
原文链接:https://zhuanlan.zhihu.com/p/1980329406397428133

- 论文标题:Artemis: Structured Visual Reasoning for Perception Policy Learning
- 论文作者:Wei Tang, Yanpeng Sun, Shan Zhang, Xiaofan Li, Piotr Koniusz, Wei Li, Na Zhao, Zechao Li
- 作者机构:南京理工大学、新加坡科技设计大学(SUTD)、阿德莱德大学、百度、Data61-CSIRO、商汤
- 论文链接:Artemis: Structured Visual Reasoning for Perception Policy Learning
- 项目主页:https://vi-ocean.github.io/projects/artemis/
- 代码仓库:https://github.com/WayneTomas/Artemis
关于名字:Artemis(阿尔忒弥斯) 是古希腊神话中的狩猎女神,以其敏锐的视觉和百发百中的箭术著称。
拒绝“纸上谈兵”:视觉感知需要“空间化”思维
近年来,大语言模型(LLM)的推理能力突飞猛进,尤其是通过强化学习(RL)激发的“思维链”(Chain of Thought)能力,让模型学会了像人类一样通过多步推理解决复杂问题。受此启发,研究人员开始尝试将这种基于语言的推理引入到多模态大模型(MLLM)的视觉感知任务中。然而,现实却有些“骨感”:实证观察发现,这种纯语言的中间推理往往会降低感知任务的性能。
为什么会这样?南京理工大学、SUTD等机构的研究者在最新论文 Artemis 中给出了答案:核心问题不在于“推理”本身,而在于“推理的形式”。现有的方法让模型在非结构化的语言空间中进行语义推理,而视觉感知本质上需要在 空间和以对象为中心(Object-Centric) 的空间中进行推理。
简单来说,当模型面对“找出最矮的运动员”这样的指令时,如果只是在语言层面“碎碎念”(如下图(b)所示),往往会产生大量与图像内容无关的幻觉,导致定位错误。而人类的感知过程是 结构化视觉推理(Structured Visual Reasoning):先扫描场景,定位相关区域,再逐步聚焦目标(如下图(c)所示)。

Artemis的动机。对比当前的感知策略模型与人类感知。(a) 查询:找出最矮的运动员。(b) 感知策略模型依赖于未接地的语言推理,导致定位错误。(c) 人类执行结构化视觉推理,逐步细化注意力以识别正确的运动员。
为了解决这一痛点,作者提出了 Artemis,这是一个基于强化学习的感知策略学习框架。Artemis 不再让模型“空谈”,而是要求它提供结构化的视觉推理证据。每一个中间推理步骤都必须由一个 (标签, 边界框) 对来表示,直接捕捉可验证的视觉状态。
这种设计使得中间状态可以被显式追踪,推理质量可以直接被监督,从而避免了语言推理带来的歧义。Artemis 基于 Qwen2.5-VL-3B 构建,不仅在视觉定位(Grounding)和检测任务上表现强劲,更展现出了惊人的泛化能力——在零样本的情况下,就能搞定计数和几何感知任务!
