
原文链接:https://zhuanlan.zhihu.com/p/1895567729823568547
鸟瞰图(BEV)感知作为三维感知任务(如三维目标检测 和 BEV 分割)的基础,对于理解驾驶环境至关重要。准确的空间理解在下游的运动预测和规划中也发挥着关键作用,而BEV 通过为传感器融合提供一个稳健的中间表示,促进了有效的多模态融合。
现有的 BEV 感知
方法大致可以分为两类范式:
- 2D 反投影方法,通过估计深度并将特征反投影到 3D 空间;
- 3D 投影方法,将预定义的 3D 坐标体积投影到相机视图上并聚合图像特征。尽管这些范式取得了显著进展,但它们通常涉及准确度、计算成本和可扩展性之间的权衡,限制了它们在现实场景中的适用性。
3D 投影方法在准确度方面达到了SOTA的水平,然而,它们对 3D 网格的依赖导致了较高的计算成本,使其不太适合实时应用。为了克服这些限制,作者引入了 GaussianLSS,这是一种基于 2D 反投影的方法,通过引入新颖的深度不确定性建模技术,在准确性和效率之间取得了平衡,以满足自动驾驶应用的实时性要求。
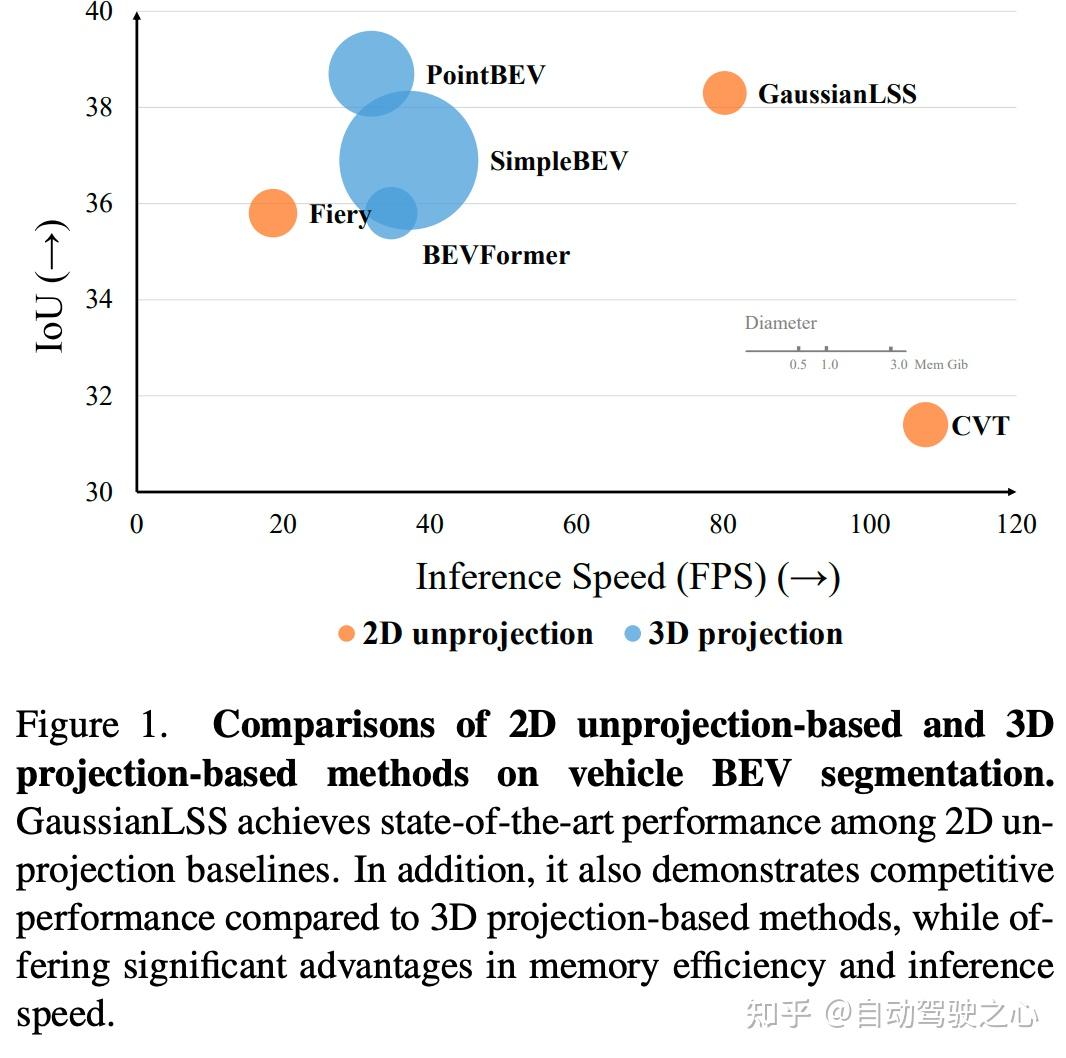
