
原文链接:https://mp.weixin.qq.com/s/Htms0tdyka0-1tTn4kLGCw
扩散模型在自动驾驶场景视频生成中已经展现出比较有前景的视觉生成质量。然而,现有的基于视频扩散的世界模型在灵活长度、长时序预测以及轨迹规划方面仍存在不足。这是因为传统视频扩散模型依赖于对固定长度帧序列的全局联合分布建模,而非逐步构建每个时间下的局部化分布。本研究提出 Epona,一种自回归扩散世界模型,通过两项关键创新实现局部时空分布建模:1)解耦的时空分解,将时间动态建模与细粒度未来世界生成分离;2)模块化的轨迹与视频预测,通过端到端框架无缝整合运动规划与视觉建模。本文的架构通过引入一种新的“链式前向训练策略”(chain-of-forward training strategy),在实现高分辨率、长持续时间生成的同时解决了自回归循环中的误差累积问题。实验结果表明,与现有方法相比,Epona在FVD指标上提升7.4%,预测时长可达数分钟。该世界模型进一步可作为实时端到端规划器,在NAVSIM基准测试中优于现有端到端规划器。
- 论文标题:Epona: Autoregressive Diffusion World Model for Autonomous Driving
- 论文地址:https://arxiv.org/abs/2506.24113
- 项目主页:https://kevin-thu.github.io/Epona/
- GitHub地址:https://github.com/Kevin-thu/Epona/

研究动机剖析
扩散 or 自回归?世界建模仍存鸿沟
近年来,伴随着生成模型的快速发展,世界模型作为模拟物理世界、建构环境动态并辅助智能体进行规划与决策的关键技术范式,受到广泛关注。在自动驾驶这样高动态、高复杂度任务中,世界模型可通过预测未来环境状态,辅助智能体实现前瞻性轨迹规划,从而摆脱对繁复感知模块与昂贵标注数据的依赖,成为构建下一代端到端自动驾驶的重要路径。
然而,当前自动驾驶世界模型的建模方式和架构设计仍存在明显缺陷。现有的世界模型架构主要借鉴自两大类主流生成模型框架:
- 基于视频扩散的世界模型(如 GAIA-2、Vista):能生成高质量连续视频,但仅限固定长度、缺乏时序因果性建模,难以扩展至灵活长度长视频生成和轨迹规划任务;
- 基于自回归Transformer类模型(如 GAIA-1、DrivingWorld):通过离散token自回归建模实现长序列预测,支持闭环控制和视频轨迹联合生成,但牺牲了连续图像质量和真实轨迹建模能力,且自回归长时序推理存在严重误差累积。
这两类方法各有优劣,长期以来缺乏一种统一且实用的解决方案。在自动驾驶等应用中,大家希望模型既具备高质量长时序的预测推理能力,又能进行实时运动规划与轨迹控制,因此如何革新世界模型的基础架构设计成为限制世界模型发展的关键挑战。
相关工作回顾
自动驾驶世界模型
构建真实驾驶世界模型近年来受到广泛关注,其中以视觉为中心的方法因其传感器灵活性、数据可访问性以及更接近人类的表征形式而占据主导地位。早期研究主要集中在通过微调将预训练扩散模型(如 Stable Diffusion)适配到驾驶场景中。然而,这些方法要么缺乏关键的规划模块,要么受限于低分辨率和短时生成,难以满足长期一致预测和实时规划的需求。
近期研究探索了采用GPT风格架构来统一视觉与动作建模,并实现了长序列自回归生成。然而,这些方法需要将图像和轨迹编码为离散token,显著降低了视觉质量和轨迹精度。同样,新发布的Cosmos基础模型虽可作为驾驶世界模型,但并未引入新框架,仍面临与前述方法相同的局限性。此外,其庞大的参数量和计算需求也限制了实用性。相比之下,本文提出了一种新颖的自动驾驶自回归扩散世界模型框架,支持连续视觉与轨迹表征下的长序列自回归生成。
长视频生成
长时序预测不仅是当前视频生成模型的关键挑战,也是世界模型鲁棒泛化的核心能力,因为它反映了模型学习环境动态并准确模拟时间进程的能力。由于原始视频扩散模型(如SVD)仅能生成固定长度的短片段,早期方法通过噪声重调度、重叠生成或分层生成扩展视频长度。然而,这些技术未能解决模型固有限制,常导致长视频中出现不一致性和突变视觉效果。
自回归方法天然支持变长生成,但因教师强制训练(teacher-forcing)与采样阶段误差累积之间的领域偏移(domain shift),导致生成质量显著下降。GameNGen和DrivingWorld通过训练中引入噪声增强和随机token丢弃缓解这个问题,但却受限于特定模型架构。本文提出了一种通用的“链式前向训练策略”(chain-of-forward strategy),使模型在训练中直接学习推理误差,有效减少自回归漂移。
近期研究如Diffusion Forcing和FIFO-Diffusion通过调整帧级噪声水平和利用因果网络设计,探索了视频扩散中的自回归生成。Epona采用了类似的因果时间建模策略,但将架构重新定义为两阶段端到端框架,支持运动规划与下一帧图像的联合生成。
算法详解
重新思考世界模型的建模方式