Artemis框架:让模型学会“结构化思考”
Artemis 的核心在于利用 群组相对策略优化(Group Relative Policy Optimization, GRPO
) 算法,在后训练(Post-training)阶段引入结构化视觉推理。
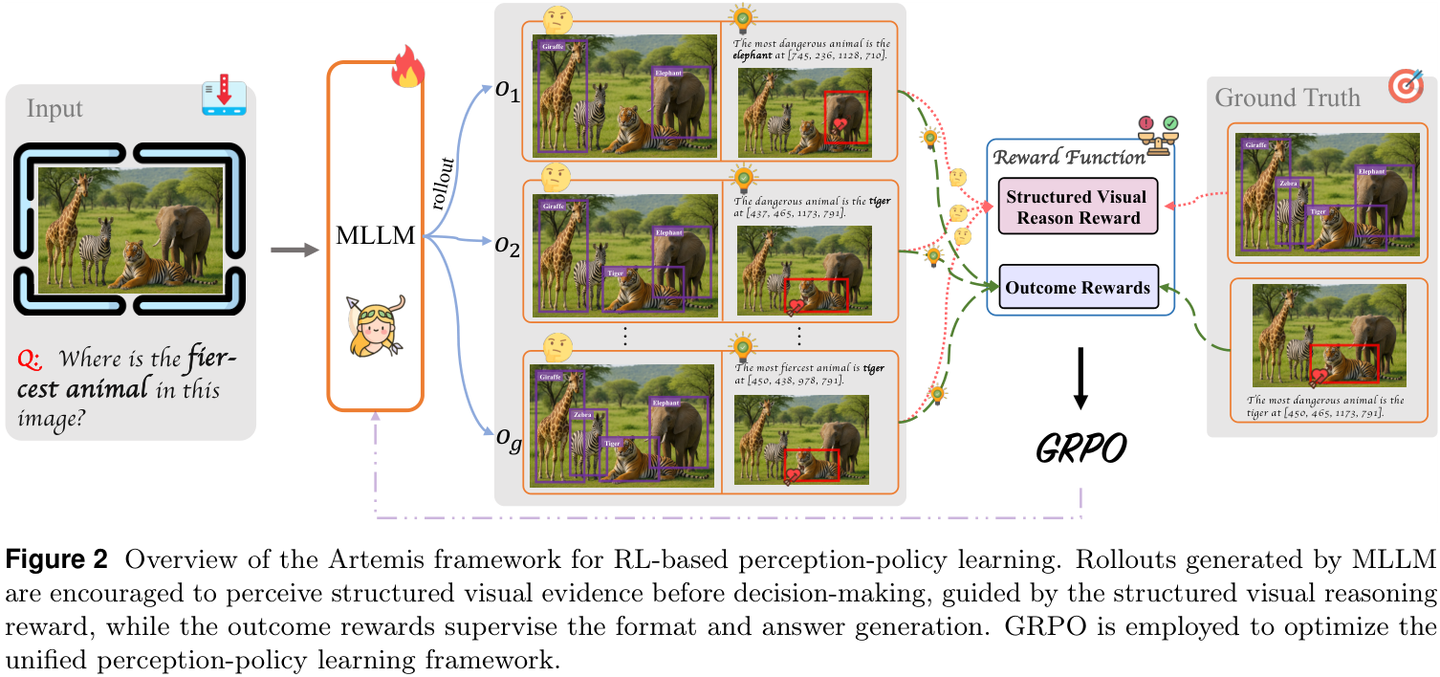
用于RL感知策略学习的Artemis框架概览。MLLM生成的Rollouts被鼓励在决策前感知结构化的视觉证据,由结构化视觉推理奖励引导,而结果奖励监督格式和答案生成。GRPO被用于优化统一的感知策略学习框架。
重新思考奖励设计
在以往的感知策略强化学习中,奖励通常只针对最终结果(Outcome-only)。这种反馈既稀疏又滞后,无法告诉模型它收集的视觉证据是否正确。结果就是,模型倾向于编造看似合理的语言理由,而不是真正去“看”图。
Artemis 设计了一套统一的奖励框架,不仅评估最终预测,还评估中间的 以对象为中心 的推理输出:
- 结构化视觉推理奖励(Structured Visual Reasoning Reward):这是Artemis的灵魂。它要求模型在
<think>标签内输出结构化的视觉证据(label, bbox)。为了鼓励模型生成有信息量的证据,Artemis 引入了 关键对象(Key Object) 的概念,即答案中的目标对象。预测出的框如果匹配关键对象,会获得最高奖励;而匹配其他相关对象(如上下文物体)也会获得正向奖励。这就像是老师不仅看答案,还要检查你的解题步骤中是否圈出了正确的关键信息。 - 结果奖励(Outcome Rewards):包含格式奖励和答案奖励。格式奖励确保输出结构规范;答案奖励则直接衡量最终预测的感知准确性(使用GIoU和标签一致性)。
统一的训练数据:Artemis-RFT
为了支持这种训练,作者构建了 Artemis-RFT 数据集。该数据集源自 MS-COCO,包含约 7.7万 个后训练实例,涵盖了视觉定位(Visual Grounding)和对象检测(Object Detection)两个任务。

Artemis-RFT数据示例。该数据集包含两种任务类型:视觉定位和对象检测,统一的Artemis感知策略学习框架在两者上联合训练。紫色框表示推理对象,绿色框表示答案。
如上图所示,Artemis 要求模型在给出最终答案(绿色框)之前,先通过推理(紫色框)识别出场景中的相关对象。这种训练方式让模型学会了“先看后答”。
实验结果:全方位性能提升
Artemis 在多个基准测试中展现了卓越的性能,证明了结构化视觉推理的有效性。
视觉定位与检测:SOTA级别的表现
在经典的 RefCOCO/+/g
视觉定位基准上,Artemis 全面超越了基座模型 Qwen2.5-VL 以及其他的 RL-based MLLM(如 Perception-R1, Vision-R1)。
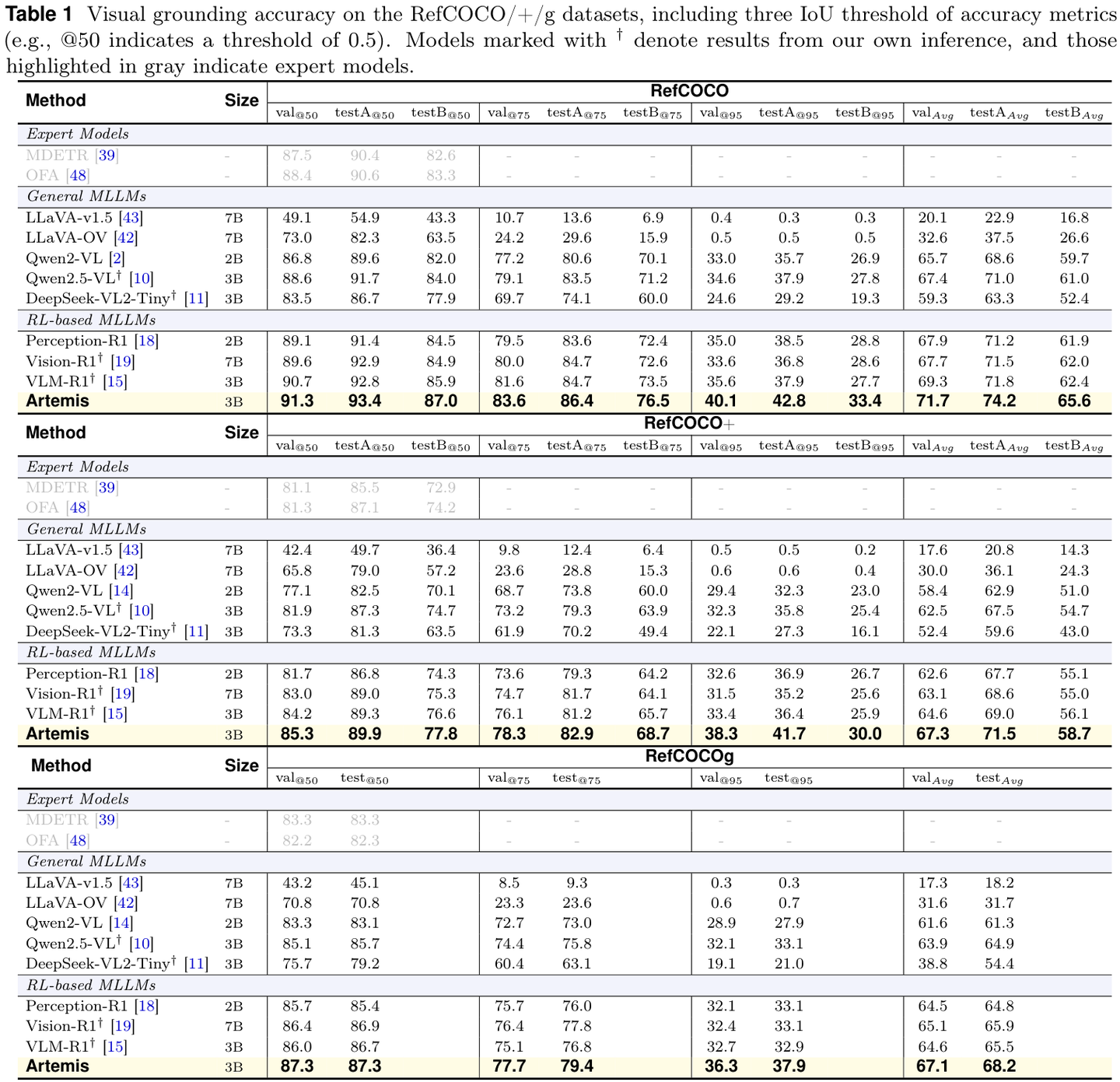
