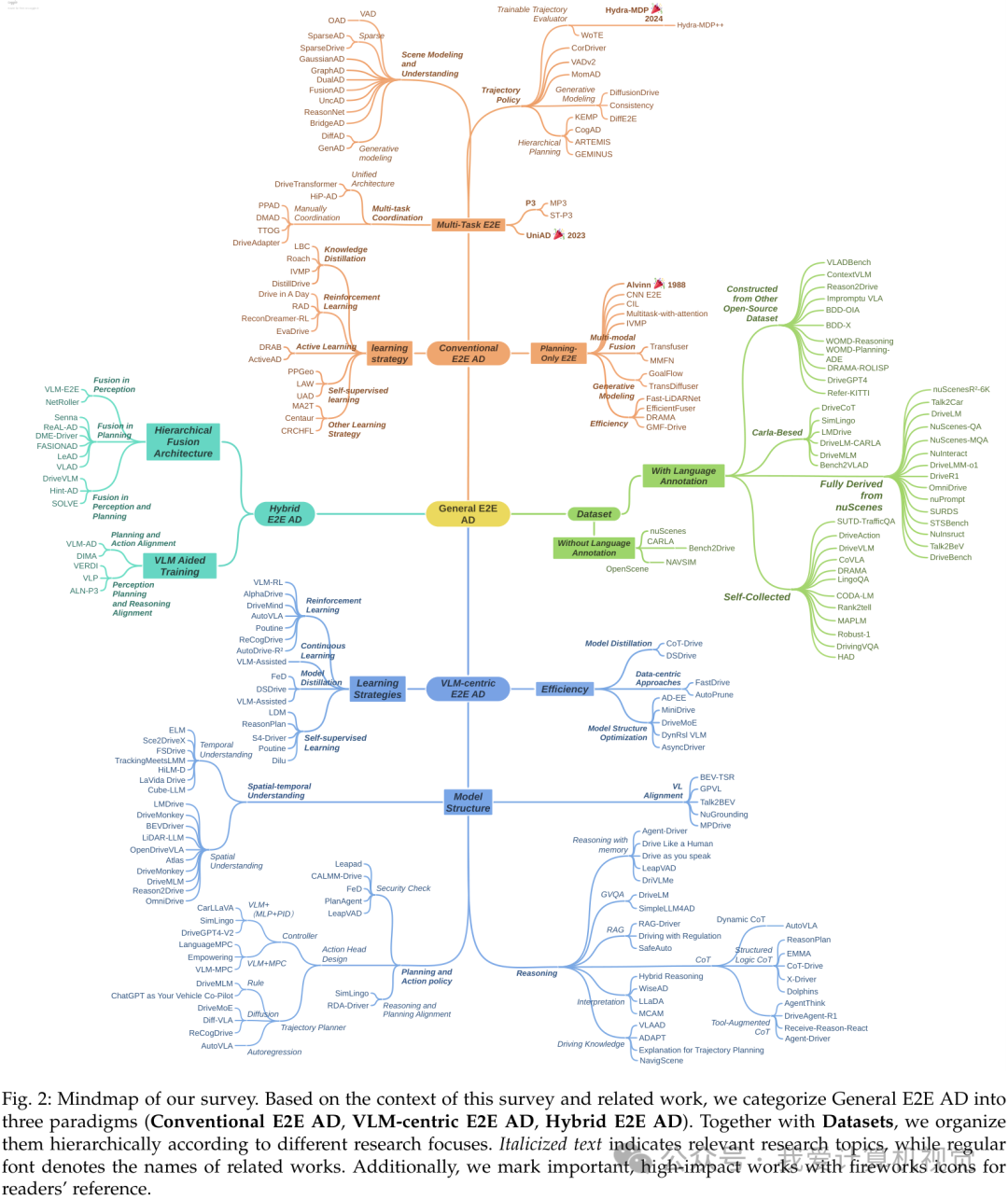
基于此,作者将现有技术路线清晰地划分为三类:
- 传统端到端(Conventional E2E AD):通过联合优化专门的模块(如感知、预测、规划)来直接映射输入到输出。它可以进一步细分为“纯规划(Planning-only)”和“多任务(Multi-task)”两类。
- 以VLM为中心(VLM-centric E2E AD):利用预训练大模型(VLM/LLM)的世界知识和推理能力,将多模态数据投影到语言空间进行决策,强调泛化性和可解释性。
- 混合端到端(Hybrid E2E AD):结合前两者的优势,既利用VLM的高层推理指导,又保留传统E2E的低层执行能力,形成“慢思考、快行动”的系统。
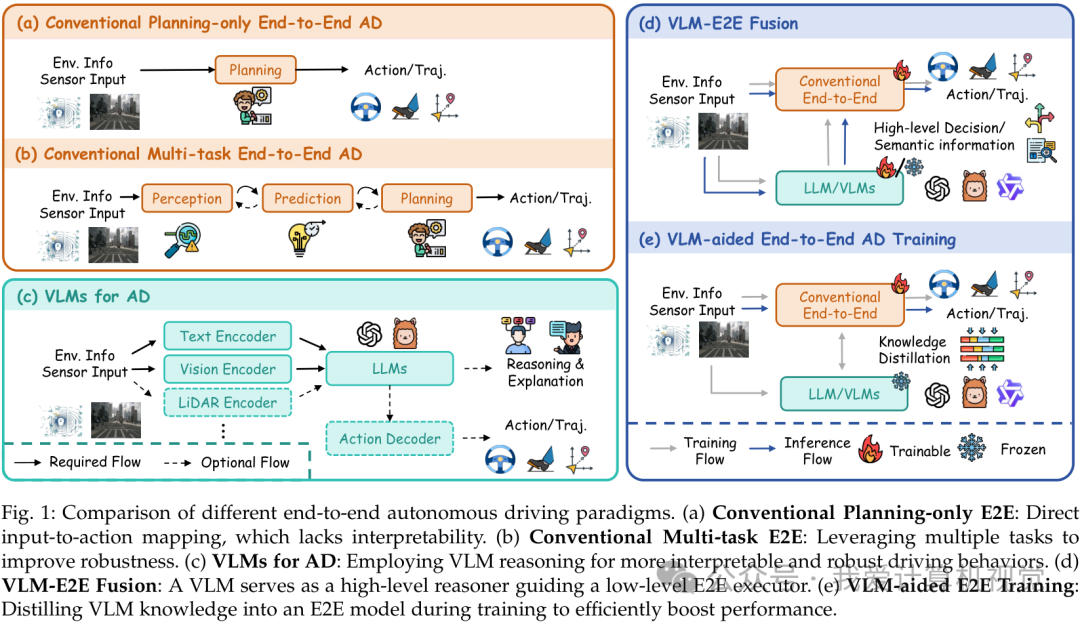
传统端到端:从黑盒拟合到多任务协同
传统E2E方法早期多采用简单的CNN网络直接回归控制指令(如ALVINN, P3),虽然缓解了误差传播,但往往缺乏可解释性且难以处理复杂场景中的多模态不确定性。为了解决这些问题,研究者们引入了多任务学习架构。
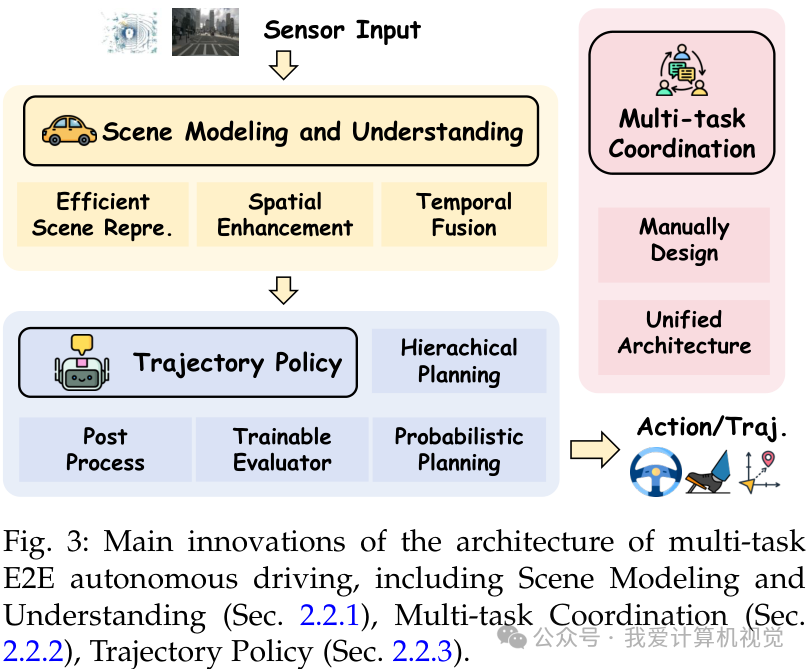
场景建模与理解
除了基本的感知任务,现代E2E模型更注重构建高效的场景表征:
- 稠密表征:如UniAD利用BEVFormer构建稠密BEV表征,但计算量大。
