
原文链接:https://zhuanlan.zhihu.com/p/1977492495781872862
下一代多模态智能的基石:浙江大学万字长文综述,构建从诊断到治理的LVLM数据生态—— ARC 框架:划出多模态智能发展的「数据弧度」

- 论文标题: Data Quality Management for Large Vision-Language Models: Issues, Techniques, and Prospects
- 作者: YICHEN YAN, ZHAOYI YUAN, JIAJUN PAN, XIU TANG, GONGSHENG YUAN,XIAOLING GU,JINPENG CHEN,SAI WU, KE CHEN, MINGLI SONG, LIDAN SHOU, HUAN LI, GANG CHEN
- 机构: 浙江大学大数据智能团队;杭州电子科技大学;北京邮电大学
- 论文地址: https://www.techrxiv.org/doi/full/10.36227/techrxiv.176282213.31303325/v1
- 项目主页: https://github.com/SuDIS-ZJU/Data-Quality-for-Vision-Language-Models
最近,大型视觉语言模型(LVLMs)的发展势头迅猛,像 GPT-4V
、LLaVA 这些模型在多模态理解、推理和生成方面都表现出了惊人的能力。但随着模型架构日趋成熟,一个老生常谈却又日益关键的问题浮出水面:“垃圾进,垃圾出”。数据质量,而非模型设计本身,正逐渐成为限制下一代 LVLM 能力和可信度的核心瓶颈。
来自浙江大学、杭州电子科技大学和北京邮电大学等机构的研究者们,刚刚发布了一篇非常系统和深入的综述,首次为 LVLM 的数据质量问题提供了理论上扎实的概览。他们提出了一个名为“ARC”的统一框架,旨在系统性地梳理和解决多模态数据面临的挑战。这篇解读将带大家一探究竟,看看这篇综述是如何为构建更可靠的多模态 AI 铺平道路的。
什么是 ARC 框架?
“师傅领进门,修行靠个人”,但如果“师傅”给的“秘籍”本身就有问题呢?LVLM 的训练数据就是这本“秘籍”。为了系统性地诊断和梳理这本“秘籍”里可能存在的问题,研究者们提出了一个三层分类法——ARC 框架,它分别代表可用性(Availability)、可靠性(Reliability)和可信度(Credibility)。
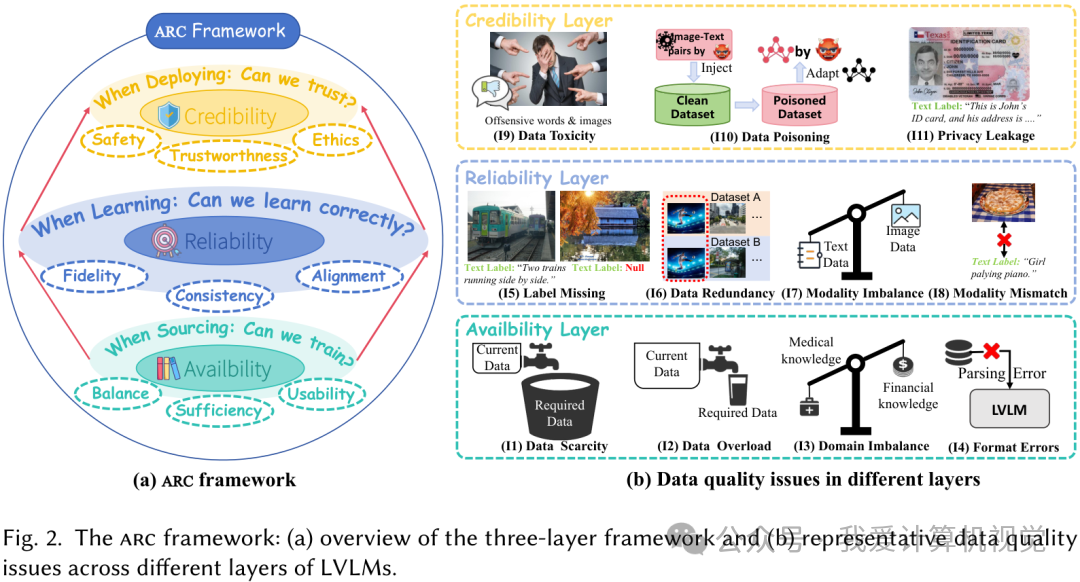
这个框架巧妙地将数据问题与模型开发流程对齐:
- 可用性层 (Availability) :关注数据获取阶段。这些数据我们能用吗?够用吗?覆盖面广吗?