图1展示了 GaussianLSS 推理速度和性能的对比,可以看到作者提出的方法在推理速度和效果上有着非常不错的权衡:
本文的主要贡献如下:
- 引入了 GaussianLSS,这是一种针对 BEV 感知量身定制的新型深度不确定性建模方法,它捕获并利用深度模糊性来改善空间表示。
- 提出了一种计算效率高的方法,将深度不确定性转换为 3D 概率分布,并将其与 Gaussian Splatting
- 无缝集成,以实现快速准确的 BEV 特征聚合。
- GaussianLSS 在 2D 非投影方法中实现了最先进的结果,并且与 3D 投影方法具有竞争力。此外,它还显着减少了内存使用量和推理时间,使其非常适合现实世界的自动驾驶应用。
相关工作
3D 投影的目标检测/分割
3D 投影方法将预定义的 3D 体素点映射到图像平面上以采样特征,消除了对显式深度估计的需求。这种方法通过将特征放置在合理的 3D 位置,绕过了直接深度预测的复杂性。值得关注的工作有,BEVFormer 和 SimpleBEV等,采用网格采样来高效地在 BEV 平面上聚合多视图特征。为了应对网格分辨率的挑战,PointBEV 引入了一种从粗到细的训练策略,从密集网格过渡到稀疏网格,这在保留准确度的同时减少了内存消耗。尽管取得了这些进展,与 2D 反投影方法相比,3D 投影方法仍然计算密集,限制了它们在现实应用中的可扩展性。
