
原文链接:https://zhuanlan.zhihu.com/p/1895194247860314525
0. 论文信息
标题:Detect Anything 3D in the Wild
作者:Hanxue Zhang, Haoran Jiang, Qingsong Yao, Yanan Sun, Renrui Zhang, Hao Zhao, Hongyang Li, Hongzi Zhu, Zetong Yang
机构:OpenDriveLab at Shanghai AI Laboratory、Shanghai Jiao Tong University、Fudan University、Stanford University、CUHK MMLab、Tsinghua University
、GAC R&D Center
原文链接:https://arxiv.org/abs/2504.07958
官方主页:https://jjxjiaxue.github.io/DetAny3D/
1. 导读
尽管深度学习在近距离3D对象检测中取得了成功,但现有方法难以零镜头推广到新的对象和相机配置。我们介绍了DetAny3D,这是一个可升级的3D检测基础模型,能够在任意相机配置下仅使用单目输入检测任何新对象。为3D检测训练基础模型从根本上受到带注释的3D数据的有限可用性的约束,这促使DetAny3D利用广泛预训练的2D基础模型中嵌入的丰富先验知识来弥补这种不足。为了有效地将2D知识转移到3D,DetAny3D整合了两个核心模块:2D聚合器,它将来自不同2D基金会模型的特征进行排列,以及具有零嵌入映射的3D解释器,它可以减轻2D到3D知识转移中的灾难性遗忘。实验结果验证了我们的DetAny3D的强泛化能力,它不仅在看不见的类别和新颖的相机配置上实现了最先进的性能,而且在域内数据上超过了大多数竞争对手。DetAny3D揭示了3D基础模型在现实世界场景中各种应用的潜力,例如自动驾驶中的稀有物体检测,并展示了在开放世界环境中进一步探索以3D为中心的任务的前景。更多可视化结果可以在DetAny3D项目页面找到。
原文:通往开放世界的大门,DetAny3D:3D检测一切!(上交 & 复旦 & 清华重磅新作)
2. 效果展示
DetAny3D,一个可提示的3D检测基础模型,能够检测任何3D物体,具有任意单目图像,在各种场景中。我们的框架支持多提示交互(如框、点和文本),以提供开放世界3D检测结果(厘米x厘米x厘米),适用于各种领域的新物体。它在零样本泛化方面取得了显著成果,在新类别和新数据集上优于SOTA高达21.02和5.68AP3D,并且具有新的相机配置。

通过Sora的零样本传输视频生成。我们为Sora提供网络图片。如图所示,当使用三维限界框控制时,Sora可以更好地捕捉场景的几何关系。与此相反,仅由2D限界框提示控制,Sora尊重像素级的空间线索,但未能产生准确的几何偏移。

