
原文链接:https://zhuanlan.zhihu.com/p/1896019770790375830
自动驾驶视觉问答(AD-VQA)旨在基于给定的驾驶场景图像回答与感知、预测和规划相关的问题,这高度依赖于模型的空间理解能力。先前的工作通常通过坐标的文本表示来表达空间信息,导致视觉坐标表示和文本描述之间的语义差距。这种疏忽阻碍了空间信息的准确传递,并增加了表达负担。为了解决这一问题,我们提出了一种新的基于标记的提示学习框架(MPDrive),它通过简明的视觉标记来表示空间坐标,确保语言表达的一致性,并提高AD-VQA中视觉感知和空间表达的准确性。具体来说,我们通过使用检测专家在目标区域上叠加数字标签来创建标记图像,将复杂的文本坐标生成转换为基于文本的视觉标记预测。此外,我们将原始图像和标记图像融合为场景级特征,并结合检测先验来获取实例级特征。通过结合这些特征,我们构建了双粒度的视觉提示以激发LLM的空间感知能力。在DriveLM和CODA-LM
数据集上的广泛实验表明,MPDrive在需要复杂空间理解的情况下实现了最先进的性能。
引言
自动驾驶技术迅速发展,显示出提升道路安全、交通效率和减少人为错误的潜力。一个强大的自动驾驶系统需要能够感知复杂环境并做出明智决策的代理。最近,多模态大语言模型(MLLMs)已成为自动驾驶的一种有前景的方法,在视觉问答(AD-VQA)任务中展示了强大的泛化能力。当前的MLLMs在自动驾驶场景中的空间理解方面面临挑战,限制了它们准确定位、识别和描述驾驶场景中目标及其状态的能力。尽管一些AD-VQA方法尝试通过指令调优领域特定数据集来增强MLLM性能,但它们并未充分解决空间推理优化的核心挑战。在这些方法中,有些通过整合检测先验来增强空间理解。然而,这些方法通常以文本格式表达空间坐标,导致基于坐标和语言描述之间的不一致,从而削弱了自动驾驶中的感知准确性和精确的空间表达。
如图1所示,当前研究直接以文本格式表示目标空间坐标,导致坐标和文本描述之间的语义差距。这种错位对后续的预测和规划任务产生了不利影响。相比之下,MPDrive将复杂的生成空间坐标的过程转换为基于文本的视觉标记(带有数字标签的区域)预测,确保语言一致性。