RefCOCO/+/g数据集上的视觉定位准确率。Artemis(高亮行)在所有指标上均取得最佳性能。
特别是在高 IoU 阈值(如 @95)下,Artemis 的优势更加明显,这说明它生成的边界框非常精准。
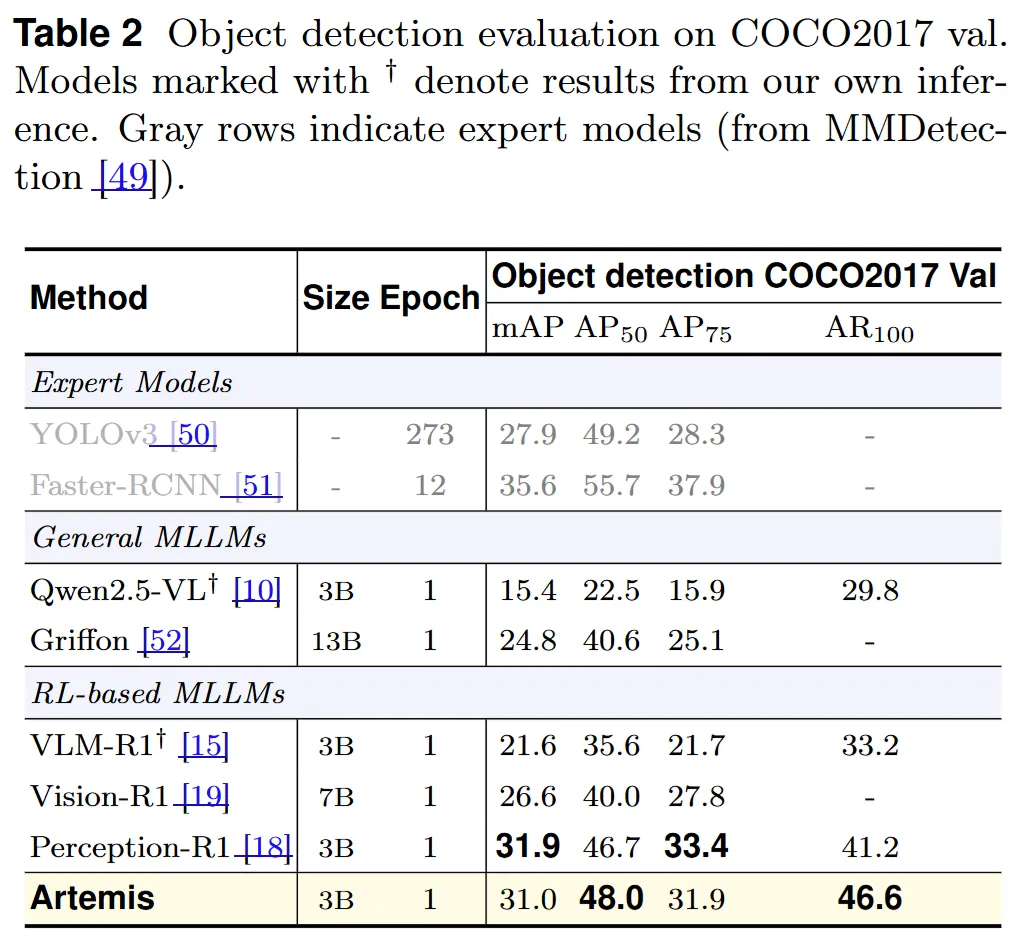
在 COCO 对象检测任务上,Artemis 同样表现出色,mAP 达到 31.0,显著优于 Qwen2.5-VL 的 15.4。
惊艳的零样本泛化能力
最令人惊喜的是 Artemis 的泛化能力。Artemis 仅接受了视觉定位和检测这一种视觉训练,却展现出了惊人的跨任务迁移能力。虽然训练时完全没有涉及计数或几何题数据,但它学会了通过“列举”来进行计数。
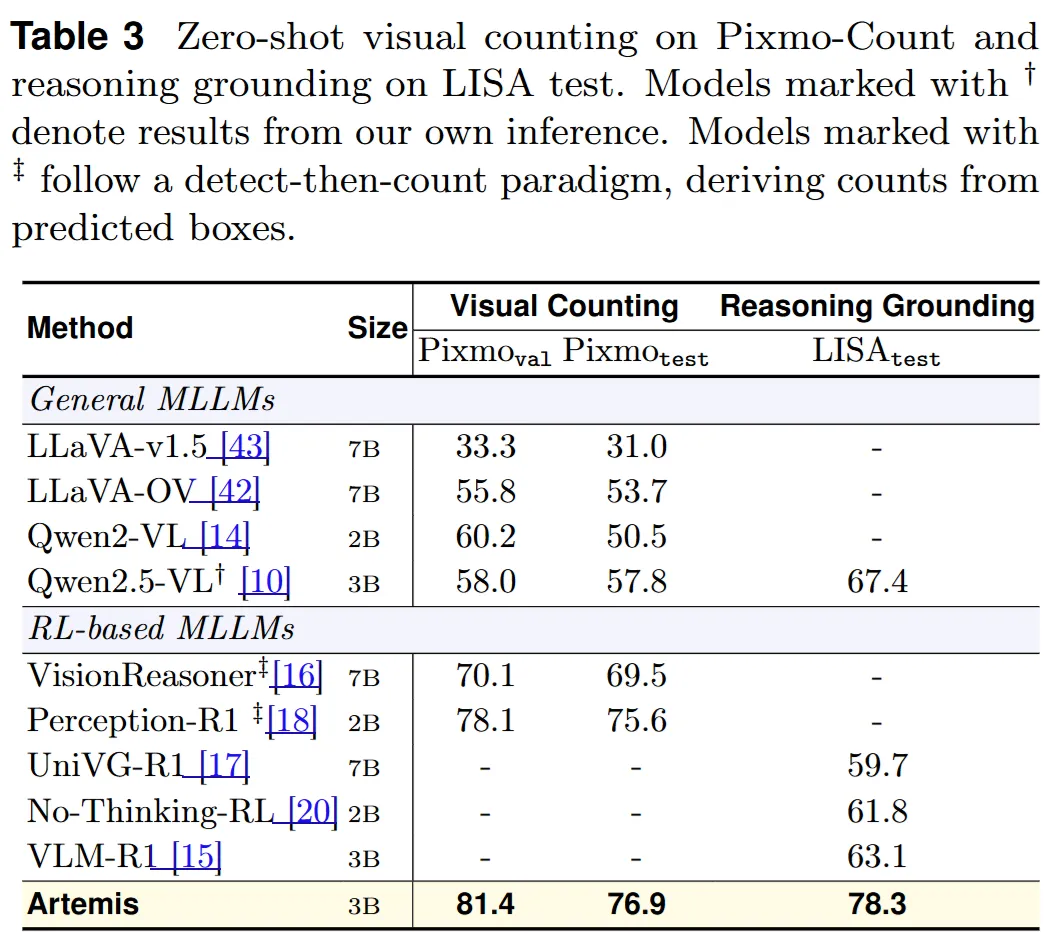
在 Pixmo-Count 数据集上,Artemis 的零样本计数准确率达到了 81.4,甚至超过了那些专门训练过的模型!