我们展示了来自开放世界检测的定性示例。在每一对图像中,顶部行由OVMono3D生成,底部行由DetAny3D生成。对于每个示例,左侧子图叠加了投影的3D边界框,而右侧子图显示了相应的鸟瞰视图,背景为lmx1m网格。

3. 引言
3D目标检测是自主系统、机器人技术和增强现实的基础技术。3D感知不仅使机器能够感知并与物理世界交互,还为更高级任务提供基础输入,例如行为决策、世界建模和3D场景重建。对于实际部署,理想的通用3D检测器应能从单目图像等易获取输入中检测任意物体,且不依赖特定传感器参数。这种模型将在多样且不可预测的环境中,对各种下游任务表现出高度适应性和可靠性。此外,此类检测器提供的精确检测结果(例如为互联网图像生成3D边界框)使其成为多功能工具,为利用互联网级数据并迈向开放世界场景的扩展3D系统奠定基础。推荐课程:卡尔曼滤波及其在多传感器融合的应用[PX4 EKF2讲解]。
先前研究(如Omni3D)尝试通过多数据集训练提升3D检测系统的泛化性。然而,尽管使用大型数据集训练统一检测器,这些方法对新相机配置和预定义标签空间外的未见物体类别泛化能力有限。因此,开发具有强零样本泛化能力的3D检测基础模型,使其能在任意相机配置下检测任意未见物体,仍是关键未解问题。
近期2D基础模型的进展展现了卓越的零样本能力。分段任意模型(SAM
)具有可提示推理机制,支持点和框等用户友好提示来分割指定物体。其强大的泛化能力源于数十亿标注图像的训练。然而,在3D目标检测领域,标注数据仅数百万样本——比2D图像小3-4个数量级。这种严重的数据稀缺性构成根本挑战,几乎无法从头训练3D基础模型。
本文提出DetAny3D,一种专为通用3D目标检测设计的可提示3D检测基础模型,仅需单目图像作为输入。针对3D标注数据稀缺问题,我们从模型架构和数据利用两个关键维度实现强泛化:核心思想是利用两个大规模预训练的2D基础模型(SAM和DINO
)编码的丰富先验知识,从而以最小3D数据解锁有效的零样本3D检测能力。
具体而言,我们采用SAM作为可提示骨干网络,利用其从大规模2D数据获得的多功能鲁棒物体理解能力。同时,利用UniDepth深度预训练的DINO提供冗余3D几何先验,这对单目设置下的精确3D检测至关重要。为有效整合SAM和DINO的互补特征,我们提出基于注意力的2D聚合器(2D Aggregator),通过可学习门控机制对齐特征并动态优化贡献度,充分发掘各基础模型的优势。
为进一步解决从2D到3D的知识迁移挑战,我们引入3D解释器(3D Interpreter)。其核心是零嵌入映射(ZEM)机制,可缓解跨域学习中常见的灾难性遗忘问题。通过在不同相机参数、场景复杂度和深度分布的多样数据集上稳定训练过程,ZEM机制使模型逐步获得零样本3D定位能力,显著提升泛化性。
为充分利用3D相关数据,我们聚合了包含16个数据集的DA3D数据集
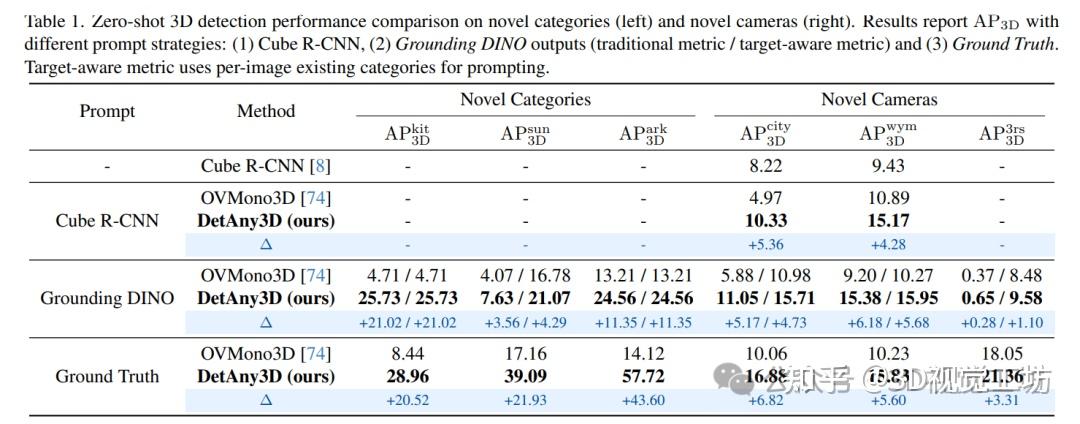