- 稀疏表征:SparseAD和SparseDrive直接对对象实例进行建模,显著降低了计算负担。
- 时空推理:GraphAD利用图模型描述交互,ReasonNet利用记忆库存储历史信息,增强对动态环境的理解。
轨迹生成策略
为了避免简单模仿学习带来的“因果混淆”和安全隐患,研究者提出了多种策略:
- 后处理优化:利用预测的占用网格(Occupancy)或成本函数优化轨迹。
- 概率规划:VADv2从概率分布中采样动作,DiffusionDrive利用扩散模型生成多模态轨迹,在NVIDIA 4090上实现了45 FPS的实时推理。
- 分层规划:CogAD模仿人类的“粗到细”认知机制,先进行意图规划再生成具体轨迹。
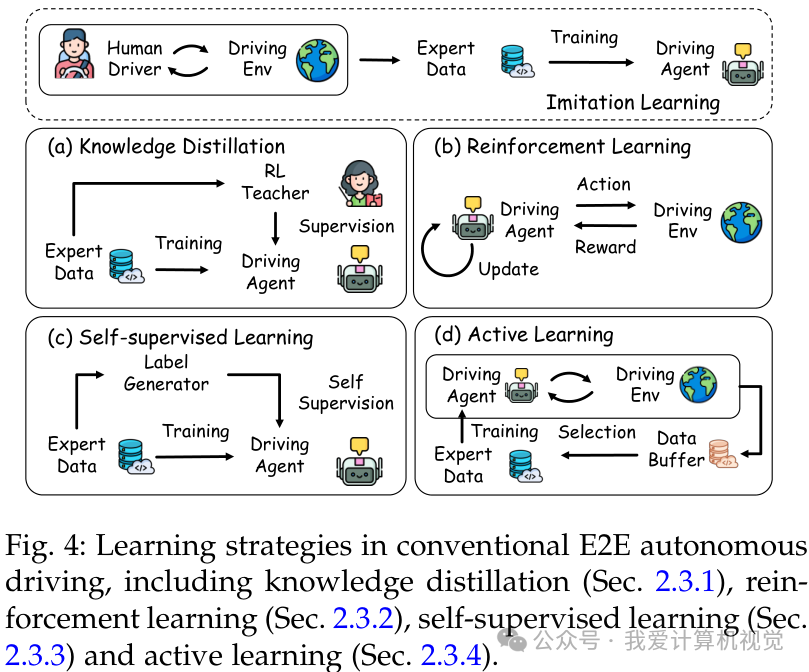
学习策略的进化
为了突破数据瓶颈,除了模仿学习(Imitation Learning),还涌现了多种高级策略:
- 知识蒸馏:LBC和Roach利用特权专家(Privileged Agent)指导学生模型。
- 强化学习:Drive in a Day引入RL进行探索,ReconDreamer-RL利用世界模型构建数字孪生进行大规模试错。
- 自监督学习:PPGeo和UAD利用大规模无标签数据进行预训练,UAD甚至实现了零3D标注下的SOTA性能。