隐式 2D 反投影的目标检测/分割
隐式 2D 反投影方法利用基于 Transformer 的架构和 MLP,从 2D 图像到 3D 空间进行学习映射,而无需显式预测深度。这些方法侧重于通过在交叉注意力框架中整合 BEV 网格查询和相机感知位置嵌入,隐式地学习空间关系和深度线索。然而,由于投影是隐式的,这些方法在处理深度模糊性时面临挑战。另外,随着 BEV 网格和图像分辨率的增加,它们的计算复杂度显著增加,使其在高分辨率应用中效率较低且可扩展性较差。这些限制限制了它们在需要精确空间表示的详细场景中的实用性。
显式 2D 反投影的目标检测/分割
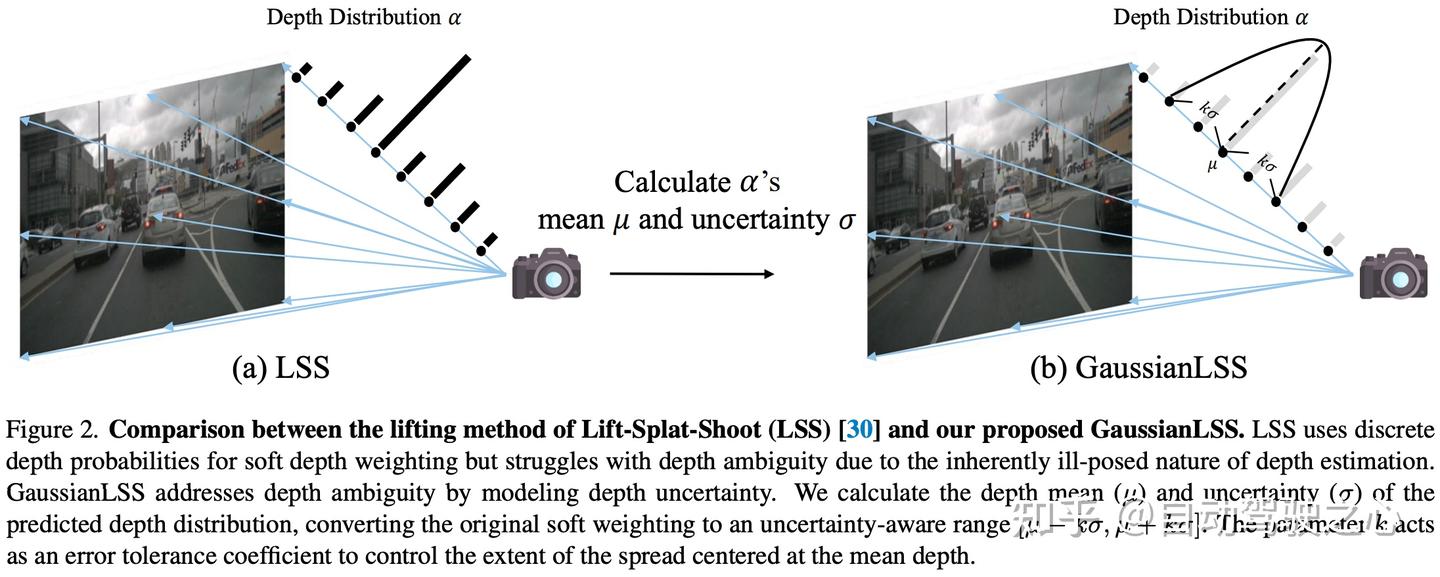
Lift-Splat-Shoot (LSS) 引入了一个高效的流程,将 2D 特征提升到 3D,这一设计已成为 3D 感知任务的基础。这种方法严重依赖于准确的深度估计,这使得它对深度预测误差敏感,这些误差可能会传播到 BEV 表示中。为了缓解这一问题,后续工作增加了深度监督作为辅助损失,以提高深度准确性。尽管这些方法使用概率深度分布来软性提升特征,但它们通常缺乏对深度不确定性的显式表示。