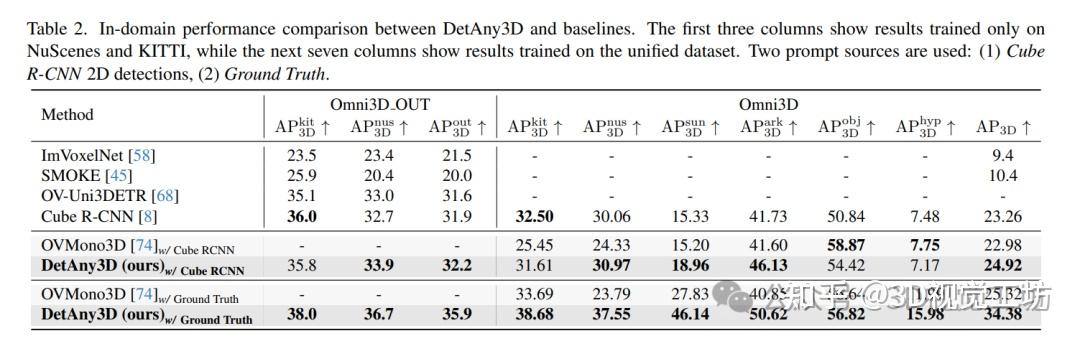
,涵盖深度本征数据和3D检测数据。实验结果表明,使用与基线对齐的提示时,DetAny3D展现三大优势:(1) 对新类别的泛化:在KITTI、SUNRGBD和ARKitScenes的未见类别上,零样本AP3D分别比基线高21.0%、4.3%、11.3%;(2) 对新相机的泛化:在零样本数据集Cityscapes3D、Waymo和3RScan上,AP3D相比基线方法分别提升4.7%、5.7%和1.1%;(3) 域内数据性能:在Omni3D上AP3D超过基线1.6%。
4. 主要贡献
核心贡献总结如下:
• 开发DetAny3D,一种可提示的3D检测基础模型,能够利用任意单目输入检测真实场景中的任意3D物体。
• DetAny3D引入2D聚合器,有效融合来自两个2D基础模型(SAM和深度预训练DINO)的特征,分别为各类物体提供关键形状和3D几何先验。
• 在2D到3D知识迁移中,DetAny3D在3D解释器中引入零嵌入映射,解决灾难性遗忘困境,使模型能在不同相机参数、多变场景和深度分布的数据集上稳定训练。
• 实验结果证明DetAny3D的显著优势,尤其在零样本设置下精确检测具有任意相机参数的未见3D物体,展现其在广泛实际应用中的潜力。
5. 方法
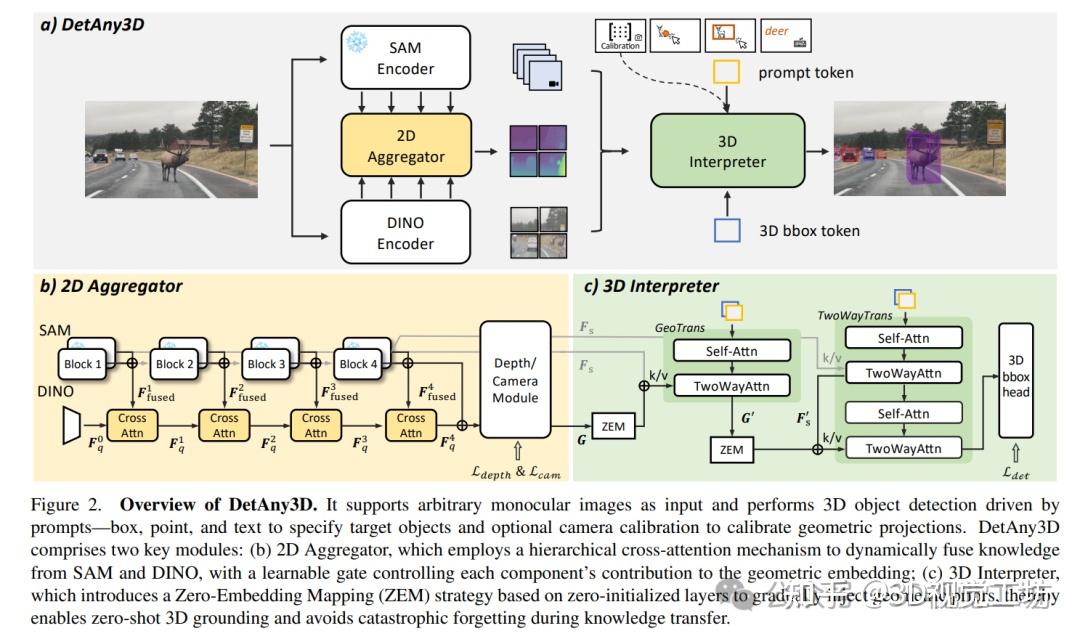
如图2(a)所示,DetAny3D接受单目RGB图像和提示(如框、点、文本、本征参数)作为输入。框、点和文本提示用于指定物体,本征参数提示为可选。未提供时,模型预测本征参数及对应3D检测结果;若可用,则作为几何约束缓解单目深度估计的不适定性并校准检测结果。
具体而言,单目图像并行输入两个基础模型:SAM提取底层像素信息,支撑整个可提示架构;深度预训练DINO提供丰富高层几何知识,擅长深度相关任务。这些互补的2D特征通过提出的2D聚合器(图2(b))融合,该聚合器使用交叉注意力层分层对齐底层和高层信息。融合后的特征传入深度/相机模块,提取相机嵌入和相机感知深度嵌入(统称几何嵌入)。几何嵌入与编码提示令牌的3D边界框令牌共同输入3D解释器(图2(c)),其采用类似SAM解码器的结构并结合专用零嵌入映射(ZEM)机制。3D解释器在注入3D几何特征的同时,防止2D到3D知识迁移中的灾难性遗忘,实现渐进式3D定位。最终,模型基于3D框令牌的隐藏状态预测3D框。DetAny3D在选定可见类别上训练,能以零样本方式检测任意未见类别。
6. 实验结果
7. 总结
我们提出DetAny3D,这是一种可提示的3D检测基础模型,能够从任意单目图像输入中检测任意3D对象。DetAny3D在多样化领域展现出显著的零样本检测能力,并在各种任务中实现了有效的零样本迁移,凸显了其在动态和非结构化环境中进行真实世界部署的适用性。此外,其灵活且稳健的检测能力为收集大规模、多源数据以支持更多3D感知引导的任务打开了大门,为通向开放世界系统铺平了道路。
发表回复