VLM-centric:让自动驾驶拥有“认知大脑”
传统E2E模型因缺乏世界知识,在长尾场景(Corner Case)面前往往束手无策。VLM-centric范式试图通过引入大模型的推理能力来填补这一“认知鸿沟”。
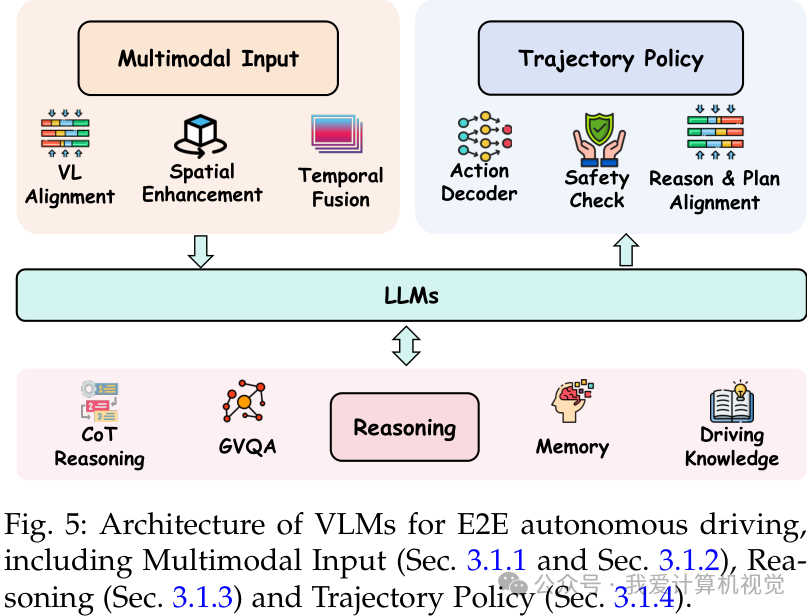
视觉-语言对齐
核心挑战在于如何将驾驶场景的视觉特征映射到LLM的语义空间:
- 直接投影:使用MLP等轻量级投影器(如LMDrive)。
- 查询压缩:使用Q-Former等结构提取关键信息(如DriveMLM)。
- 任务驱动对齐:GPVL和Driving with LLMs设计了专门的预训练任务,将BEV特征或数值信息转化为LLM可理解的语言token。
推理与思维链(Chain-of-Thought)
VLM赋予了系统深度的因果推理能力:
- 结构化逻辑CoT:DriveLM和SimpleLLM4AD将驾驶任务分解为感知、预测、规划的问答链(Graph VQA),使决策过程透明化。
- 工具增强CoT:Agent-Driver让LLM作为调度器调用外部工具(如专门的规划器),结合了各种模型的长处。
- 动态CoT:AutoVLA根据场景复杂度动态调整推理深度,平衡效率与性能。
效率优化
针对VLM推理延迟高的问题,研究者提出了多种方案:
- 模型蒸馏:CoT-Drive将大模型的推理知识蒸馏到轻量级边端模型中。