本文重点关注提高自动驾驶中坐标表示和空间理解的一致性。我们提出了基于标记的提示学习框架(MPDrive),这是一种新颖的多模态框架,使用文本索引来注释每个交通元素,并直接预测相应索引的坐标。
如图1所示,MPDrive利用视觉标记,即在图像检测区域上叠加的基于文本的索引,突出关键目标的空间位置。这种转换将复杂的生成空间坐标的过程简化为基于文本的视觉标记预测,从而弥合了AD-VQA中坐标表示和语言描述之间的差距。此外,通过结合多层次的空间特征,MPDrive激发LLM的空间感知能力,提高视觉标记预测的准确性,提升预测和规划任务的性能。
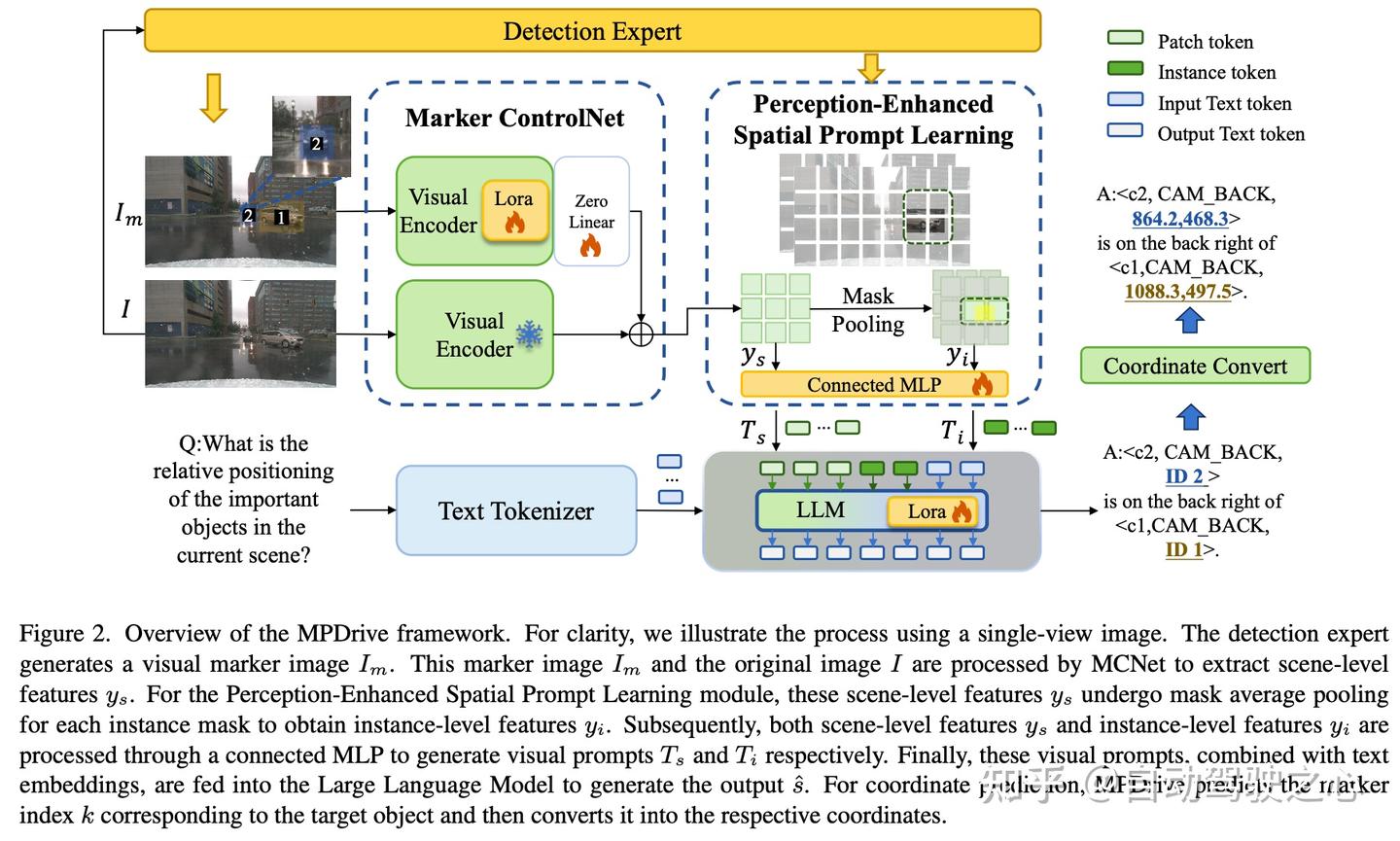
为此,我们提出了两个组件:标记控制网络(MCNet)和感知增强空间提示学习(PSPL
)。具体而言,MCNet处理原始图像和视觉标记图像,在保留原始图像特征的同时准确表达空间信息。PSPL结合场景级和实例级视觉提示:i) MCNet生成场景级提示以捕捉全面的空间关系,而ii) 实例级提示通过遮罩平均池化整合细粒度的目标特征。这种集成显著增强了MPDrive的空间理解能力。
总之,本文的主要贡献如下:
- 提出了MPDrive,一种基于标记的提示学习框架,利用视觉标记弥合AD-VQA中基于坐标和语言描述之间的差距,显著提高了自动驾驶中的空间理解能力。
- MPDrive由两个组件组成:标记控制网络(MCNet)和感知增强空间提示学习(PSPL)。MCNet融合视觉标记图像以获取场景特征,而PSPL整合场景级和实例级视觉提示,增强多层次的空间理解能力。
- 广泛的实验表明,MPDrive在AD-VQA任务中取得了最先进的结果,在DriveLM数据集的多图像任务和CODA-LM数据集的单图像任务中表现优异,特别是在复杂的场景中。
相关工作回顾
AD-VQA
AD-VQA已成为促进人车交互和提高复杂驾驶场景中决策能力的重要组成部分。最近的自动驾驶研究通过多个视角取得了进展:用于场景理解的多模态融合、用于决策的多步推理、信号控制优化、运动规划和角落案例处理。这些方法通过有效整合多模态数据和推理机制,共同增强了系统的能力。
近期的研究越来越关注在自动驾驶中增强MLLMs的空间理解能力。ELM利用专家生成的文本描述来改进目标定位,而LLM-Driver通过将向量化数值模式与预训练的LLMs集成,提升了上下文理解能力。同样,Reason2Drive