这一限制阻碍了它们在复杂场景中有效处理深度模糊性的能力。GaussianLSS 通过将深度不确定性显式建模为概率分布的方差来解决这一问题。这种不确定性感知的深度表示减少了对精确深度估计的依赖,允许模型捕捉围绕深度均值的可变空间范围,见图2。
不确定性建模
不确定性建模是一种广泛采用的方法,用于捕捉计算机视觉任务中的模糊性,应用领域包括语义分割、单目深度估计和新视图合成。估计不确定性的常见方法包括:
- 预测分布的方差:基于预测概率分布的方差来衡量不确定性,直接表明对输出的置信度。
- 基于 MLP 的不确定性估计:使用多层感知器(MLP)输出单个不确定性分数或预测由均值和方差描述的分布,其中方差作为不确定性度量。
- 贝叶斯网络:引入概率先验分布,以原理性框架对不确定性进行建模。
这些方法各自提供了独特的不确定性建模方式,支持在各种场景中进行更稳健的预测。在作者的工作中,作者通过关注深度分布的方差来采用不确定性建模,利用它增强 BEV 分割性能,特别是在存在深度模糊性的情况下。
GaussianLSS 模型
作者的目标是将深度不确定性建模整合到 BEV 表示流程中,以应对现实场景中的深度模糊性挑战。GaussianLSS 的概述如图 3 所示。