- 结构优化:FastDrive通过结构化数据输入消除了冗余信息,实现了10倍的推理加速。
Hybrid E2E:强强联合的终极形态?
混合范式旨在融合VLM的“慢思考”与传统E2E的“快直觉”。
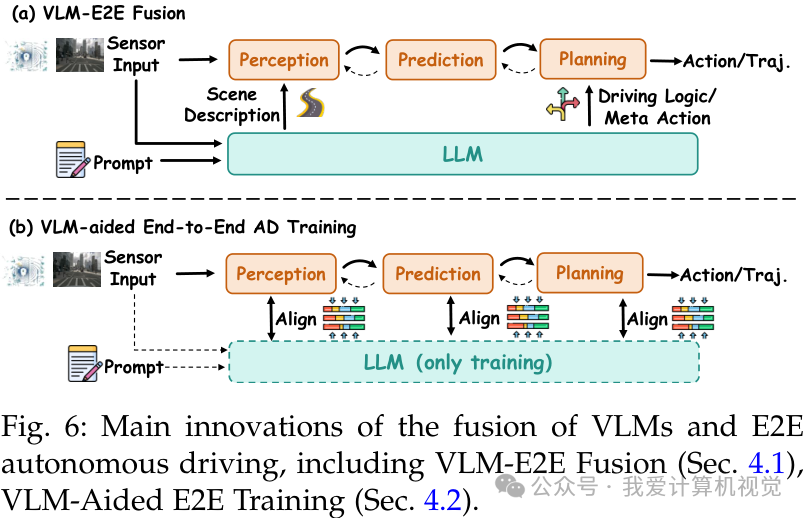
在线分层融合
- 规划层融合:VLM作为高层决策者生成“元动作”(如“向左变道”),指导传统E2E模型生成具体轨迹。DriveVLM实现了感知输出的双向验证和轨迹提示。
- 感知层融合:VLM-E2E利用VLM生成的注意力提示来增强BEV特征。
离线知识迁移(VLM辅助训练)
这种方式利用VLM作为“教师”在训练阶段指导E2E模型,推理时则仅使用E2E模型,实现了零推理成本的性能提升。
- 对齐与蒸馏:ALN-P3提出了全栈对齐框架,强制E2E模型的中间特征与VLM的语言表征一致,确保决策逻辑的合理性。
谁是王者?主流基准性能大比拼
论文在nuScenes、Bench2Drive、CARLA和NAVSIM等基准上进行了详尽的横向对比。
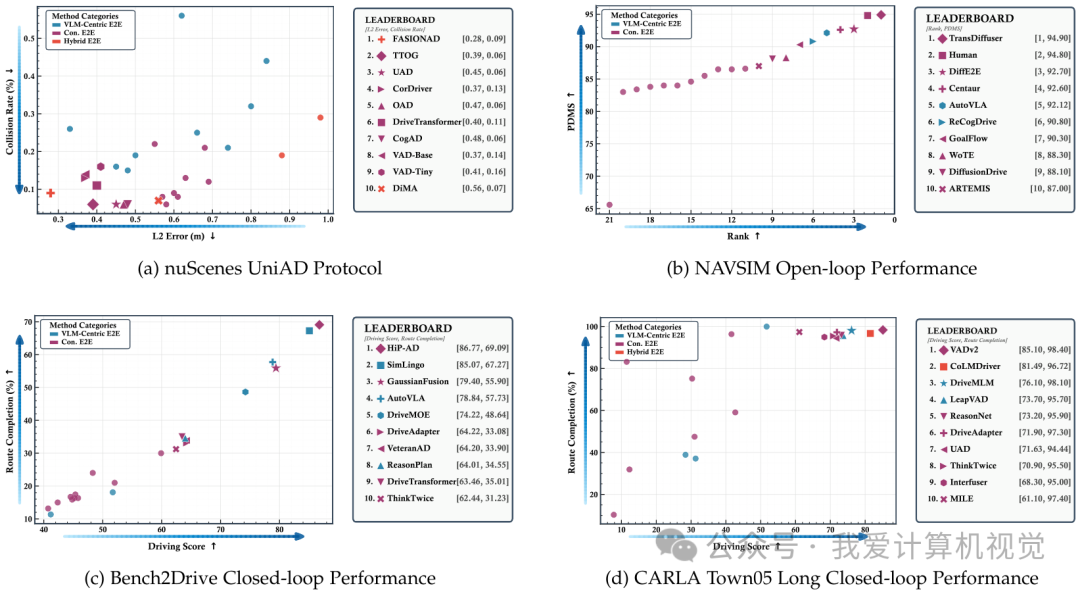
- nuScenes (Open-loop):传统端到端方法(如TTOG, UAD) 虽然占据了榜单前列的大部分位置,证明了其在数值轨迹预测方面的优势 ;但目前性能最佳的方法(Top 1)实际上属于混合端到端(Hybrid E2E)范式 。