- 可靠性层 (Reliability) :关注模型学习阶段。这些数据能让模型学到正确、有效的东西吗?
- 可信度层 (Credibility) :关注模型部署阶段。基于这些数据训练出的模型,它的输出我们能信吗?
这三层环环相扣,层层递进。只有数据“可用”,我们才能评估其“可靠性”;只有两者兼备,最终模型的“可信度”才有保障。
基于这个框架,论文总结了11 个典型的数据质量问题,并指出了它们可能出现的阶段(预训练、微调、推理)。

从症状到根源:数据问题的诊断路线图
理论有了,怎么落地?论文还非常贴心地提供了一个“诊断路线图”,帮助开发者从模型表现出的“症状”(比如训练失败、性能不佳、输出危险内容)一步步追溯到数据质量的“病根”。
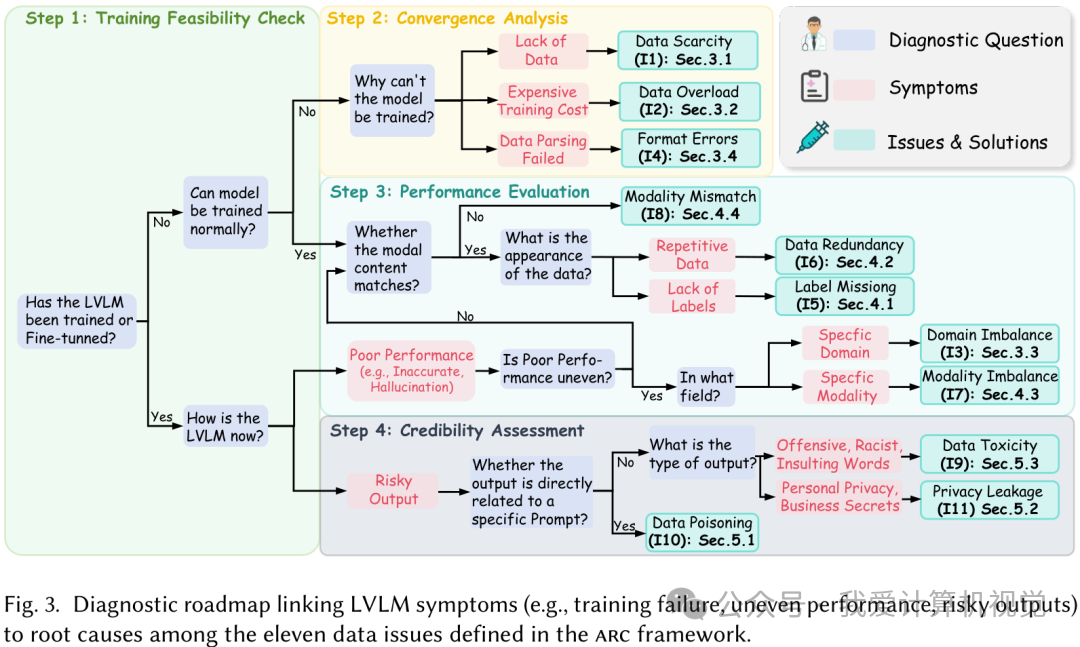
这个路线图遵循“可行性-有效性-可信度”的逻辑,就像医生问诊一样:
- 模型能训练吗? 如果训练都跑不起来,那很可能是“可用性”层出了问题,比如数据稀缺或格式错误。
- 模型收敛正常吗? 如果训练不收敛,可能还是“可用性”的问题,比如数据过载。
- 模型性能如何? 如果性能普遍差,可能是“可靠性”问题,如标签缺失或模态不匹配;如果只是在特定领域差,那可能是领域不平衡。
- 输出有风险吗? 如果模型输出有害、带偏见或泄露隐私的内容,那无疑是“可信度”层的问题,比如数据毒性或隐私泄露。
这个路线图为 LVLM 的“数据医生”们提供了一套标准操作规程(SOP)。
应对三大挑战:策略与技术
论文的核心部分详细探讨了可用性、可靠性和可信度三个层面下的具体问题及其缓解策略。
可用性 (Availability):“米”从哪里来,够不够好?