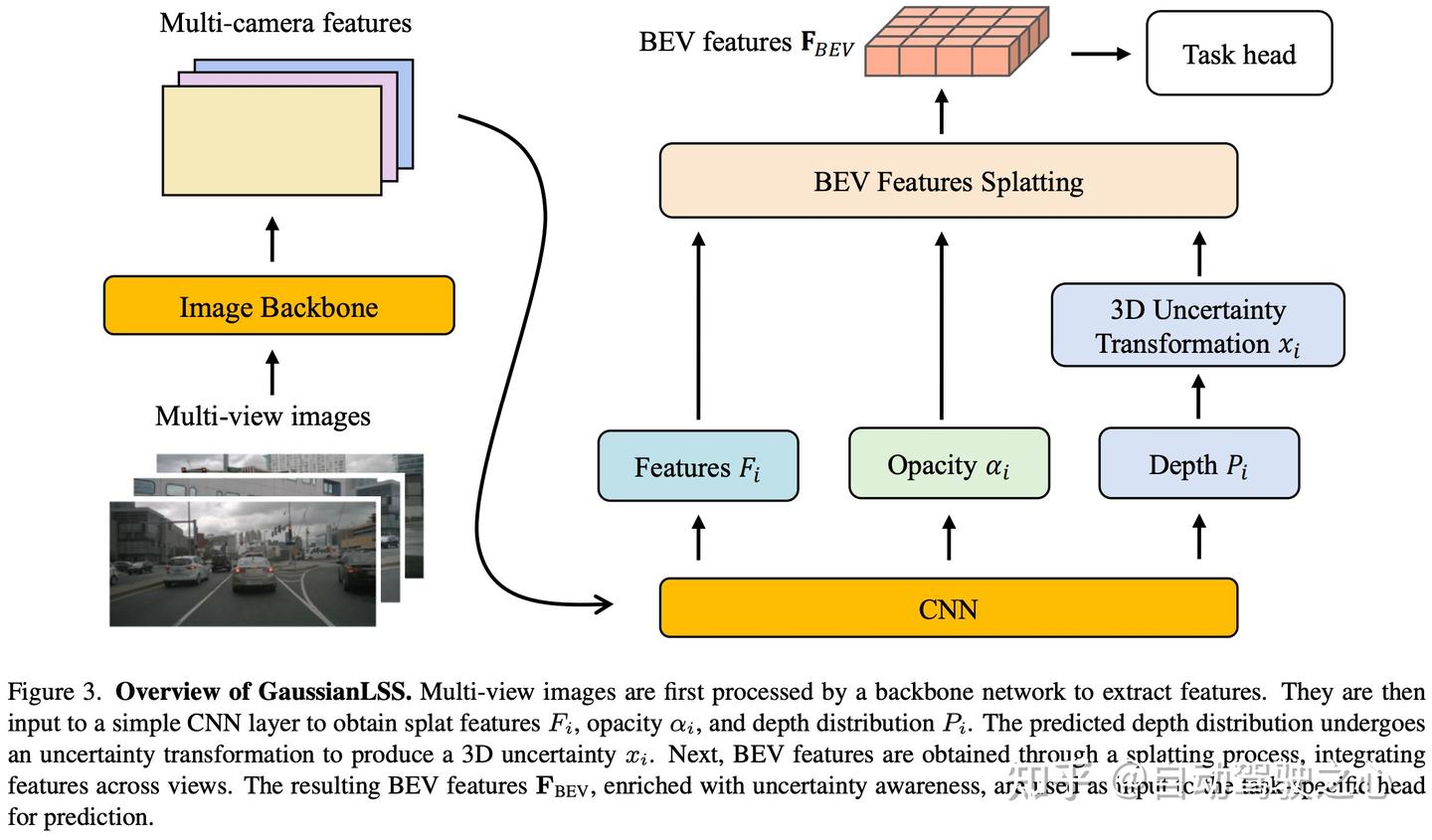
GaussianLSS 首先预测每个像素的深度分布,提供相应深度不确定性的估计。利用相机的投影矩阵,作者定义了一个相机视锥空间,将这种深度不确定性转换为由均值和协方差矩阵表示的 3D 分布。为了实现高效的 BEV 特征绘制,作者在 3D 高斯表示中引入了一个不透明度参数,从而可以使用高斯绘制光栅化。然而,作者观察到由于相邻像素之间深度均值不一致,BEV 特征可能会出现失真。为了解决这一问题,作者采用了多尺度 BEV 渲染方法。
深度不确定度建模
作者首先回顾开创性工作 Lift-Splat-Shoot。它首先将深度范围 [d_min, d_max] 离散化为 B 个箱子。这创建了一个离散深度集合 D:




实验及结果
作者在 nuScenes 数据集
上评估了 GaussianLSS。
与现存方案的对比
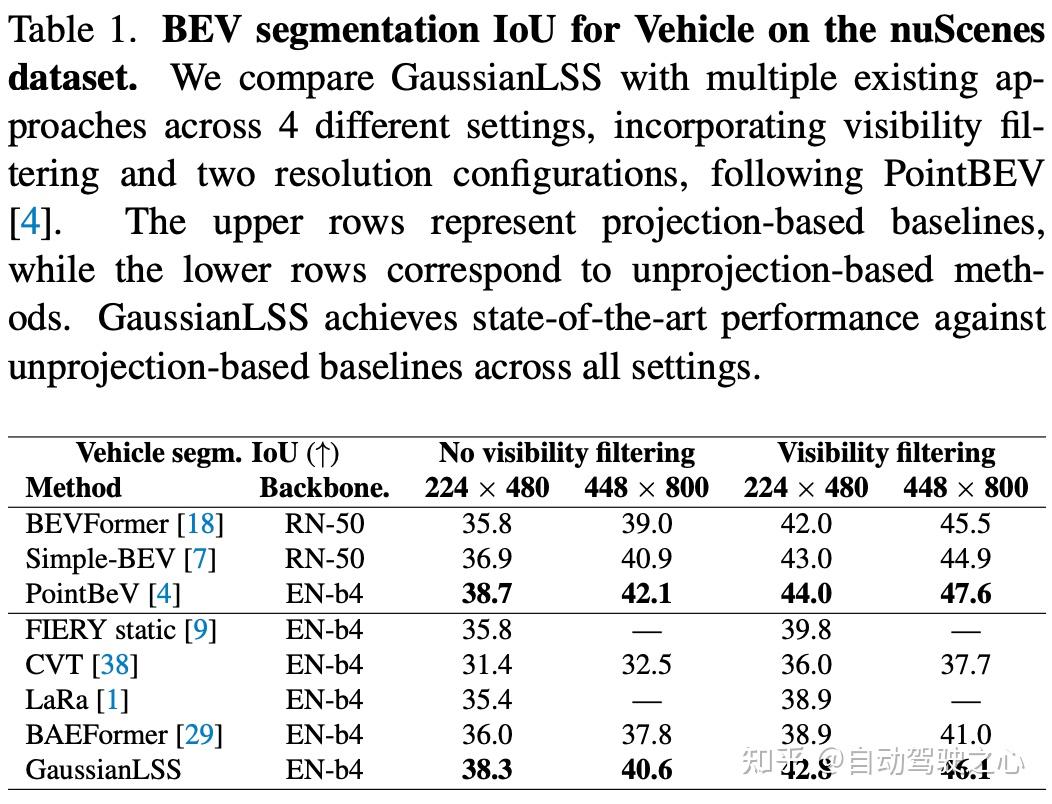
作者将 GaussianLSS 与基于反投影和投影的方法进行了比较。如表 1 所示,GaussianLSS 在所有基于反投影的方法中表现最佳,并且与基于投影的方法相比具有相当的性能。作者观察到,即使使用多尺度渲染,GaussianLSS 在预测对象形状方面仍然比基于投影的方法差,但能够捕捉到更远距离的对象。