- NAVSIM (Open-loop simulation):令人惊讶的是,传统端到端方法(如TransDiffuser) 在PDMS评分上甚至超过了人类驾驶员,展现了强大的潜力 。
- Bench2Drive (Closed-loop):尽管SOTA方法表现出了一定的鲁棒性,但Bench2Drive中最好的方法路网完成率仍未超过70% ,处理多样化和长程路线仍然是一个关键瓶颈。
- CARLA (Closed-loop):传统E2E方法在Town05 Long基准上仍占据主导地位,说明在需要精细操作控制的任务中,传统方法依然具有优势。
值得注意的是,ActiveAD仅利用30%的nuScenes数据就达到了全数据集的性能,凸显了在自动驾驶领域数据质量优于数量的重要性。
展望未来:通往AGI之路
论文最后指出了GE2E面临的四大挑战:长尾分布、可解释性、安全保证和实时效率,并提出了未来的四个关键研究方向:
- 强化学习(RL):从模仿学习转向RL,利用世界模型进行大规模低成本试错。
- 基础模型(Foundation Models):在海量通用数据上预训练,解决Long-tail问题。
- Agent系统:模仿人类大脑皮层和小脑的协作,构建分层的Agent体系。
- 世界模型(World Models):作为自监督学习的引擎,利用海量无标签视频数据驱动模型进化。
发表回复