采用先验分词器和指令视觉解码器来加强视觉定位能力。尽管这些策略旨在通过检测先验来增强空间理解,但通常涉及复杂的训练方案,例如添加复杂的网络架构或检测优化函数。此外,这些策略通常以文本格式表示空间坐标,这可能增加模型的复杂性。因此,这些方法忽视了基于坐标和语言描述之间的差异,损害了自动驾驶系统中的感知准确性和空间信息的精确表达。
MLLMs
MLLMs展示了显著的可解释性和泛化能力。近期MLLMs的进步主要集中在视觉-语言对齐和训练策略上。对于对齐,BLIP-2引入了Q-Former以实现高效的模态桥接,MiniGPT-4通过投影层将冻结的视觉编码器与LLMs对齐,而InternVL提出了视觉模型与LLMs之间的渐进对齐。对于训练策略,LLAVA利用机器生成的指令数据,而MiniCPM通过高级学习率调度优化性能。这些进步使MLLMs成功应用于视频理解、图像理解和具身AI。
在自动驾驶中,MLLMs以多种方式进行了探索。Atlas和DriveGPT4分别通过3D标记化和多帧视频处理增强驾驶能力。为了资源效率,MiniDrive和EM-VLM4AD
提供了轻量级的MLLMs用于自动驾驶。同时,TOKEN集成了标记化的目标级知识,而DriveAdapter通过特征对齐和动作引导学习提高了模型性能。这些努力尝试将MLLMs应用于自动驾驶;然而,它们尚未充分探索驾驶场景中的空间理解。
视觉提示
视觉提示已被广泛用于各种下游任务的迁移和适应,可分为可学习和图像修改方法。可学习的视觉提示方法将可训练的标记作为额外的视觉输入,LM-BFF和VPT等作品通过基于提示的微调展示了增强的学习效率。图像修改的视觉提示方法侧重于通过专家生成的元素修改图像,FGVP、API和SoM通过分割掩码和注意力热图等技术显著提高了MLLMs的视觉理解能力。
虽然我们的方法受到SoM的启发,它在图像上叠加掩码和标记,但我们引入了几项关键改进,以更好地应对自动驾驶任务中的特定挑战。首先,传统标记可能会遮挡原始图像中的关键信息,例如目标的颜色和特征。为了解决这个问题,我们使用Marker ControlNet逐步引入标记衍生的信息,从而保留原始图像的关键视觉信息,同时利用视觉标记的好处。此外,我们还引入了一种视觉提示过程:Perception-Enhanced Spatial Prompt Learning,包括场景级和实例级视觉提示,显著增强了MPDrive的空间感知能力。