此外,表 2 比较了行人类别分割,而表 3 显示了推理速度和内存消耗。GaussianLSS 实现了 80.2 FPS,比 PointBEV 快 2.5 倍,展示了其效率。除了列出的任务外,作者还在其他应用中评估了 GaussianLSS,包括地图分割和 3D 目标检测。这些结果进一步验证了 GaussianLSS 在不同任务中的多功能性,显示了不确定性表示的有效性。

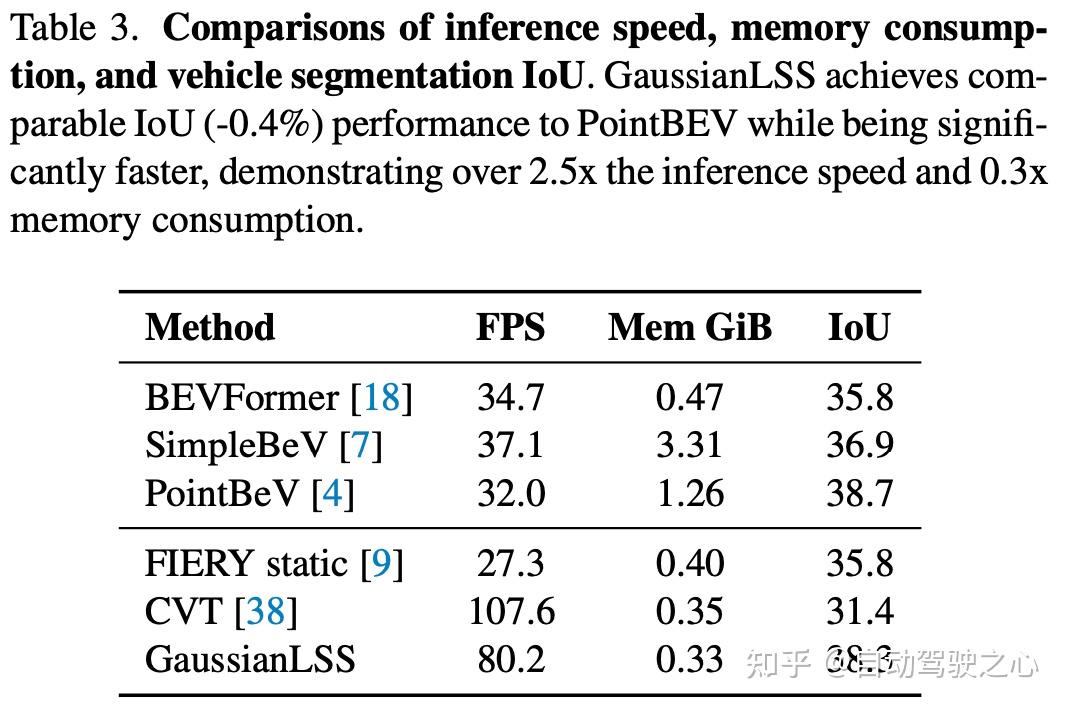
误差容差系的消融实验
误差容差系数 k 是作者不确定性建模方法中的一个关键参数。它通过控制围绕每个 3D 点的椭球体的大小,定义了 3D 不确定性表示的空间范围。较小的 k 限制了绘制到高置信度区域,但可能会忽略物体的有效范围;而较大的 k 虽然纳入了更多的不确定区域,但以牺牲精度为代价。这种平衡对于有效的 BEV 特征表示至关重要。
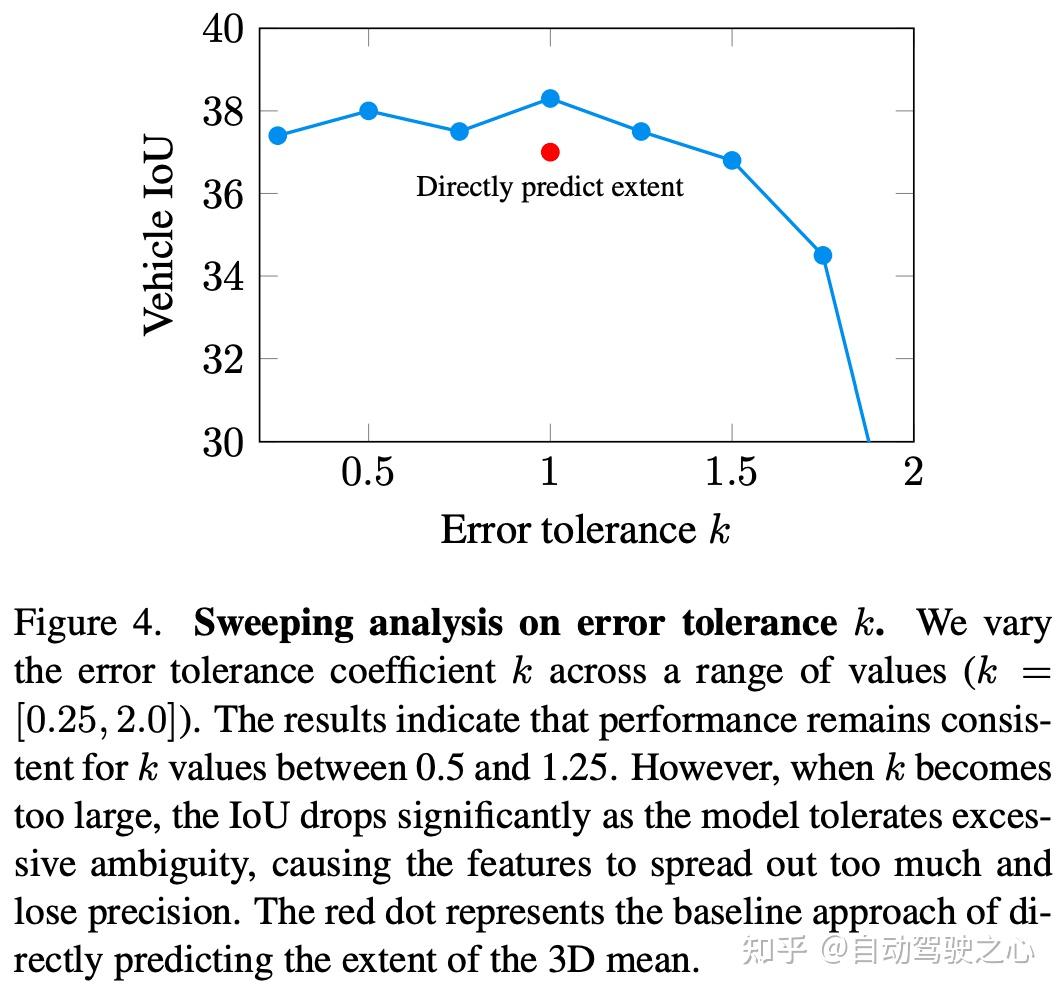
分析结果如图 4 所示。另一方面,作者也尝试直接预测一个固定的范围,而不是建模不确定性。通过比较这两种方法,作者旨在突出将不确定性纳入 BEV 特征提取过程的优势,因为直接预测范围会导致性能降低 1.3%。