在此设计基础上,Epona 引入三项关键设计创新:
解耦时空建模
实现灵活长度的高质量长时序视频生成
传统视频扩散模型建模固定长度序列的联合分布,难以支持长视频生成和灵活控制。Epona 首次在扩散世界模型中显式解耦时间建模与空间生成:
- 时序建模:使用多模态时空 Transformer(MST)通过交错的 causal temporal attention 和 spatial attention 编码历史视觉与轨迹序列,提取紧凑的时序潜变量;
- 空间生成:基于时序潜变量条件,使用双-单流结构的 DiT 预测未来轨迹和驾驶场景,支持逐帧自回归生成。
这一结构显式建模了时序信息,显著增强了模型的时间维度可扩展性,允许根据条件灵活生成任意长度的视频,同时保持每一帧的高分辨率与细节一致性。实验中,Epona 可在 NuPlan 上生成超过 2分钟(600帧)的高质量驾驶视频。
解耦轨迹与图像生成

Chain-of-Forward 训练策略
缓解自回归误差积累


实验结果
Epona 在 NuPlan和nuScenes数据集上从头训练,输入图像尺寸为 512×1024,模型总参数量约 2.5B,采用 Rectified Flow 目标端到端优化。推理阶段可在单张 4090 GPU 上进行,单张 4090 上图像生成约 2s/帧,轨迹预测支持 20Hz 实时运行。
分钟级长视频生成
与 SoTA 的自动驾驶世界模型 Vista 和 NVIDIA Cosmos (v1-AR-4B)对比,Epona 大大提高了可生成视频的长度,在 NuPlan 数据集上可生成长达 2 分钟(600帧)的驾驶视频,具有显著优势: assets/comparison1.mp4 assets/comparison2.mp4 assets/comparison3.mp4
轨迹控制视频生成
Epona 支持细粒度的轨迹控制,可根据指定轨迹生成定制化的驾驶视频: assets/control.mp4
视频生成结果对比:

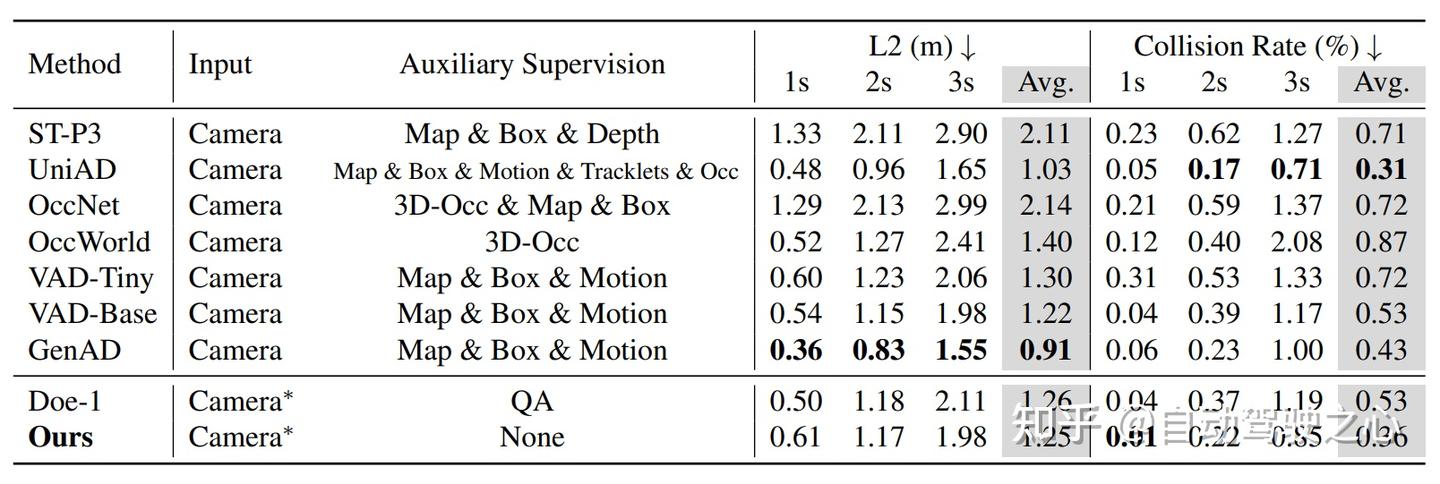
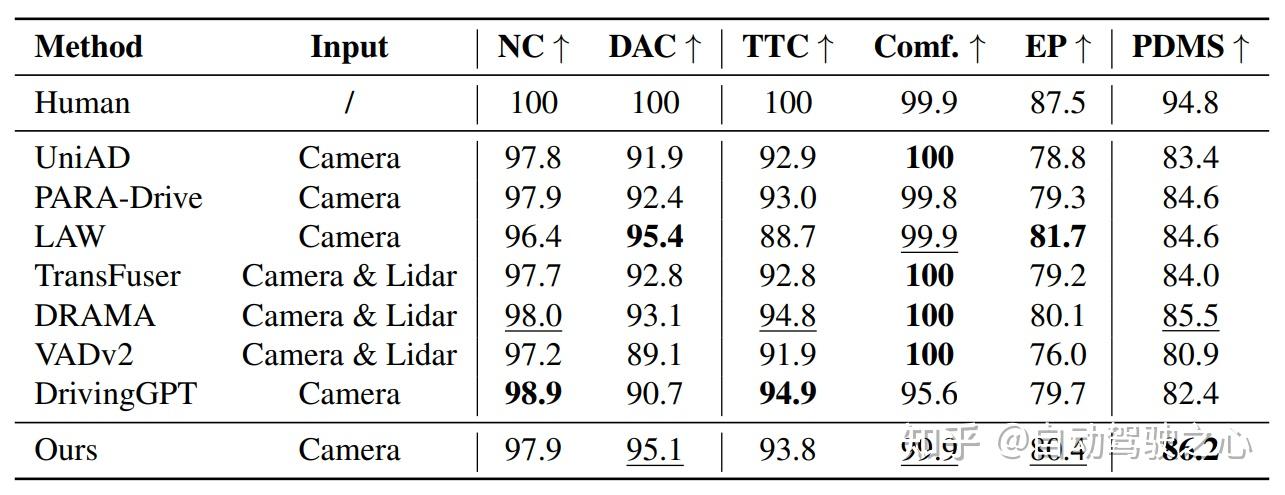
端到端轨迹预测
Epona 支持端到端轨迹预测,可用于自动驾驶运动规划,相较专为运动规划设计的端到端网络,在 nuScenes 和 NAVSIM基准上均取得有竞争性的结果:
与其他工作的对比&讨论
近来AR+Diffusion的设计思想受到广泛关注,这里也分享下笔者的个人理解,简要对比Epona的设计思想与相关工作的不同之处:
- Transfusion, JanusFlow , Bagel等工作将 token-by-token 的文本自回归与图像扩散结合,主要聚焦于统一大模型中图像的语义理解和生成;而 Epona 将 frame-by-frame 的时序潜变量自回归与多模态扩散生成相结合,聚焦于解决视频生成中的时序建模与动态一致性问题。
- MAR, NOVA, VideoMAR等工作通过 Diffusion Loss 建模连续 token 的分布,摆脱了传统自回归模型中 VQ 离散化的需求,但当前在视频生成上的探索仍处在初步阶段,局限于生成短时序、动态性小的视频,在世界模型长时序、高动态的视频生成中的能力尚待探索。
- CausVid, Self Forcing, Vid2World等工作通过修改现有的视频扩散模型架构引入时序建模和逐帧生成能力,但仍受限于视频扩散模型本身训练的视频长度;Epona 则重新设计了世界模型架构,将时序建模和逐帧空间建模显式解耦,且支持图像、轨迹多模态生成。
总结
Epona 提出了一种自回归扩散式的新型自动驾驶世界模型框架,通过任务解耦、结构重构与链式训练策略,实现了在同一模型中统一支持分钟级视频生成、轨迹可控模拟和实时规划控制三项核心能力。尽管如此,当前模型对真实物理规律的刻画仍显粗略,在视频生成的视觉质量、轨迹调控的表达能力上也仍存在提升空间。未来,团队将进一步探索将三维、多视角、多模态等先验融入世界模型结构中,提升模型对物理动态与交互规律的建模能力,探索更好的视觉建模方法,进一步拓展世界模型其在智能体决策中的泛化潜力。
发表回复