方法详解
预备知识

基于这些MLLMs,我们提出了MPDrive来增强空间理解能力。为了清晰起见,我们使用单视图场景说明方法,同时注意到所有操作自然扩展到多视图情况。
视觉标记

MPDrive架构
如图2所示,MPDrive由两个关键组件组成:MCNet和PSPL。MCNet通过利用原始图像和额外的视觉标记图像来增强空间表示,从而实现双级融合的场景特征。基于这些提取的特征和检测专家,PSPL生成场景级和实例级的视觉提示,从而增强对驾驶场景信息和目标信息的理解。这些组件的集成显著增强了MPDrive的空间感知能力。
标记控制网络(Marker ControlNet)

感知增强空间提示学习

实验结果分析
实验设置
数据集
我们在DriveLM和CODA-LM数据集上进行实验。对于DriveLM数据集,我们遵循EM-VLM4AD和MiniDrive所采用的数据划分策略,将数据集划分为训练集和验证集,分别分配70%和30%的数据。训练集包含341,353个独特的问答对,而验证集包含18,817个不同的问答对。每个问答对包括六个视角图像:前视图、左前视图、右前视图、后视图、左后视图和右后视图。对于CODA-LM数据集,我们使用包含20,495个问答对的训练集对MPDrive进行训练,并使用一个包含193个问答对的小型集进行验证。每个问答对包括一张前视图图像。
评估指标
为了促进严格和公平的比较,我们采用了与EM-VLM4AD和MiniDrive研究一致的评估指标,包括BLEU-4、ROUGE L、CIDEr和METEOR。这些指标通过重叠、召回率、基于共识的评估和语义相似性来评估预测值与真实值之间的语言一致性,反映了MLLMs的感知、预测和规划能力。此外,根据CVPR 2024自动驾驶挑战赛指南,我们还纳入了额外的性能指标:匹配度和准确性。匹配度指标量化预测中心点坐标与真实值之间的欧几里得距离小于16像素的百分比,为MLLMs的空间信息表达能力提供了直观的验证。准确性评估多选题和是非题的响应正确性,为MLLMs的能力提供全面的评估。
实现细节