深度不确定度分析
作者评估了 GaussianLSS 在不同距离上从自车的性能,重点关注其准确表示远距离物体的能力。为此,作者通过排除距离自车一定近邻阈值内的预测来计算 IoU。图 6 比较了 GaussianLSS 与基于投影的最先进方法 PointBEV。两种模型都表现出随着距离增加而准确度下降的相似趋势,这是由于深度模糊性增加所致。
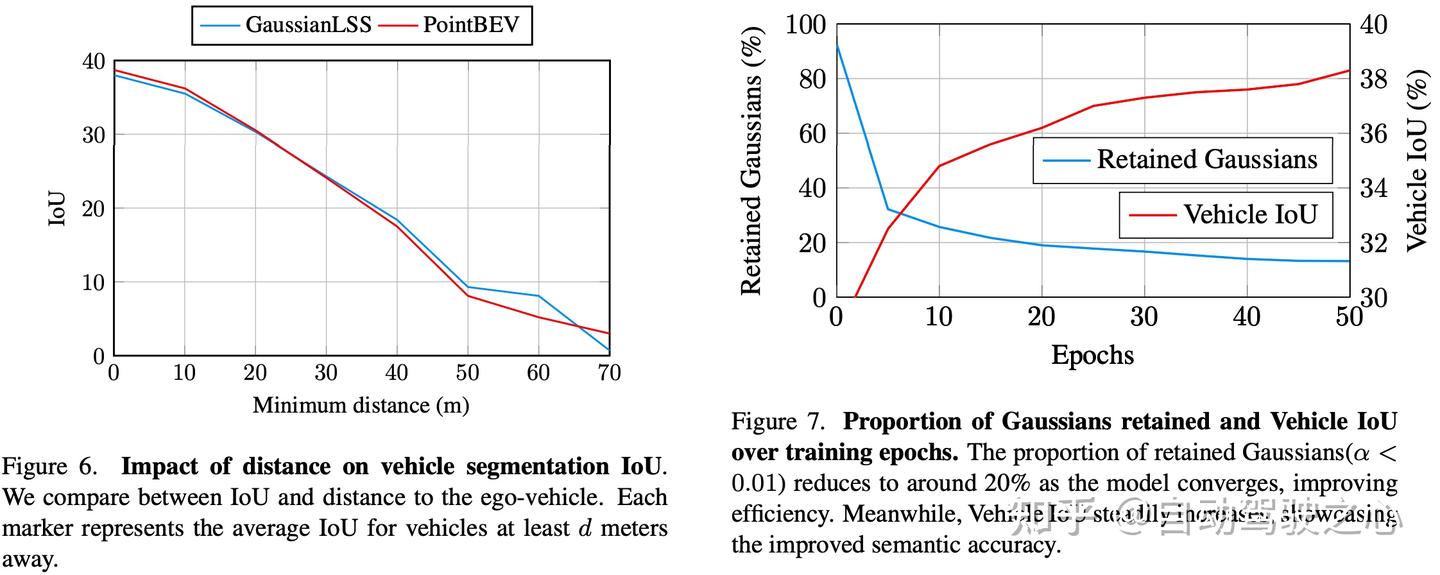
然而,GaussianLSS 在处理远距离物体方面表现出优势。通过显式建模和利用深度不确定性,GaussianLSS 在超过 30 米的距离上提供了更准确的对象表示。当最大深度设置为 61 米时,性能降至零。
特征渲染中的不透明度
特征渲染中的不透明度可以被视为一种加权求和机制,引导模型关注语义相关区域。高不透明度区域代表置信度高、贡献大的特征,而低不透明度区域则被弱化或可以过滤掉以提高效率。经验表明,在训练后,80% 的高斯分布的不透明度低于 0.01,突出了模型在识别和将关键区域投影到 BEV 空间方面的效率,如图 7 所示。
定性结果分析