此外,Artemis 还能很好地迁移到数学几何场景,实现了从自然图像到数学图示的稳健跨域泛化。在 MATHGLANCE 基准测试中,Artemis 在平面几何、立体几何和图表题上都取得了优异成绩。
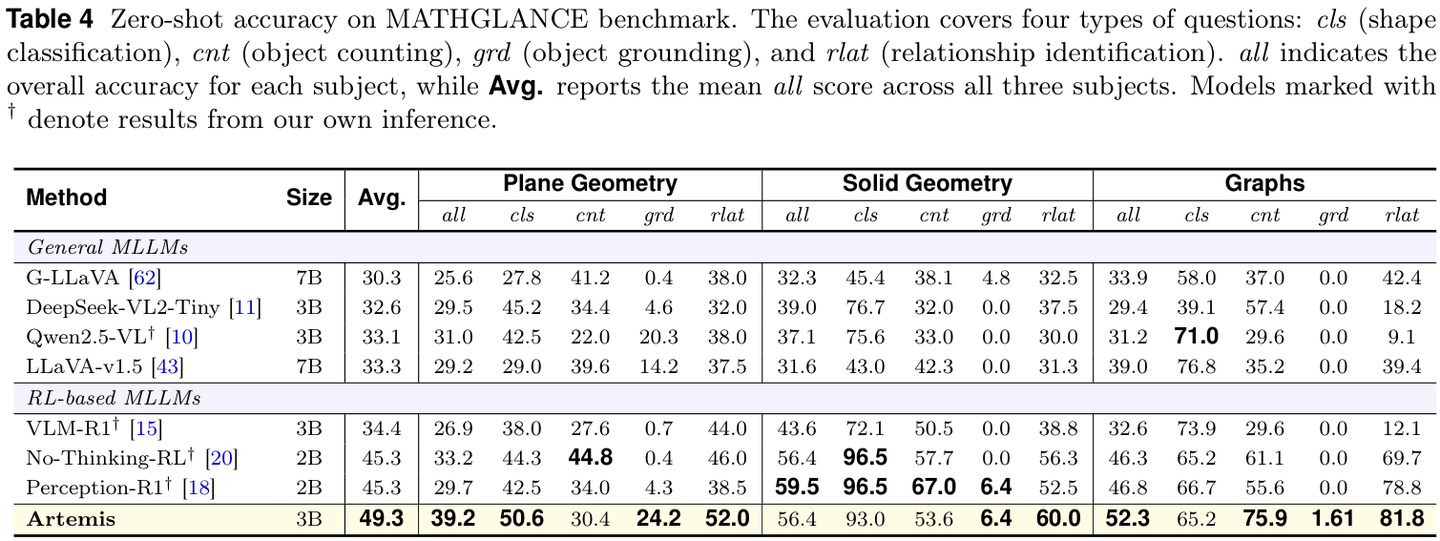
综合多模态能力
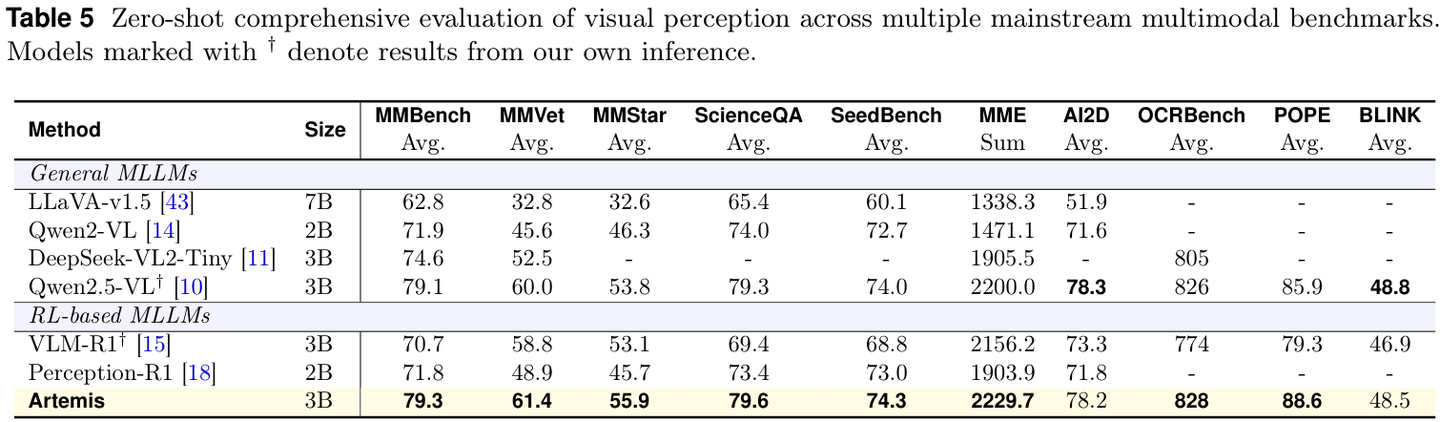
在 MMBench、MMVet
等通用多模态基准上,Artemis 也保持了领先优势,说明增强的感知能力反过来促进了整体的多模态理解能力。
消融分析:拆解结构化推理的技能提升点
作者通过消融实验进一步验证了结构化视觉推理(S.V. Rsn.)的优越性。