在训练阶段,我们采用初始率为5e−4的余弦学习计划,并使用AdamW优化器,权重衰减为0.01。对于DriveLM数据集,我们采用批量大小为128,并在八块A800 GPU上进行3,000次迭代训练,相当于大约1个epoch。对于CODA-LM数据集,我们进行了2000次迭代训练,相当于大约12个epoch。在整个训练过程中,视觉编码器权重保持冻结。我们微调连接的MLP和零MLP,同时对MCNet内的视觉编码器和LLM解码器应用低秩适应(LoRA)。在训练和推理阶段,我们将输入图像分辨率调整为448×448像素。检测到的目标数量K由每个图像的检测专家动态确定,所有摄像机视图的最大限制为100个目标。我们设置了新空间坐标的dth=50。
定量结果
我们在DriveLM数据集上与竞争方法进行了定量评估,以展示MPDrive的有效性,如表1所示。我们提出的方法表现出卓越的性能,特别是在CIDEr和METEOR指标上,分别获得了3.56和38.31的分数。此外,它在BLEU-4中的表现超过了所有单轮推理方法,接近基于图的多轮推理方法(DriveLM-Agent)的性能,表明其在语言一致性方面的优越性能。此外,MPDrive显示出强大的空间感知能力,匹配得分达到13.43,准确率达到85.18,超过了InternVL-2的表现。
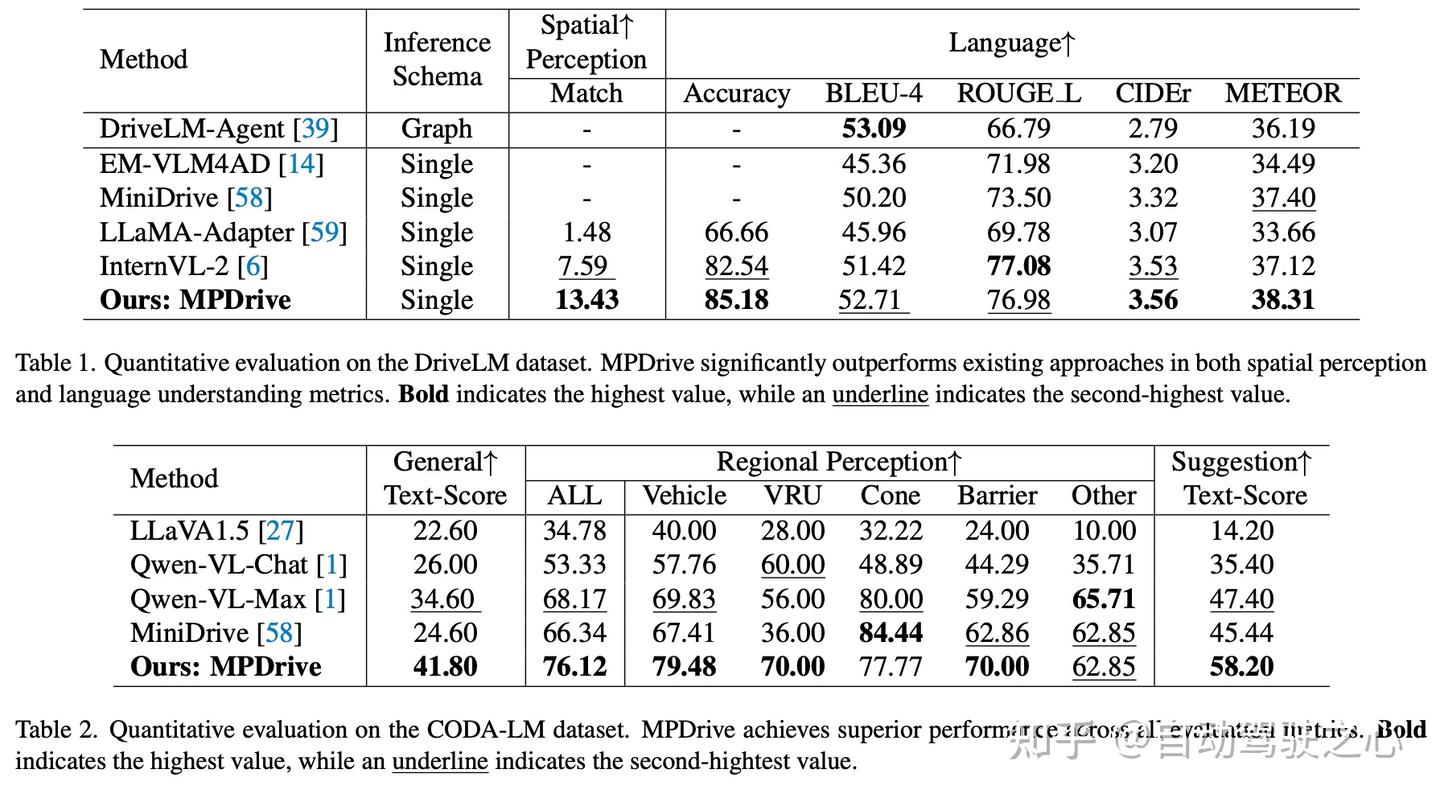
如表2所示,MPDrive在CODA-LM数据集上的各种任务中表现出显著的性能。在一般感知任务中,MPDrive取得了41.80的分数,显著优于其他竞争方法。这表明其在有效感知和解释驾驶场景方面的卓越能力。对于与空间相关的区域感知任务,MPDrive在多个子类别中表现出色。它在车辆类别中获得79.48分,在VRU(弱势道路使用者)类别中获得70.00分,突显了其对空间目标的细粒度感知能力。此外,它在锥形物(77.77)、障碍物(70.00)和其他(62.85)类别中表现良好,突显了其全面的空间理解能力。MPDrive在驾驶建议生成中取得了58.20的最高分,展示了出色的空间意识和规划能力,为有效的驾驶建议提供支持。
这些结果验证了MPDrive在精确空间表达方面的能力,并展示了MPDrive在自动驾驶场景中的增强空间感知能力。
定性示例