这一层主要解决数据的“温饱”问题。
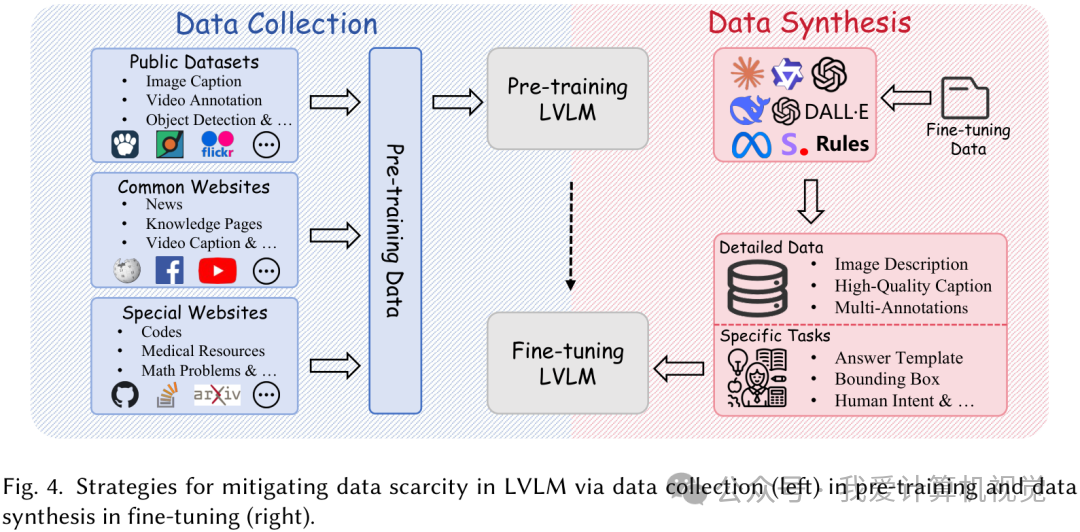
- 数据稀缺 (Data Scarcity) :巧妇难为无米之炊。预训练阶段缺数据,就得靠大规模数据收集,从公共数据集、通用网站甚至特定领域网站(如 GitHub、arXiv)“搜刮”数据。微调阶段数据金贵,直接收集不现实,可以通过数据合成,利用规则或生成模型来“创造”数据。
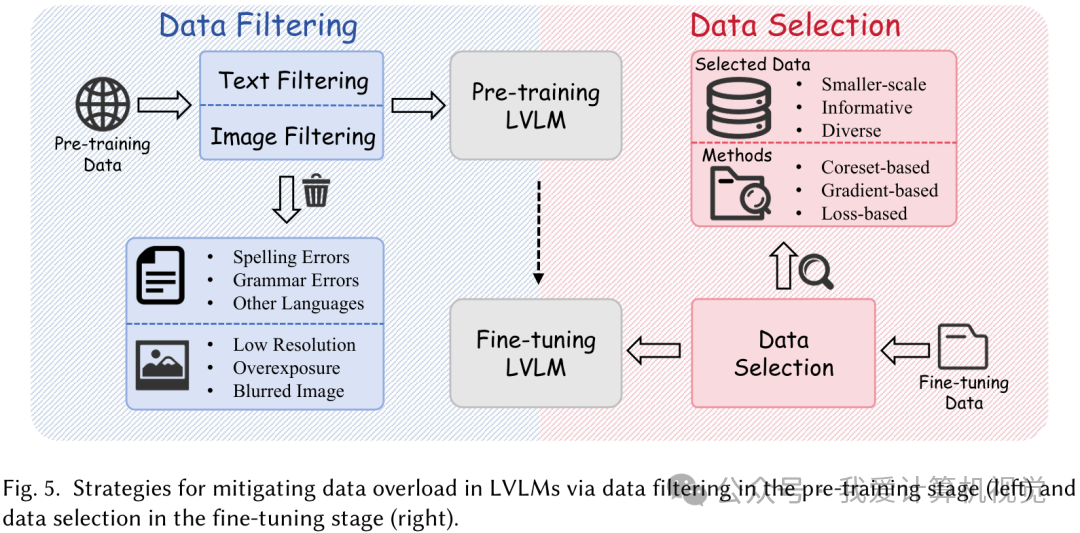
- 数据过载 (Data Overload) :数据太多也愁人,尤其是混入大量无关、嘈杂的内容。预训练阶段,要进行高效的“数据过滤”,把拼写错误、低分辨率、过曝的图文对筛掉。微调阶段则要进行更精细的“数据选择”,比如基于 Coreset、梯度或损失的方法,挑出信息量最大、最具代表性的子集进行训练,实现“降本增效”。
- 领域不平衡 (Domain Imbalance) 和 格式错误 (Format Errors) :前者指数据在不同领域分布不均(如普通场景图片多,医学、金融图片少),后者指数据结构或格式混乱。解决方法包括整合特定领域数据集、动态调整采样权重,以及利用大模型自身进行数据清洗和格式统一。
可靠性 (Reliability):数据对不对,齐不齐?