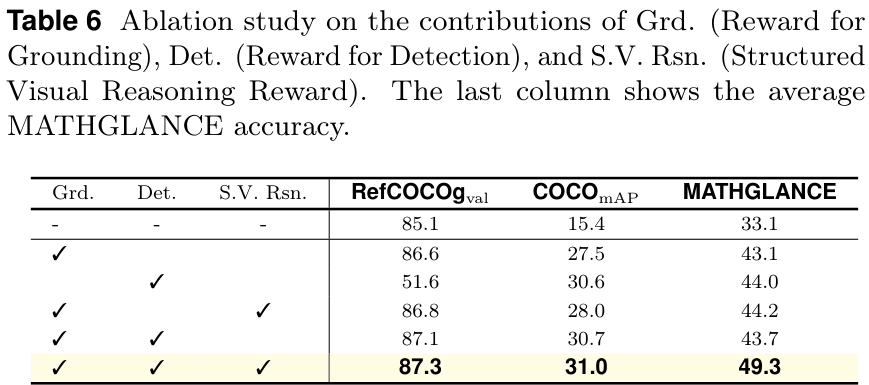
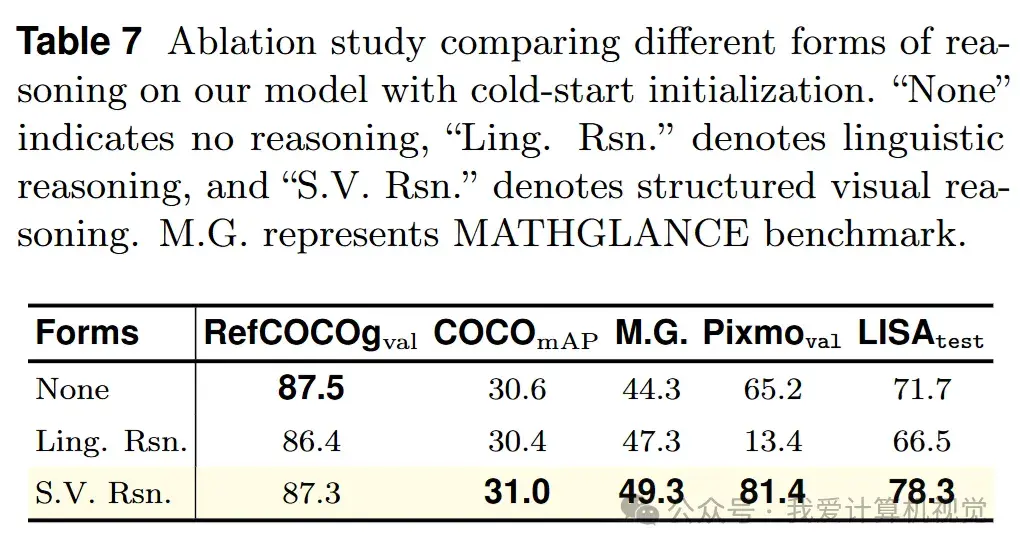
实验表明:
- 无推理(None reasoning):虽然在域内定位任务上表现尚可,但在域外任务(如数学几何)上泛化能力极差。
- 语言推理(Linguistic reasoning):引入纯语言推理反而会干扰感知,导致性能下降,尤其是在视觉计数任务上。
- 结构化视觉推理(S.V. Rsn.):不仅保持了强大的域内性能,更带来了显著的域外泛化能力提升。
可视化展示
让我们看看 Artemis 是如何“思考”的:
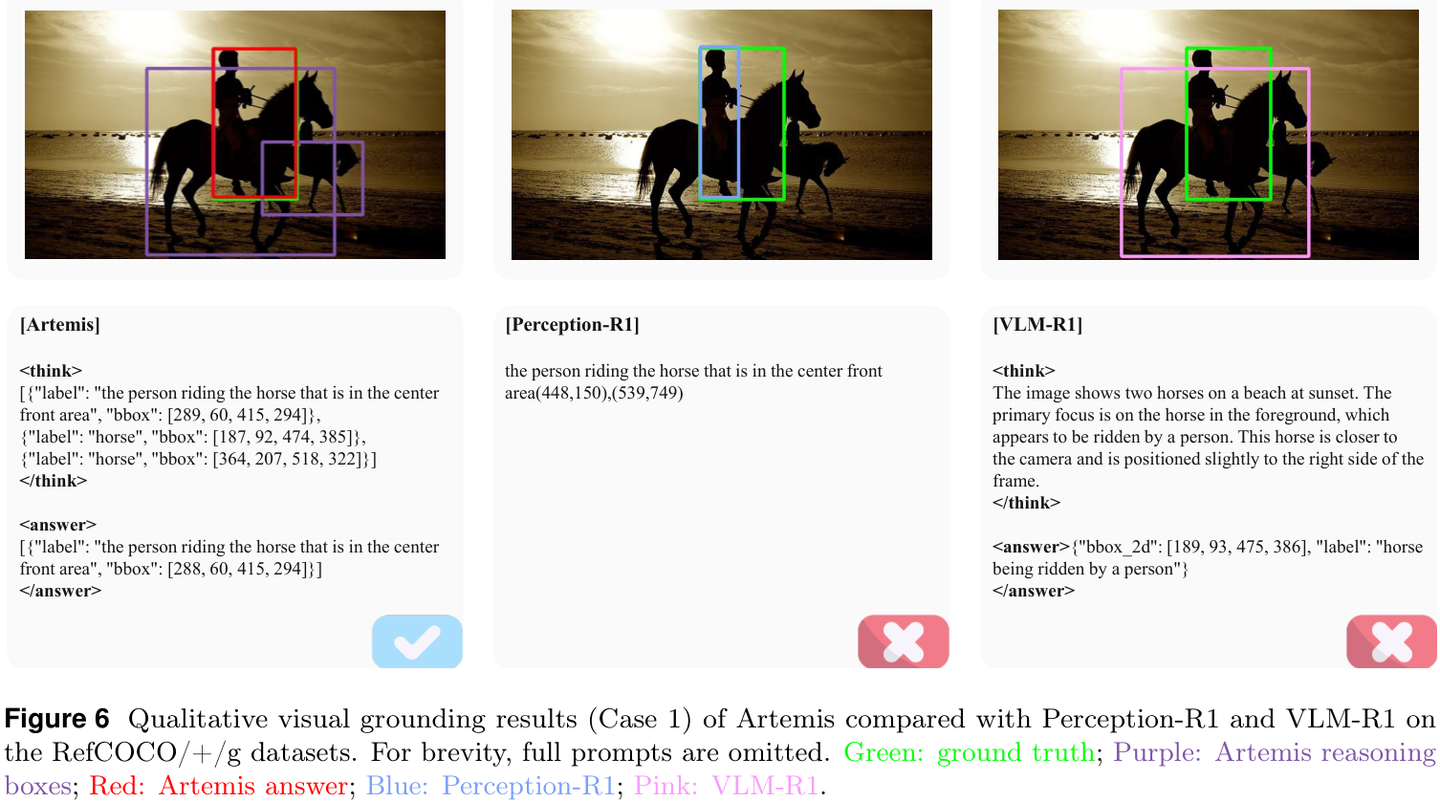
在上图中,Artemis 通过紫色的推理框精准地定位了场景中的关键要素,从而给出了正确的红色答案框。相比之下,其他模型要么定位错误,要么完全偏离目标。

在计数任务中,Artemis 展现了类似人类的“点数”行为,通过逐个标记目标(紫色框)来得出正确的总数,而基座模型 Qwen2.5-VL 则出现了严重的幻觉,标记了大量重复或错误的框。
写在最后
Artemis 的出现告诉我们,对于视觉感知任务,“怎么想”比“想什么”更重要。将推理过程 空间化、结构化,不仅能减少幻觉,还能让模型具备举一反三的泛化能力。
这项工作首次系统性验证了:依靠单一的结构化视觉训练,即可获得跨任务(计数、几何)、跨领域(自然图像到数学图示)的感知泛化能力。它为 MLLM 感知与空间推理的真正对齐提供了一条新的路线。
发表回复