在图3中,我们将MPDrive与InternVL-2在未见样本上的实际响应结果进行了比较,评估了MPDrive的空间感知和任务规划能力。在图3的上部样本中,我们显示了最相关图像之一的预测坐标。InternVL-2的预测位于错误区域,而MPDrive定位了重要目标,与真实标注一致。这表明了MPDrive卓越的空间理解能力。

在图3的下部示例中,当被要求识别涉及车辆和行人的危险行为时,InternVL-2错误地得出结论认为与行人没有碰撞风险。相比之下,MPDrive准确评估了车辆与行人之间的空间关系,从而做出正确的规划决策。这表明了MPDrive分析复杂场景并做出精确决策的先进能力,突显了其在自动驾驶应用中的有效性。更多定性示例可以在补充材料中找到。
总之,MPDrive在未见样本上优于InternVL-2,表现出准确的目标定位和可靠的空间关系评估能力,这对于安全的自动驾驶至关重要。
消融研究
在本节中,我们对视觉标记、MCNet和实例级视觉提示进行了消融研究。此外,我们还在不同MLLMs上评估了MPDrive。为了确保公平比较,我们在DriveLM数据集上进行了消融实验,该数据集包括六视角图像并涵盖感知、预测和规划任务,从而便于对自动驾驶场景中的MLLM进行全面评估。此外,DriveLM数据集上的各种评估指标可以从多个角度评估MPDrive的性能。
场景级视觉提示
为了评估场景级视觉提示的有效性,我们对视觉标记和MCNet进行了消融实验。表3展示了场景级提示的消融研究。视觉标记显著提高了空间感知能力,匹配得分从7.59提高到11.89。然而,其对语言指标的影响结果参差不齐。虽然准确性略微下降到80.42,但BLEU-4和METEOR得分的提升表明MPDrive的语言表达一致性有所增强。我们将此性能归因于视觉标记和目标特征在视觉空间中潜在的特征干扰。
通过合并MCNet,大多数衡量语言一致性的指标都有所改善。尽管匹配得分从单独使用视觉标记时的11.89下降到9.70,但模型在BLEU-4(52.56)和METEOR(38.14)得分方面实现了更好的语言质量。这表明MCNet有助于平衡空间信息和语义理解之间的特征表示,尽管牺牲了一些空间感知能力。
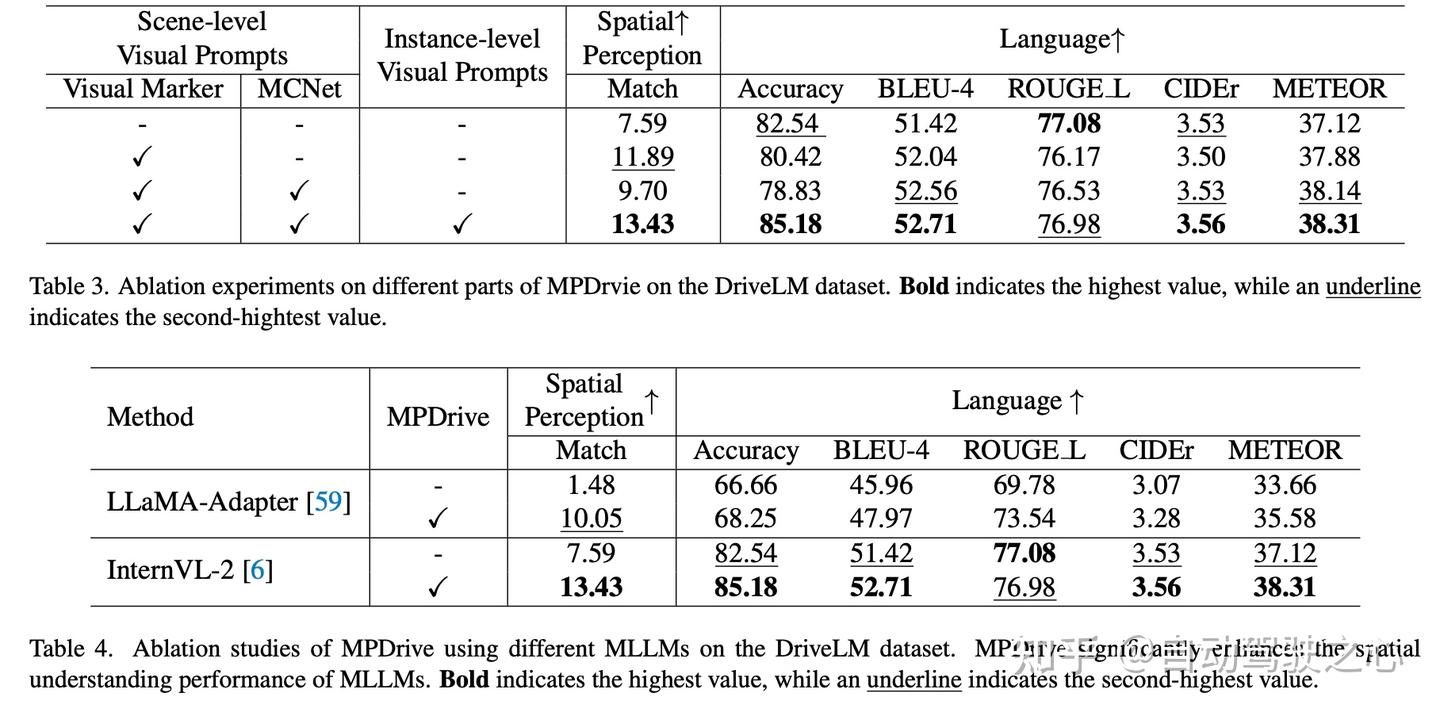