这一层关心数据的“内在品质”,即语义是否准确、一致,模态间是否对齐。
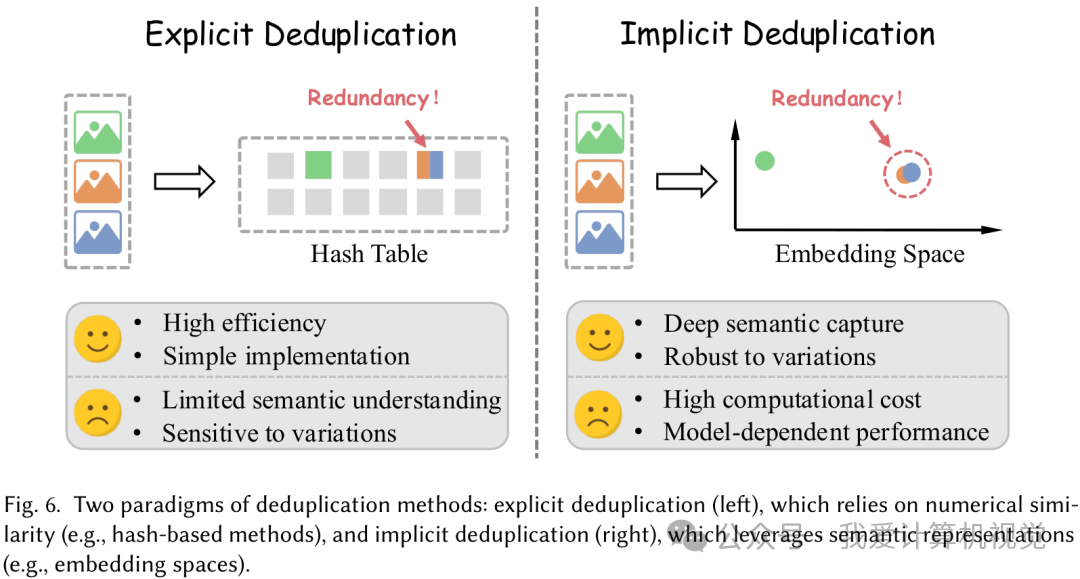
- 数据冗余 (Data Redundancy) :数据集中存在大量重复或高度相似的样本,会浪费计算资源、放大偏见。去重方法分为两类:显式去重,通过哈希值等数值方法快速筛查,效率高但无法理解语义;隐式去重,利用深度模型在嵌入空间中比较语义相似度,更智能但计算成本高。
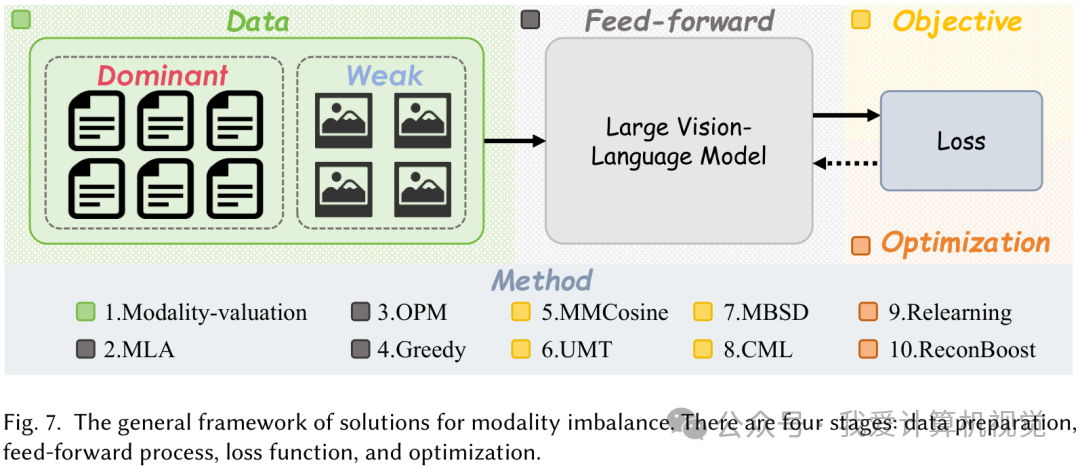
- 模态不平衡 (Modality Imbalance) :训练时某个模态(通常是文本)过于强势,导致模型学习有偏。论文总结了从数据、表征、目标函数到优化四个层面来解决这个问题的通用框架,比如通过数据增强来丰富弱势模态,或在模型内部通过注意力机制来平衡不同模态的贡献。
- 标签缺失 (Label Missing) 和 模态不匹配 (Modality Mismatch) :前者指缺少精细的标签,后者指图文内容不一致。解决方法包括自监督学习生成伪标签、利用 LLM 辅助标注,以及通过文本增强、图像增强或联合增强来改善图文对的对齐质量。
可信度 (Credibility):数据干不干净,安不安全?