作者在图 5 中展示了定性结果。黄色区域表示在特征提升过程中由于低不透明度值而被屏蔽的区域,确保模型专注于语义重要的特征。GaussianLSS 即使在存在遮挡和杂乱的复杂城市场景中,也能捕捉到关键区域,如车辆。这突出了 GaussianLSS 在学习有意义的特征的同时过滤不相关区域的有效性,从而实现准确且高效的 BEV 表示。
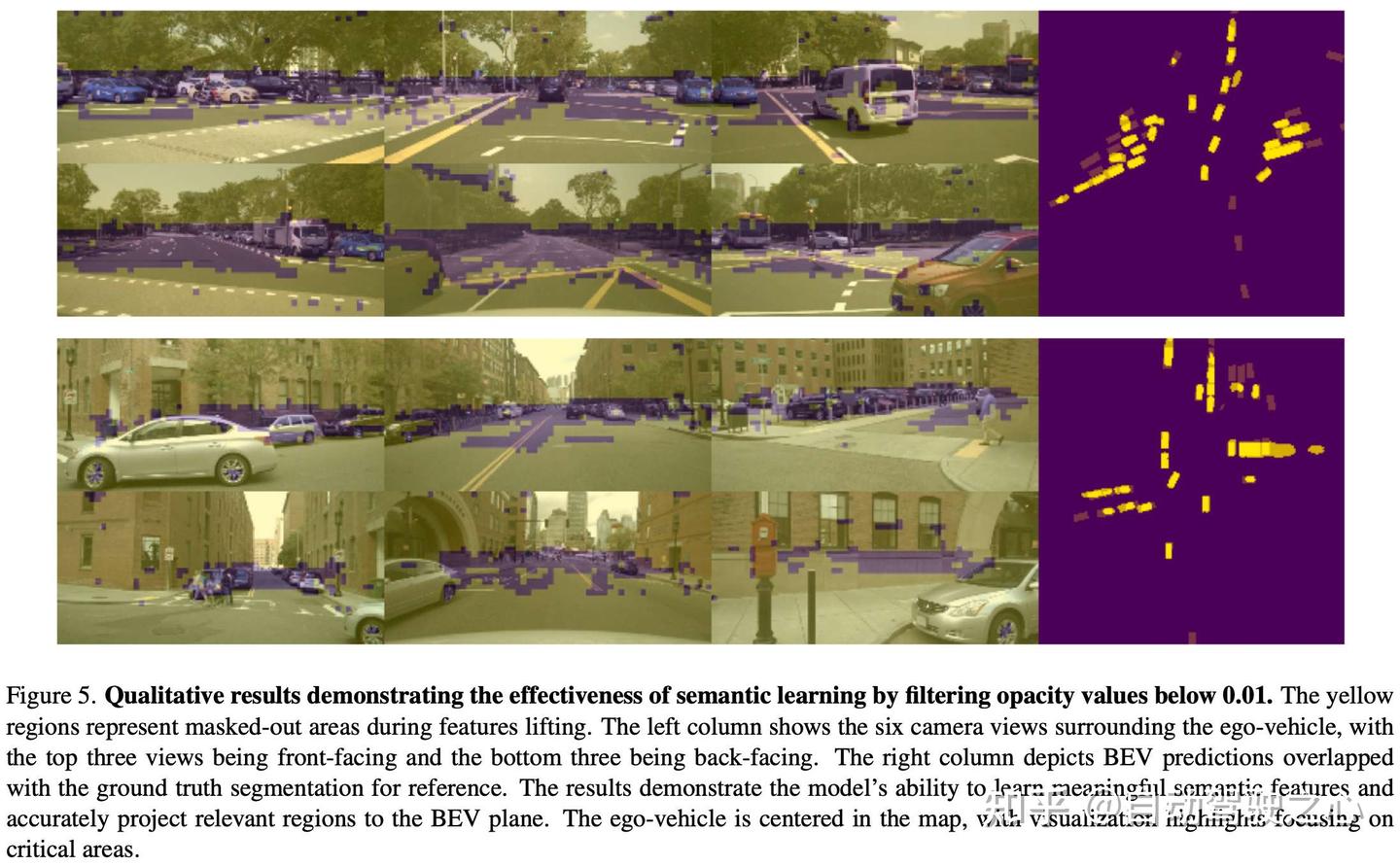
图 8 展示了模型在长距离感知方面的鲁棒性,涵盖了 8 种不同场景。作者可视化了在 BEV 平面上绘制后的不确定性感知特征。尽管长距离感知存在固有挑战,包括深度模糊性增加,GaussianLSS 利用不确定性感知特征专注于感兴趣区域,同时保持 BEV 投影的准确性。

总结
作者提出了 GaussianLSS,这是一种新颖的 BEV 感知方法,它将深度不确定性建模与高效的多尺度 BEV 特征渲染相结合。通过将每个像素的深度不确定性转换为 3D 高斯表示,GaussianLSS 有效地解决了深度模糊性的固有挑战,同时实现了将特征稳健且准确地投影到 BEV 空间中。作者在基于反投影的方法中实现了最先进的性能,并且在显著降低内存使用量和推理时间方面表现出色,使其非常适合用于现实世界的自动驾驶应用。
发表回复