实例级视觉提示
为了评估实例级视觉提示的有效性,我们在保持所有其他设置相同的情况下,进行了有无该组件的对比实验,如表3所示。实例级视觉提示的整合在空间和语言指标上都带来了全面的改进。具体而言,匹配得分进一步增加到13.43,超越了所有先前的配置,而准确性达到了最高的85.18。
此外,语言生成质量持续改善,BLEU-4达到52.71,ROUGE L达到76.98,CIDEr达到3.56,METEOR达到38.31。这些结果表明,实例级视觉提示有效地增强了空间感知和语言理解,表明其在精确文本标记索引预测中的关键作用。
不同MLLMs
为了评估MPDrive的模型无关性,我们将实验扩展到包括LLaMA-Adapter
作为替代MLLM。表4表明,将我们的MPDrive框架应用于LLaMA-Adapter相较于原始LLaMA-Adapter实现带来了显著的性能提升。具体来说,MPDrive(LLaMA-Adapter)实现了显著更高的匹配得分10.05,相比于LLaMA-Adapter的1.48,表明其空间感知能力得到了大幅增强。
在语言生成指标方面,MPDrive(LLaMA-Adapter)在各个方面都优于LLaMA-Adapter:BLEU-4从45.96提高到47.97,ROUGE-L从69.78提高到73.54,CIDEr从3.07上升到3.28,METEOR从33.66提高到35.58。
此外,MPDrive的准确性略高,达到68.25,相比66.66。对比分析表明,MPDrive有效地增强了不同MLLMs的空间理解能力。
结论
我们介绍了一种新颖的基于MLLM的框架,称为MPDrive,用于AD-VQA。MPDrive将复杂的空域坐标生成转化为简洁的视觉标记预测。它结合了MCNet和PSPL以增强场景级和实例级的空间感知能力。MPDrive在使用DriveLM数据集的多视角输入自动驾驶任务以及使用CODA-LM数据集的单视角输入任务中均取得了最先进的性能。
MPDrive依赖于先验专家进行空间感知和语言表达,专家的错误可能会影响其性能。此外,尽管MPDrive增强了AD-VQA的空间感知能力,但长时间跨度的时间感知仍然是自动驾驶中的一个重要挑战。因此,基于MPDrive推进这一研究值得进一步探讨。
发表回复