最高层次的追求,关乎模型的“人品”——是否合乎道德、安全和法律规范。
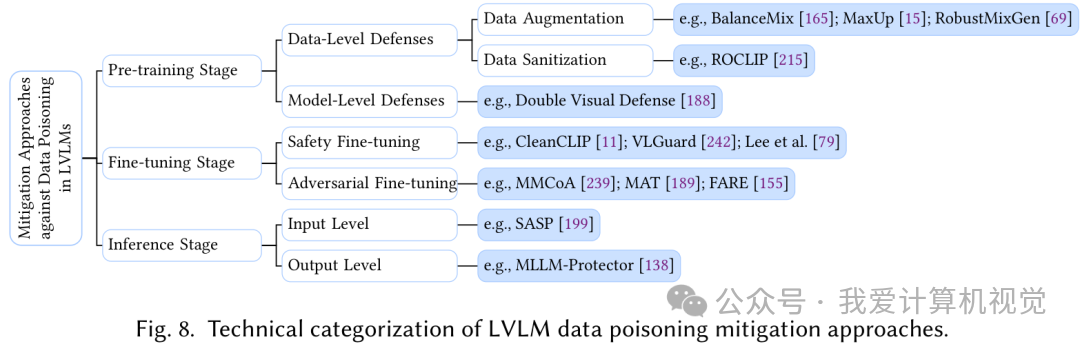
- 数据投毒 (Data Poisoning) :攻击者恶意在数据中注入“毒药”(如带特定触发器的样本),以操控模型行为。这就像在“秘籍”里埋下暗门。论文系统梳理了在预训练、微调和推理阶段的防御策略,包括数据增强、数据清洗、安全微调、对抗性微调等。
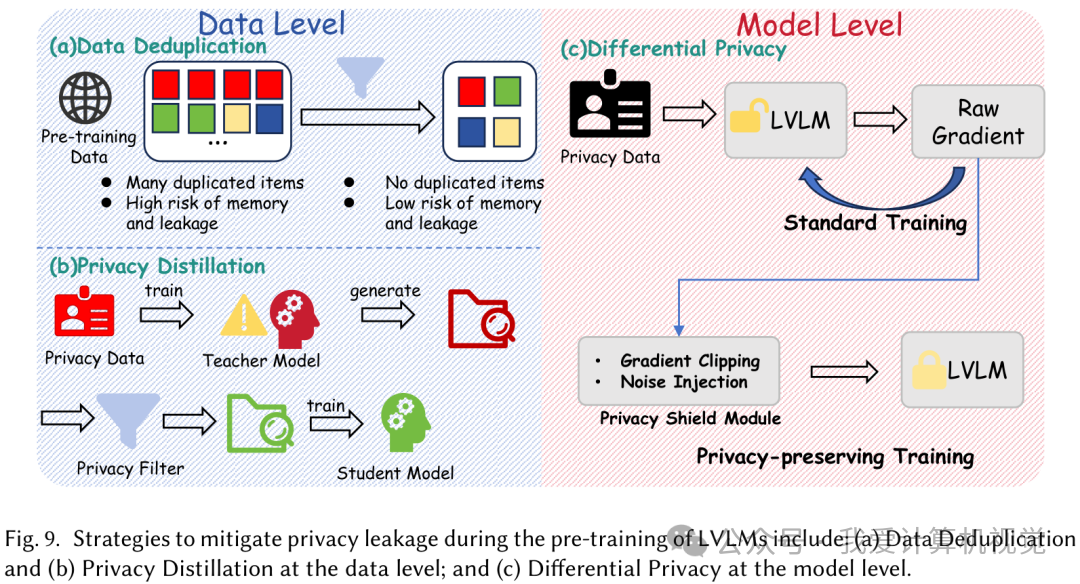
- 隐私泄露 (Privacy Leakage) :模型不经意间“记住”并泄露了训练数据中的敏感信息。这在多模态模型中尤为严重,因为一张图可能包含远超文本的个人信息。防御手段在数据层面包括数据去重和隐私蒸馏,在模型层面则有**差分隐私(Differential Privacy, DP)**等技术。
- 数据毒性 (Data Toxicity) :数据中含有冒犯性、有害或带偏见的内容。主要的缓解方法是进行毒性过滤,包括单模态(主要针对文本)和多模态的过滤技术。
未来展望:从静态数据到动态生态系统
这篇综述不仅总结了现状,还指出了未来的发展方向。研究者认为,LVLM 正从单纯的理解与推理工具,向着能够自我治理和演化的智能体(如具身智能、AI 科学家)迈进。
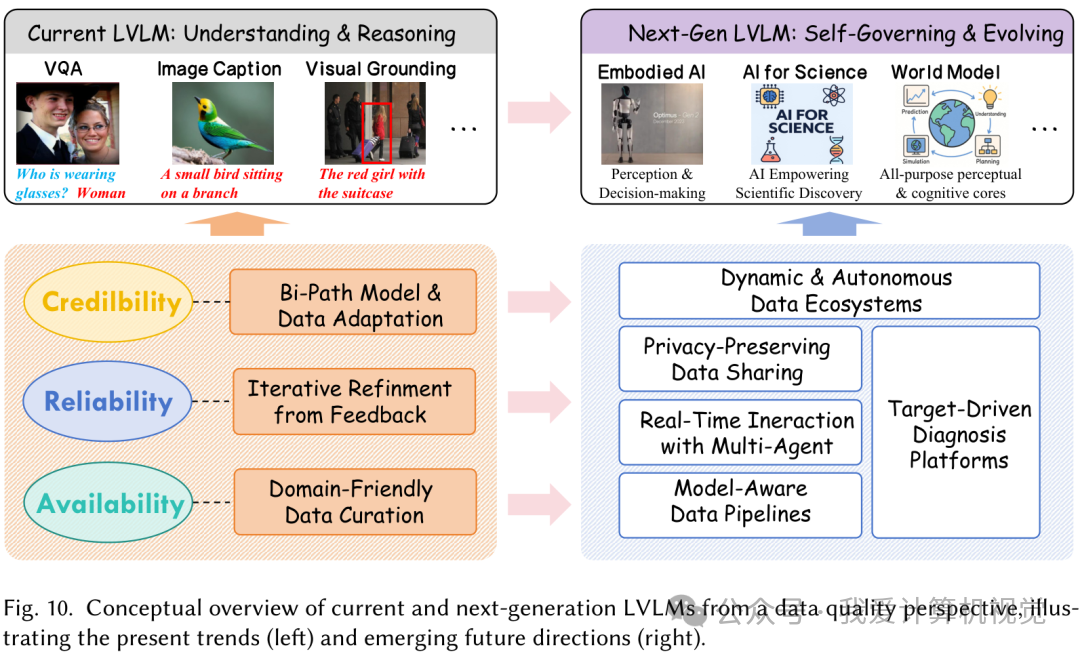
这意味着,未来的数据管理将不再是一次性的、静态的语料库构建,而是一个动态、自主的数据生态系统。在这个生态里:
- 数据流水线将是模型感知的:根据模型架构来定制化地组织数据。
- 数据质量将由多智能体实时交互保障:智能体们协同决定数据的取舍和优化。
- 数据共享将在保护隐私的前提下进行:通过联邦学习、差分隐私等技术,打破“数据孤岛”。
- 数据诊断平台将由目标驱动:自动化地发现问题并推荐解决方案。
总结
总而言之,这篇综述为我们描绘了一幅清晰的 LVLM 数据质量全景图。它不仅是一个理论框架,更是一本实践手册,为所有致力于构建更强大、更可靠、更负责任的多模态 AI 的研究者和工程师们,提供了宝贵的指引。
发表回复